- The paper demonstrates that Llama3-8B outperforms Mistral 8x7B in metrics like contextual precision and answer relevancy.
- It employs a hybrid retriever ensemble using FAISS and BM25, optimizing performance on enterprise-specific datasets.
- The study highlights cost-efficiency and reduced inference times, positioning open-source LLMs as viable alternatives to proprietary models.
Evaluating the Efficacy of Open-Source LLMs in Enterprise-Specific RAG Systems
Introduction
The study evaluates the performance of open-source LLMs within enterprise-specific Retrieval-Augmented Generation (RAG) systems. The aim is to provide a comparative analysis of different open-source LLMs in handling RAG tasks using enterprise-specific datasets, especially when considering factors such as accuracy and efficiency compared to proprietary models. Notably, the work investigates models like Llama3-8B and Mistral 8x7B, which are primarily assessed against the backdrop of being a cost-effective alternative to commercial solutions such as GPT-3.5.
Methodology
Data Collection
Data was collected from the enterprise site "i-venture.org" through web scraping, which involved parsing the site's sitemap and subsequent crawling to extract relevant content. This approach ensured a comprehensive acquisition of data critical for RAG tasks.
Text Preprocessing
The data was split into textual chunks using the NLTKTextSplitter and RecursiveCharacterTextSplitter methods. This splitting was crucial as it optimized the retrieval component by ensuring that each segment precisely aligns with queries for efficient processing.
Embedding and Vector Database
Embeddings were generated using models from Hugging Face, with a focus on BAAI/bge-large-en-v1.5 for their known performance in semantic search contexts. These embeddings were stored in a FAISS vector database, which facilitated rapid similarity searches.
LLM Integration and RAG Implementation
LLMs were integrated using APIs from Perplexity, which interact with models like Llama3-8B and Mistral 8x7B. The hybrid retriever ensemble combining FAISS and BM25 retrieval algorithms was central to the RAG framework, ensuring enhanced retrieval accuracy and contextual relevance.
Evaluation Metrics
The evaluation consisted of comparing the cosine similarity of generated answers with ground truth answers and employing the DeepEval metrics—namely, contextual precision, recall, relevancy, and answer relevancy—to comprehensively measure performance.
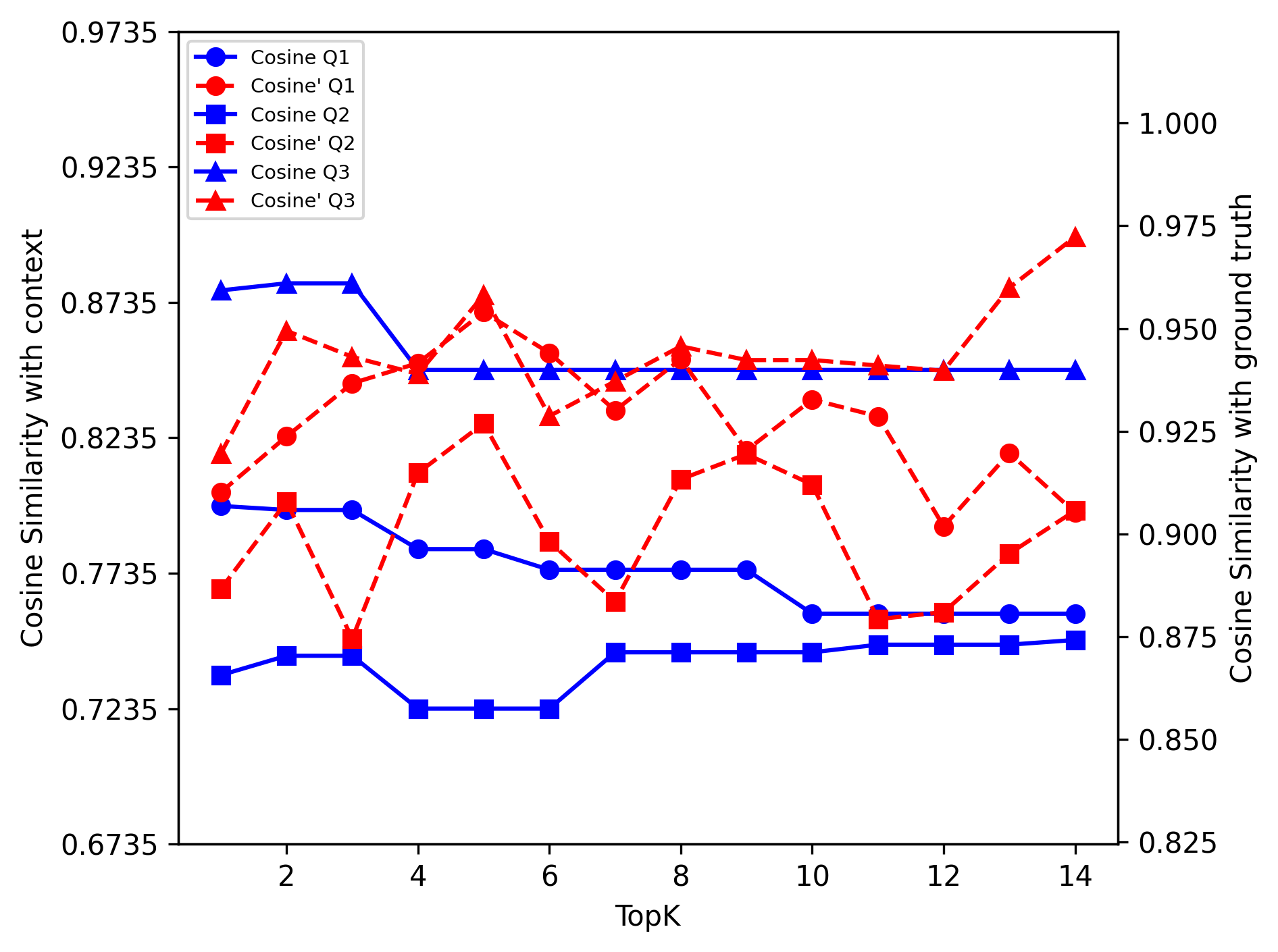
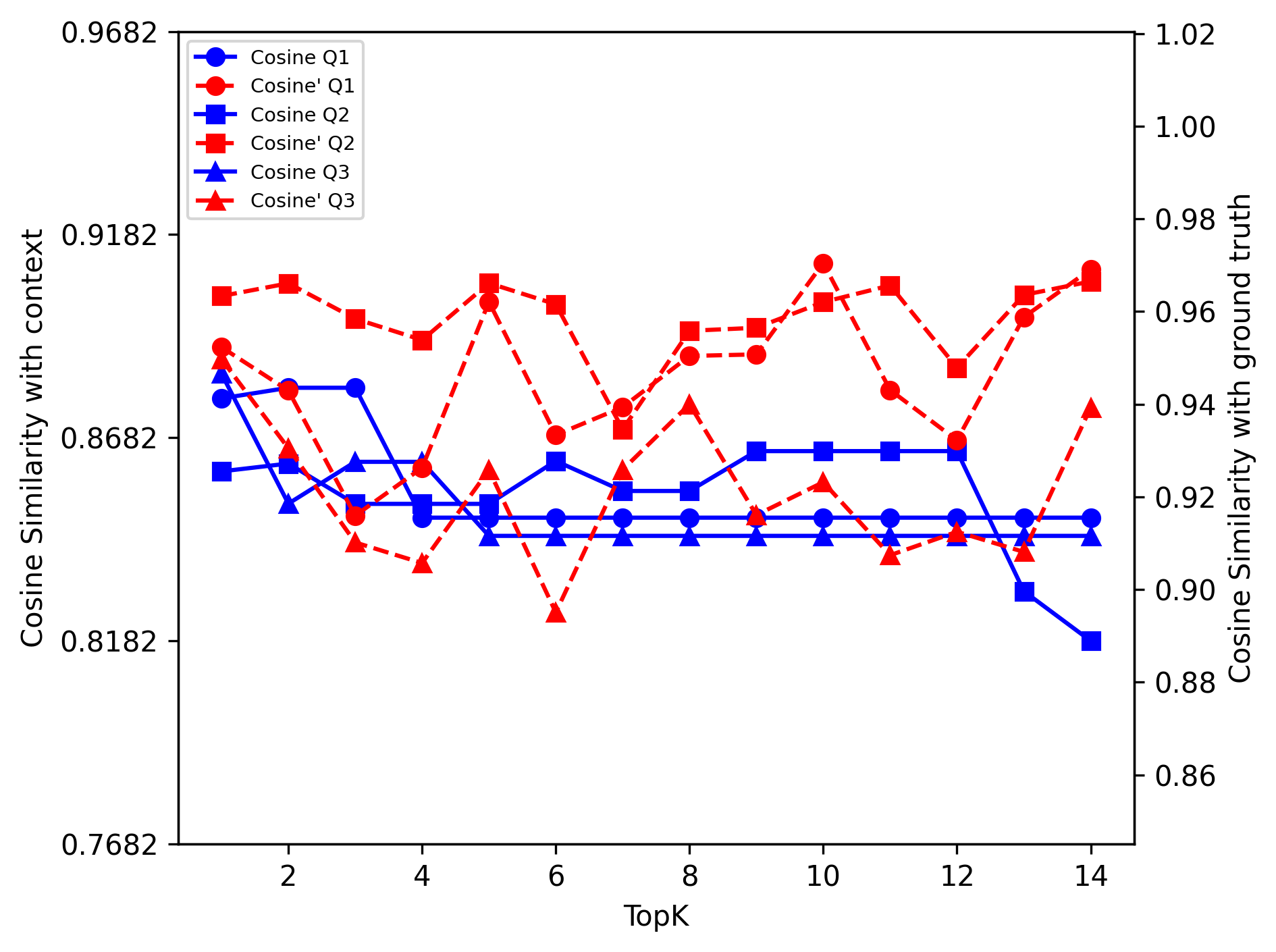
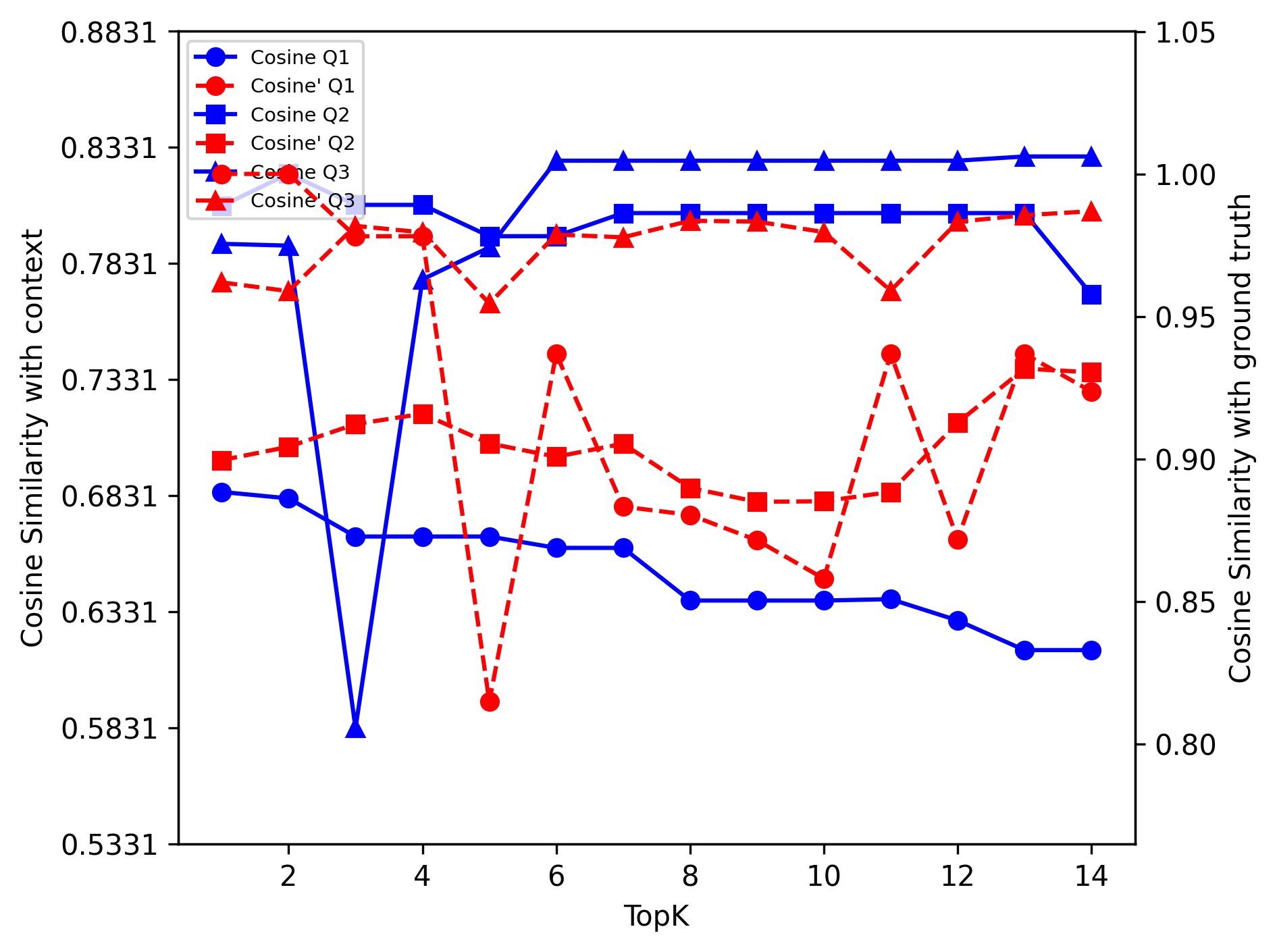
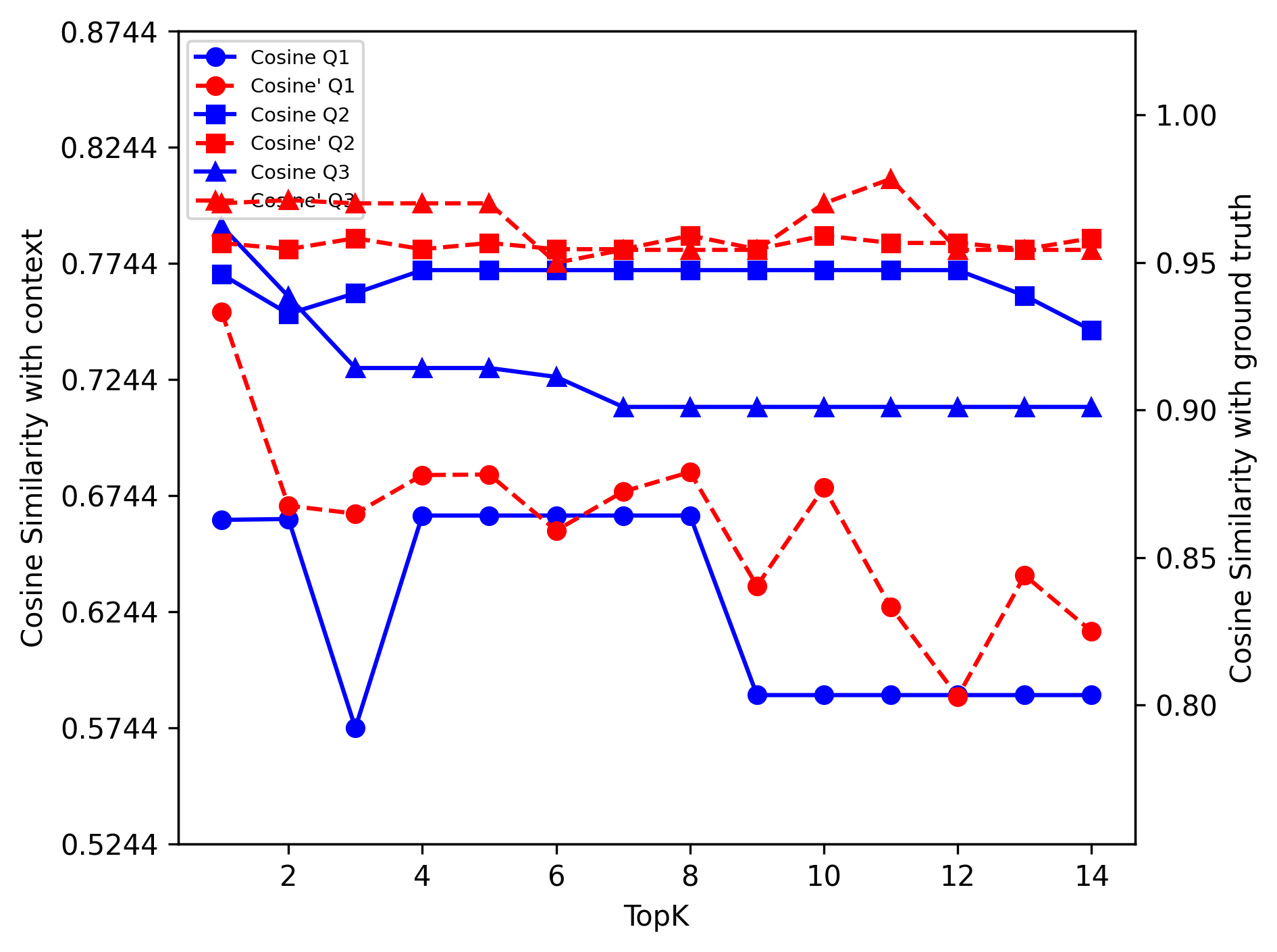
Figure 1: Mistral: Reason Dense
Results
The key findings indicate that Llama3-8B consistently outperformed Mistral 8x7B across all relevant metrics such as unigram precision, contextual precision, and answer relevancy. Notably, Llama3 demonstrated superior usage of contextual information and maintained high precision with reduced inference times.
Cosine Similarity
The analysis showed that increasing top-k values led to diminishing returns in cosine similarity for both LLM models. This indicates a ceiling effect where additional retrieved documents no longer contribute significantly to improving answer accuracy.
DeepEval Metrics
Evaluation using the DeepEval framework showed that the Llama3-8B model also excelled in contextual metrics, highlighting its robustness and flexibility in enterprise-specific RAG tasks relative to Mistral 8x7B.
Figure 2: Histogram of inference time using GPT 3.5: Average response time 4.3 seconds
Discussion
The study delineates that open-source models, particularly Llama3-8B, provide viable performance comparable to proprietary algorithms with significant cost-efficiency benefits. The observed performance of Llama3-8B negates the assumption that more parameters (as seen in Mistral 8x7B) automatically deliver better RAG performance. Furthermore, the consistent performance across varying question densities underscores Llama3’s adaptability to multifaceted AI tasks.
Figure 3: Mistral: Reason Dense
Conclusion
In conclusion, the Llama3-8B serves as a commendable open-source alternative for enterprises aiming to implement cost-effective and efficient RAG systems. This research illuminates the potential of accessible technologies in enhancing enterprise-specific NLP tasks and further provides a foundation for developing open-source LLMs in proprietary contexts. The work encourages further exploration into optimizing hybrid retrieval methods and refining real-time inference capabilities to improve overall system performance.
Through extensive metric analysis and comparative evaluations, the study reaffirms the efficacy of leveraging open-source tools in enterprise AI applications, thereby setting precedence for future innovations in this domain.

