- The paper introduces a novel approach that integrates masked vector-quantized tokenization with a generative retrieval paradigm to overcome limitations in LLM-based recommendation systems.
- It leverages graph neural networks to capture high-order collaborative knowledge, enabling efficient and robust ID tokenization for both users and items.
- Experimental results show significant improvements in metrics like HR@20 and NDCG@20, while reducing computational costs for updates on new or unseen entities.
TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendation
"TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendation" (2406.10450) addresses the challenge of integrating LLMs into recommender systems by developing a novel ID tokenization method. This paper proposes a framework named TokenRec, which effectively combines a masked vector-quantized tokenization strategy and a generative retrieval process to improve recommendation efficiency and generalize across new or unseen users and items.
Introduction
Current recommender systems leverage collaborative filtering (CF) to model user-item interactions but struggle with embedding these complex relationships in a format suitable for LLMs. The prevalent challenge is capturing high-order collaborative knowledge efficiently using discrete tokens compatible with LLM architectures. Traditional methods often fail to offer robust solutions when generalizing to new users or items. TokenRec aims to bridge this gap by introducing a novel ID tokenization strategy facilitated through a masked vector-quantized (MQ) tokenizer, enhancing the LLM’s capability in handling CF tasks.
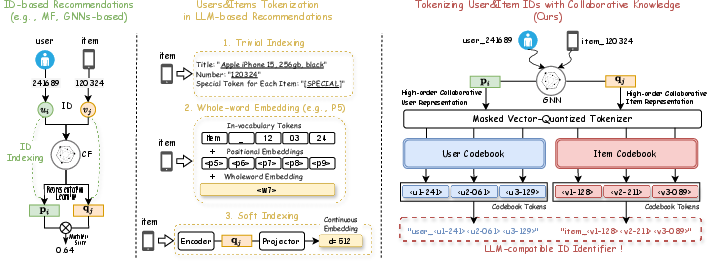
Figure 1: Comparison of ID tokenization methods in LLM-based recommendations. Unlike the existing methods, our approach can tokenize users and items with LLM-compatible tokens by leveraging high-order collaborative knowledge.
Methodology
Overview of TokenRec
TokenRec constructs its framework by focusing on MQ tokenizers designed to convert user and item IDs to quantizable tokens, incorporating collaborative filtering knowledge. It continues through a generative retrieval paradigm, effectively recommending items without the computationally intensive decoding typical in auto-regressive LLM processing.
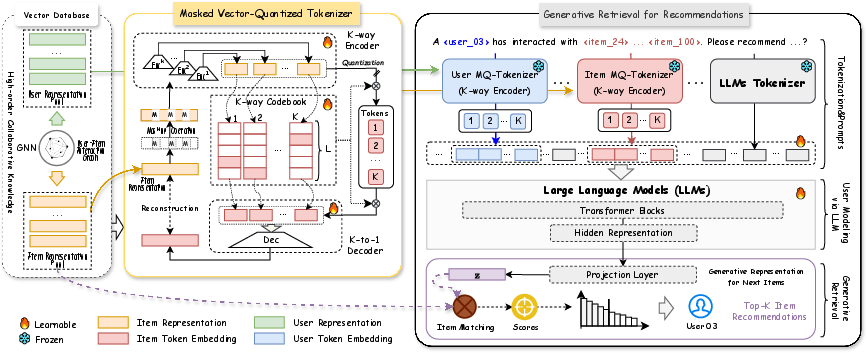
Figure 2: The overall framework of the proposed TokenRec, which consists of the masked vector-quantized tokenizer with a K-way encoder for item ID tokenization and the generative retrieval paradigm for recommendation generation. Note that we detail the item MQ-Tokenizer while omitting the user MQ-Tokenizer for simplicity.
Masked Vector-Quantized Tokenization
High-Order Collaborative Knowledge
The MQ tokenizer uses graph neural networks (GNNs) to learn high-order collaborative knowledge, transforming it into discrete tokens. This approach ensures that interactions between users and items can be captured in a quantized form suitable for LLMs.
Masking and K-way Encoding
TokenRec introduces an element-wise masking strategy to enhance the generalization capacity of tokenization. The K-way encoder further refines this process by allowing multi-head feature extraction, enabling the generation of discrete, tokenized codes that align with a learnable codebook structure.
Generative Retrieval Process
Rather than relying on LLMs' resource-intensive generation of description-like outputs, TokenRec employs a generative retrieval system. This system generates item representations coherent with the learned collaborative relations, then matches them against a precomputed item pool to generate recommendations efficiently.
Experimental Analysis
Generalization and Efficiency
TokenRec's evaluation shows superior performance and significant improvement in generalization abilities across multiple benchmark datasets, particularly when faced with new users or items not seen during training. The experiments demonstrated substantial performance gains over both traditional CF and recent LLM-based models.
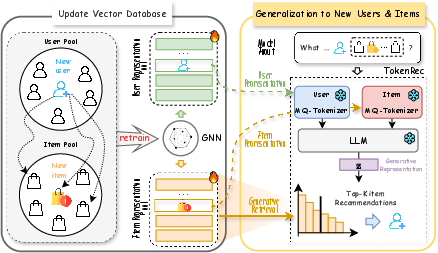
Figure 3: The TokenRec's efficiency and generalization capability for new users and items during the inference stage. Rather than retraining the MQ-Tokenizers and LLM backbone, which can be computationally expensive and time-consuming, only the GNN needs to be updated for learning representations for new users and items.
Hyper-parameter Sensitivity
Experiments varying the masking ratio (ρ) and structural parameters (number of sub-codebooks K and number of tokens per sub-codebook J) highlighted optimal settings that enhance performance metrics like HR@20 and NDCG@20.
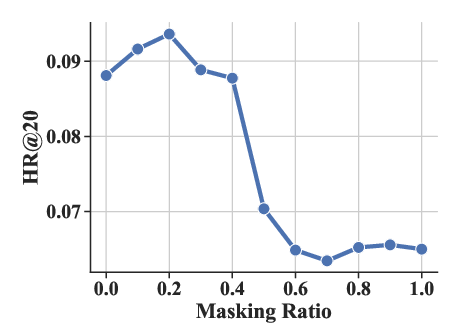
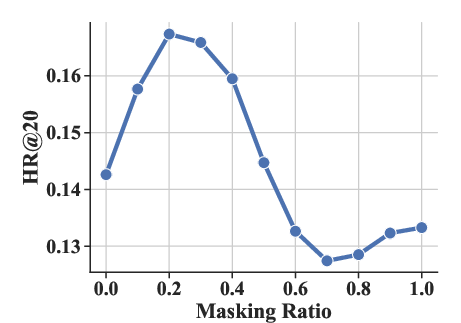
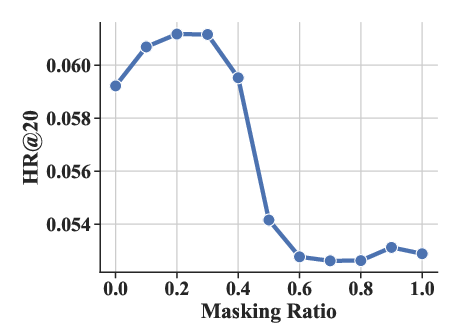
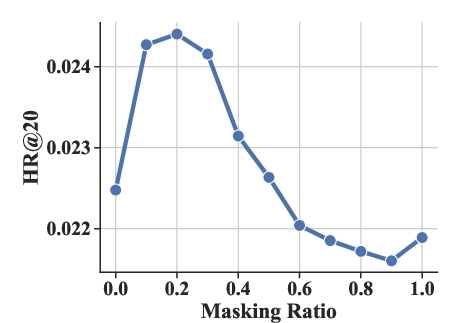
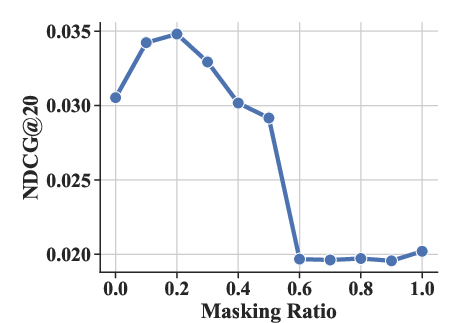
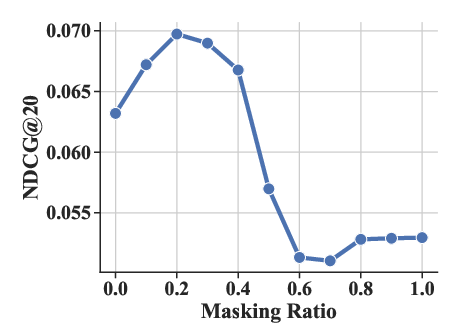
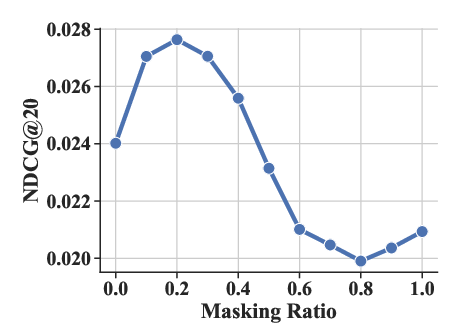
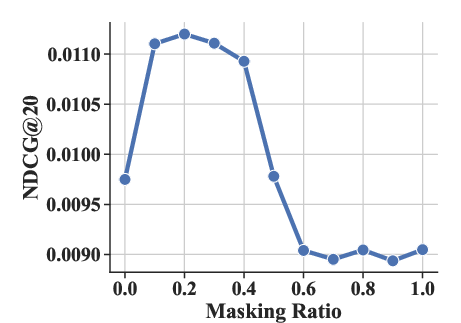
Figure 4: The effect of masking ratio ρ under HR@20 and NDCG@20 metrics.
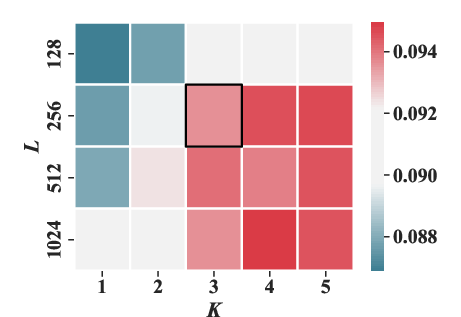
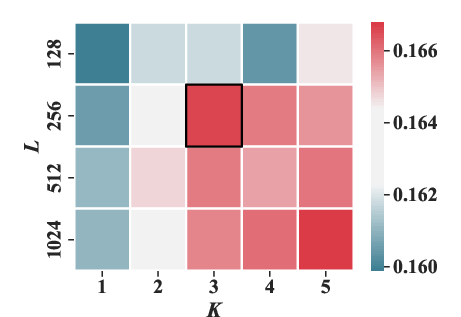
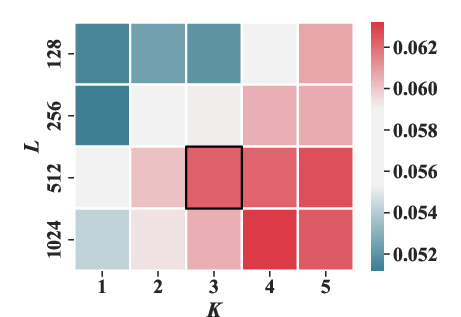
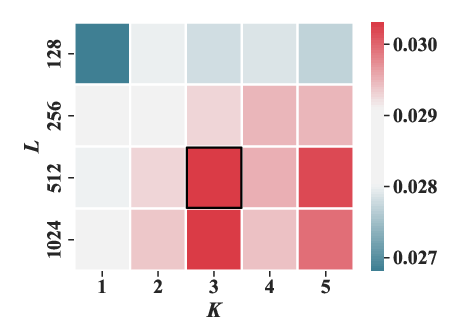
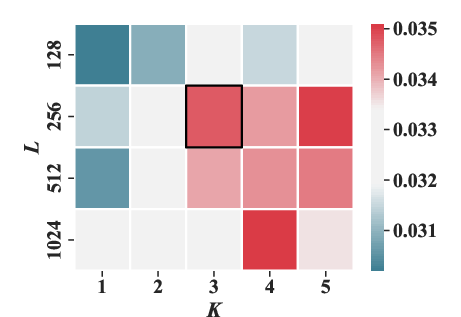
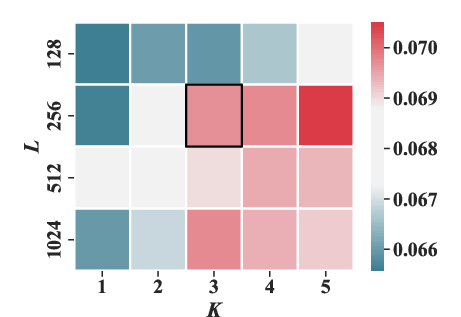
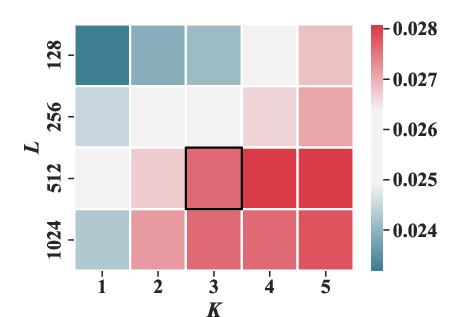
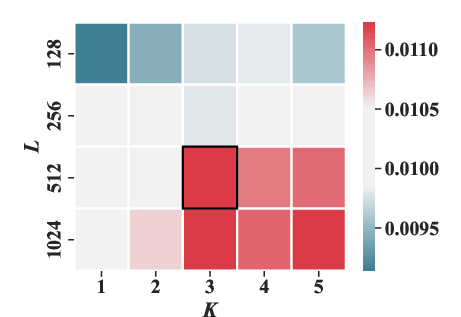
Figure 5: The effect of the number of sub-codebooks K and the number of tokens in each sub-codebook J under HR@20 and NDCG@20 metrics.
Conclusion
TokenRec effectively advances LLM-based recommendations by introducing a masked vector-quantized tokenization strategy coupled with an efficient retrievable paradigm. This framework captures collaborative filtering insights and transfers them effectively into LLMs, showcasing improved efficiency and generalization for unseen users and items. Future developments may focus on further optimizing the alignment of LLMs with collaborative signal extraction to extend application domains and address new challenges in recommendation efficiency and scalability.