- The paper demonstrates that integrating a business context document significantly boosts SQL query pass rates from 8.3% to over 78% compared to using only a database schema.
- It leverages GPT-4 in a retrieval-augmented generation framework to translate natural language queries into context-aware and syntactically accurate SQL commands.
- The study highlights that context enrichment in LLM-based query generation democratizes pharmacovigilance data access and improves drug safety reporting.
Automating Pharmacovigilance Evidence Generation with LLMs
This paper explores the application of LLMs to automate SQL query generation for pharmacovigilance (PV) databases, aiming to democratize data access for non-technical users. The authors leverage OpenAI's GPT-4 within a retrieval-augmented generation (RAG) framework, enhanced by a business context document, to improve the accuracy and relevance of generated SQL queries. The study demonstrates the potential of this approach to streamline PV data analysis and enhance drug safety reporting.
Background and Motivation
The introduction highlights the critical role of pharmacovigilance in monitoring drug safety and the challenges associated with querying complex PV databases. The authors note that generating precise SQL queries requires specialized expertise, which can limit broader access to safety data. They reference prior work demonstrating errors in SQL application, especially in healthcare [Sivarajkumar 2024] and emphasize the need for improved query generation methods. The paper builds upon the progress of LLMs in text-to-SQL generation, as well as their own prior research using a RAG framework with a Chat-GPT interface [PainterLLM 2023]. The authors posit that by providing LLMs with plain language summaries of expert knowledge, they can significantly improve query accuracy over methods relying solely on database schemas.
Methods and Experimental Design
The authors conducted a three-phased experimental study to evaluate the performance of the LLM in generating SQL queries under different conditions of database knowledge provision.
- Phase 1: Established baseline performance by providing the LLM with a comprehensive 290-page PDF containing the entire database schema, including table and column definitions and database comments. (Figure 1)
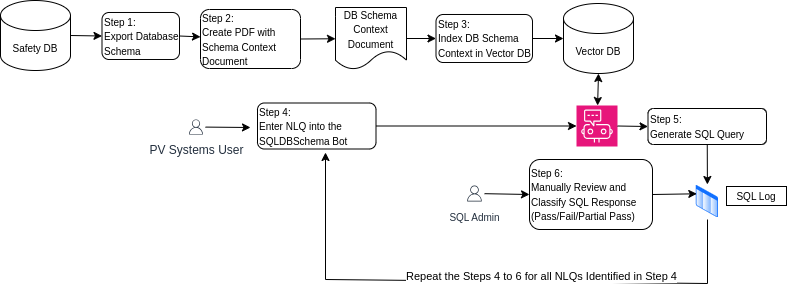
Figure 1: The experimental design for Phase 1, which focused on using a detailed database schema to provide context for the LLM.
- Phase 2: Evaluated the effectiveness of a business context document, which provided plain language summaries of the database structure and contextual insights into its relevance within the PV operational framework. (Figure 2)
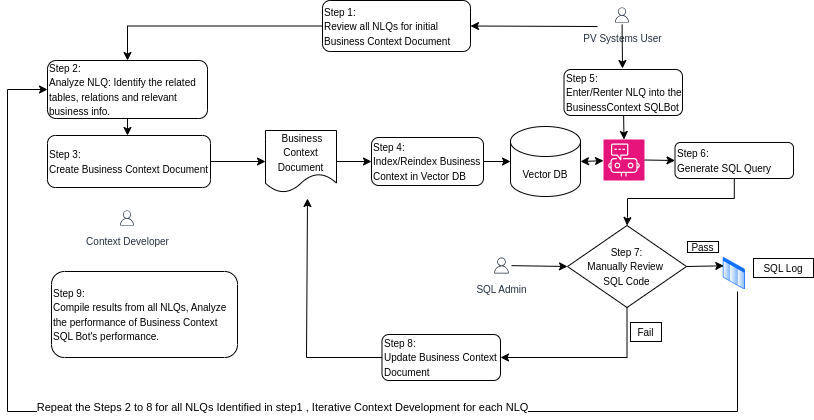
Figure 2: The experimental design for Phase 2, which incorporated a business context document to enhance the LLM's understanding of the database.
- Phase 3: Examined whether refining the approach from Phase 1 by focusing only on essential tables identified in the business context document could enhance or match the effectiveness demonstrated in Phase 2.
A set of 60 natural language queries (NLQs) were curated from historical user request logs and used consistently across all phases. The LLM's generated SQL code was evaluated by a database expert and categorized as "pass," "fail," or "partial pass" based on its accuracy and executability. The system architecture leverages OpenAI's GPT-4, hosted on Azure, and integrates with LangChain libraries. A vector-based retrieval strategy was consistently applied across all phases, leveraging embeddings from the text-embedding-ada-002 model. (Figure 3)
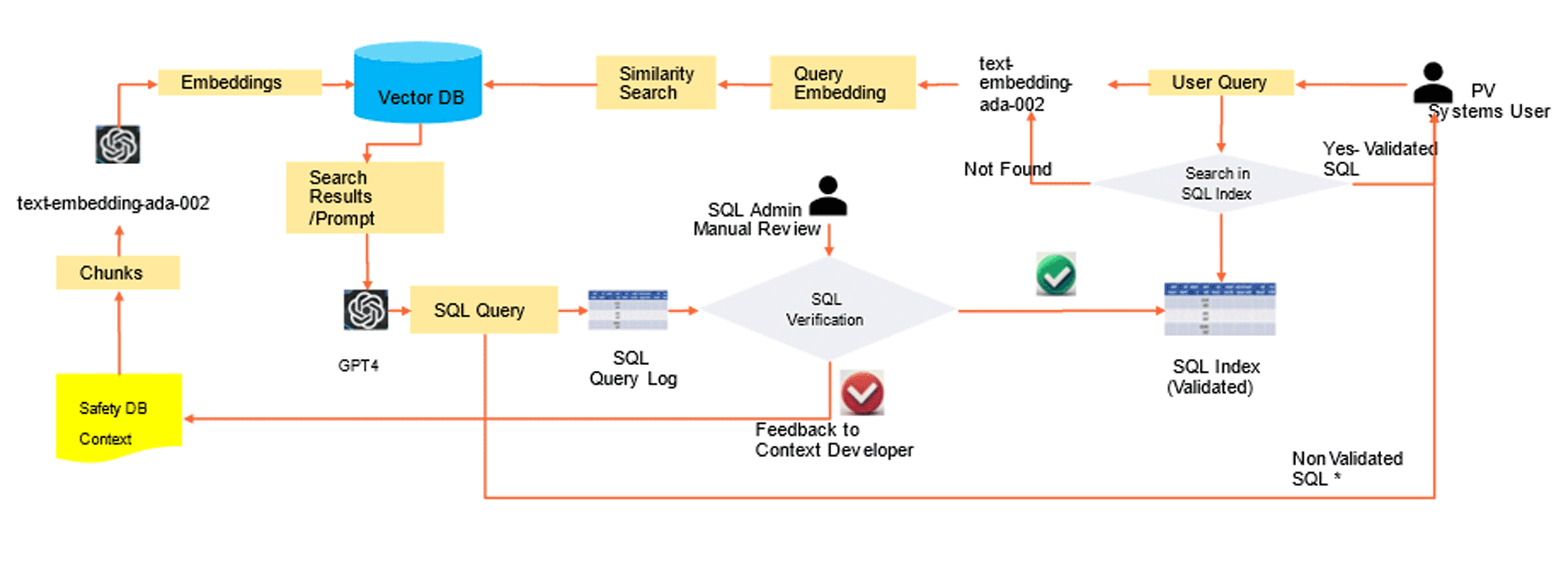
Figure 3: The system architecture diagram, highlighting the integration of the business context document and the RAG framework.
Results
The results demonstrate a significant improvement in SQL query generation accuracy when the LLM is augmented with a business context document.
- Phase 1 (database schema only) yielded a pass rate of 8.3%.
- Phase 2 (business context document) significantly improved the pass rate to over 78%.
- Phase 3 (refined schema) showed slight improvements over Phase 1, but did not match the success of Phase 2.
Statistical analysis using Fisher's Exact Test confirmed a statistically significant performance boost when the queries are enriched with contextual information. A complexity scoring algorithm was developed to provide an objective measure of SQL query complexity. The algorithm assigns points based on factors such as time estimated to manually create the query, the number of tables involved, and the presence of joins and aggregation functions. The complexity scores were categorized into "low," "medium," or "high" based on their percentile distribution. (Figure 4)
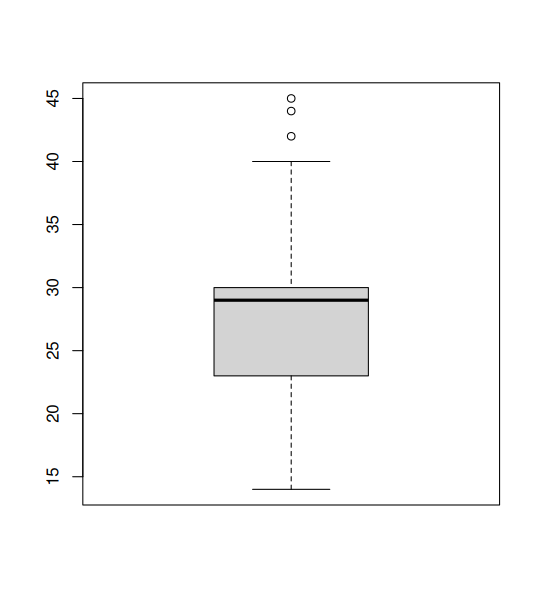
Figure 4: A boxplot illustrating the distribution of SQL complexity scores.
Discussion and Conclusion
The authors conclude that context-enriched LLMs hold significant potential for facilitating SQL query generation from NLQs within PV and other data-intensive domains. The integration of a business context document significantly enhances the LLM's ability to generate syntactically precise and contextually relevant SQL queries. The findings suggest a promising path towards democratizing access to complex databases and improving the intuitiveness and efficiency of data querying.
The authors acknowledge that further advancements are necessary to handle complex queries and resolve ambiguous user intents. They also highlight the need for future research to address concerns related to scalability and implementation within large, dynamic enterprise environments. The authors also point out that this is potentially a limiting factor in deploying a similar solution for other databases, as it requires one with expert knowledge of the system to help develop such a document. Updates to database structures or schemas in the future could also affect the utility of such a system and should be considered as to their impact in a production system for reliability.

