- The paper introduces the LLM-Codec, which converts audio signals into textual tokens to enable few-shot learning without requiring parameter updates.
- It employs multi-scale Residual Vector Quantization with semantic, coarse, and residual layers to achieve a balance between detail and token compactness.
- Performance tests show competitive audio reconstruction and classification metrics, highlighting its potential for streamlined audio understanding and generation.
UniAudio 1.5: LLM-driven Audio Codec as a Few-shot Audio Task Learner
UniAudio 1.5 introduces a novel approach to leveraging LLMs for audio processing tasks by creating the LLM-Codec. This audio codec model allows for translating audio into a textual format that LLMs can interpret and apply to various audio tasks using in-context learning. The framework does not require parameter updates, making it efficient and versatile across multiple audio applications. This essay will explore the architecture, methodology, and performance of UniAudio 1.5.
Overview of LLM-Codec
The LLM-Codec is the core innovation of UniAudio 1.5, compressing audio modality into the textual token space of LLMs, treating it as a new "foreign language" for the model to learn. The goal is to minimize modality heterogeneity between audio and text to facilitate the application of LLMs on audio tasks. The model uses a semantic-guided multi-scale Residual Vector Quantization (RVQ) codec comprised of three layers: semantic, coarse-grained acoustic, and residual acoustic layers.
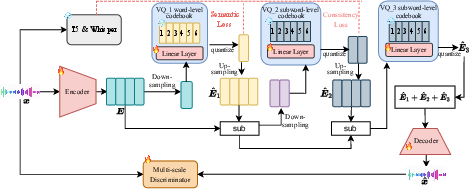
Figure 1: A high-level overview of LLM-Codec. Sub denotes the feature subtraction. We assume 3 RVQ layers are used in our study.
Encoder and Decoder
The encoder of LLM-Codec translates audio data into latent representations which are subsequently quantized into tokens through multiple RVQ layers. This structured quantization preserves semantic richness and ensures high fidelity in audio reconstruction.
Multi-scale Residual Vector Quantization
The multi-scale RVQ strategy is at the heart of LLM-Codec's architecture. It employs three distinct layers designed to encode varying levels of detail - from semantic to residual acoustic information - ensuring a balanced approach between completeness and compactness. This method significantly reduces the length of token sequences while retaining necessary information for effective task execution.
Application to Few-shot Learning
UniAudio 1.5 leverages in-context learning capabilities of LLMs to perform various audio tasks. This approach allows for rapid adaptation to new tasks by providing minimal examples. The system is tested on several tasks to validate its versatility in audio understanding and generation.
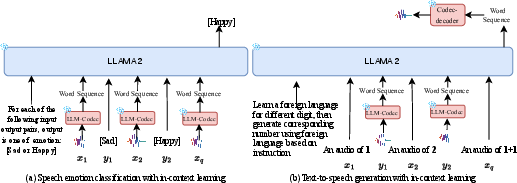
Figure 2: This figure illustrates the framework of the proposed approach (UniAudio 1.5) to conduct speech emotion classification and simple text-to-speech generation tasks.
The efficacy of LLM-Codec in audio reconstruction was assessed using metrics like Perceptual Evaluation of Speech Quality (PESQ) and Short-Time Objective Intelligibility (STOI).
Reconstruction Quality
Table comparisons indicate that LLM-Codec maintains high reconstruction performance with a notable reduction in token quantity. This efficiency is critical when scaling applications that require processing large volumes of audio data.
Audio Understanding
Experiments across tasks such as speech emotion classification and sound event detection demonstrate LLM-Codec's ability to maintain accuracy comparable to specialized models, despite leveraging fewer resources and pre-trained models.

Figure 3: The token visualization with LLM-Codec. The audio samples are from the ESC50 dataset.
Audio Generation
UniAudio 1.5 facilitated audio generation tasks, exhibiting effective text-to-speech and speech denoising capabilities in constrained environments, validating the potential for deploying LLM-driven audio solutions in simplistic generation scenarios.
Implications and Future Directions
The ability to couple LLMs with audio codec models to apply few-shot learning across audio-related tasks is a significant advancement, offering expanded audio processing functionalities within NLP frameworks. The proposed approach sets the foundation for future research into multi-modal LLMs, highlighting the potential for integrating more advanced model architectures without extensive parameter modification.
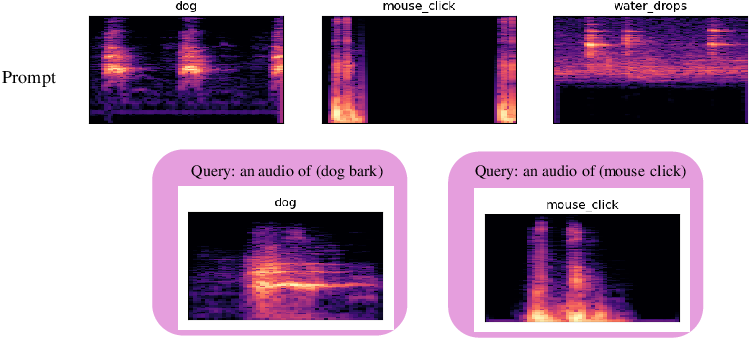
Figure 4: Examples of simple text-to-sound generation on FSDD dataset using LLM-Codec with a frozen LLAMA2 7B model.
Conclusion
UniAudio 1.5 proposes an efficient and innovative approach to integrating LLMs with audio tasks, demonstrating successful application across diverse scenarios without parameter updates. While current results are promising, future research should focus on expanding LLM usability in audio tasks through enriched training data and optimizing codebook initialization strategies for improved task performance. The ability to translate complex audio data into the token space of LLMs opens pathways to new applications in AI-driven audio technology, with the potential for further enhancements and specialization.

