- The paper introduces novel benchmarks, MaRs-VQA and VCog-Bench, to evaluate MLLMs' performance on abstract visual reasoning tasks.
- The paper demonstrates that current MLLMs rely on low-level pattern recognition and exhibit marked gaps in zero-shot abstract reasoning compared to humans.
- The paper suggests that integrating advanced cognitive architectures and hierarchical reasoning strategies could help bridge the gap with human cognitive abilities.
Visual Cognition Gap between Humans and Multimodal LLMs
Introduction
The study titled "What is the Visual Cognition Gap between Humans and Multimodal LLMs?" critically examines the capabilities of Multimodal LLMs (MLLMs) in abstract visual reasoning (AVR) tasks. These tasks are pivotal for assessing cognitive abilities as they require discerning patterns among images and predicting subsequent sequences based on abstract rules. The paper underscores the limitations of MLLMs in handling AVR problems, particularly when compared to human intelligence, using novel benchmarks like MaRs-VQA and VCog-Bench, informed by existing human cognitive assessment methods like RPM and WISC.
Multimodal LLMs and Visual Cognition
Recent advancements in MLLMs have brought significant improvements in perceptual tasks such as recognition, segmentation, and object detection. However, their ability to engage in high-level reasoning, necessary for abstract visual reasoning, remains inadequate. The study introduces MaRs-VQA, a dataset inspired by AVR tasks in RPM and WISC, to evaluate MLLMs' performance in zero-shot AVR inference settings. This benchmark highlights the visual cognitive shortcomings of current models, demonstrating their struggle to reach performance levels comparable to human reasoning.

Figure 1: The example of the subpar performance of current state-of-the-art MLLMs (GPT-4o, Claude 3 Sonnet) on a simple matrix reasoning task used in MaRs-VQA.
Methodological Innovations
The paper unveils the VCog-Bench, an assemblage of diverse datasets, including MaRs-VQA, designed to rigorously evaluate MLLM capabilities in AVR. The benchmark emphasizes zero-shot inference, challenging models to integrate perceptual understanding with symbolic reasoning without prior exposure to similar datasets. This methodology is crucial because it mirrors the human ability to solve AVR tasks spontaneously, without specific training, thus providing a more realistic assessment of genuine high-level cognitive abilities in artificial models.
Results and Analysis
Empirical results demonstrate a marked performance gap between MLLMs and human participants on these tasks. While models with greater parameters generally perform better in AVR tasks, they still fall significantly short of human benchmarks. Moreover, MLLMs exhibit inconsistent performance across different AVR tasks and tend to rely on low-level pattern recognition rather than genuine abstract reasoning.
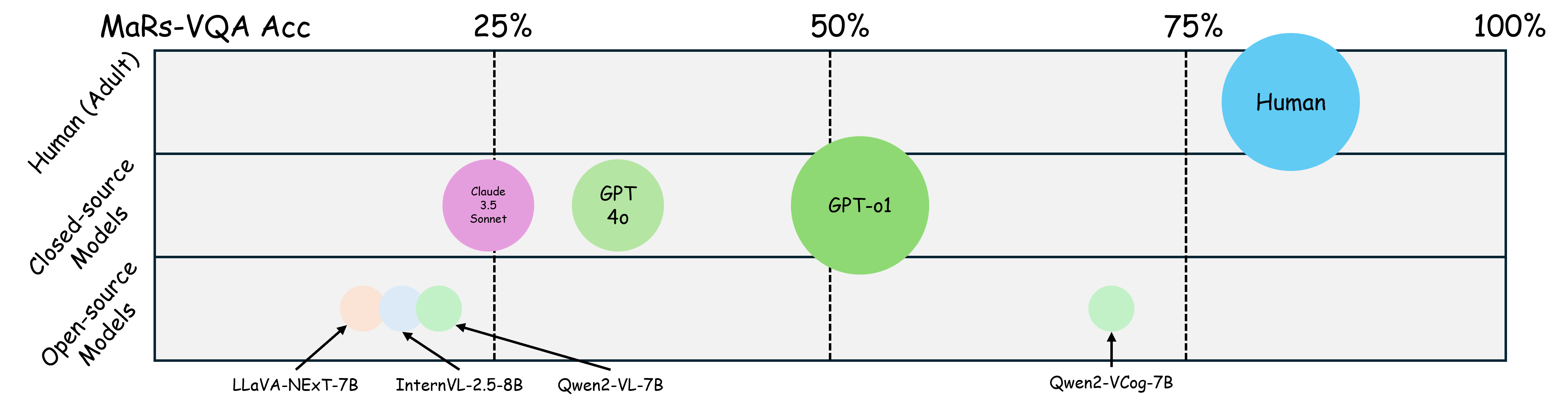
Figure 2: There is still a substantial gap between MLLM's (zero-shot CoT or SFT training) matrix reasoning capability and human's (zero-shot).
Implications and Future Work
The implications of this research are twofold. Practically, the VCog-Bench provides a new standard for evaluating AI models' visual reasoning capacities, which could drive the development of more sophisticated MLLMs. Theoretically, the study insights contribute to understanding the limitations of current AI systems in replicating human-like reasoning. Future research could explore integrating more advanced cognitive architectures or leveraging hierarchical reasoning strategies to enhance MLLMs' AVR capabilities. Furthermore, interdisciplinary collaboration between AI researchers, psychologists, and neuroscientists could foster novel insights into how cognitive faculties develop and operate, potentially guiding the creation of more human-like AI.
Conclusion
The investigation into the visual cognition gap reveals significant insights into the capabilities and limitations of current MLLMs in abstract reasoning tasks. By introducing thorough benchmarks like MaRs-VQA and VCog-Bench, the study sets a new foundation for evaluating and fostering advancements in AI's cognitive abilities. Despite their potential, MLLMs require further refinement to bridge the gap with human reasoning, ensuring progress toward achieving human-like intelligence in artificial systems.

