- The paper introduces HIRO, a method using DFS-based recursive similarity scoring and branch pruning to refine context retrieval in RAG systems.
- It leverages hierarchical document structures with dynamic Selection (S) and Delta (Δ) thresholds to manage data overload while preserving critical information.
- Experiments on NarrativeQA and QuALITY datasets highlight HIRO's efficiency gains and improved accuracy compared to traditional retrieval methods.
Introduction
The paper "HIRO: Hierarchical Information Retrieval Optimization" (2406.09979) introduces HIRO, an advanced querying mechanism designed to improve Retrieval-Augmented Generation (RAG) systems using hierarchical document structures. The motivation behind this research is the enhancement of LLMs that, despite their impressive language processing capabilities, suffer from the static nature of their training datasets, resulting in outdated knowledge and less credible responses for dynamic, knowledge-intensive tasks. RAG models address these limitations by linking LLMs to dynamic external data sources, increasing their accuracy for such tasks.
However, a notable challenge with RAG models is their performance degradation when they encounter extended contexts, often leading to incoherent responses. To mitigate this, the paper proposes using hierarchical data structures for organizing documents, which is hypothesized to efficiently manage information density and summarization at multiple levels. HIRO leverages this structural advantage but enhances it with Depth-First Search (DFS)-based recursive similarity score calculation and strategic branch pruning. This methodological innovation aims to deliver distilled context to LLMs, maintaining all critical information while preventing overload, a significant improvement demonstrated by its performance gains on the NarrativeQA dataset.
(Figure 1)
Figure 1: Architectural Overview of a Retrieval-Augmented LLM (RALM).
Retrieval-Augmented Generation (RAG)
RAG models enhance LLMs by retrieving contextually relevant data from external databases, reducing the incidence of hallucinated information. Despite their success, RAG models face challenges in scalability and efficiency, particularly when dealing with large datasets and complex queries.
Hierarchical Data Structures
The hierarchical organization of documents, exemplified by RAPTOR, represents a pivotal shift in information retrieval systems. By using recursive summarization techniques to create tree structures, systems like RAPTOR facilitate nuanced access to information at varying abstraction levels, promising improved coherence and relevance. However, the retrieval of both parent and child nodes can lead to redundant information—an inefficiency this paper directly addresses with HIRO.
(Figure 2)
Figure 2: Traditional Tree Traversal Querying.
(Figure 3)
Figure 3: Collapsed Tree Querying Mechanism.
Existing Querying Mechanisms
Prior querying mechanisms rely on static quantities of data retrieval, which often do not match query requirements—either providing too much or too little context. This static definition contributes to models choking under excessive data loads, compromising response quality.
Recursive Similarity Check and Branch Pruning
HIRO introduces innovative Recursive Similarity Thresholding and Branch Pruning, leveraging Selection (S) and Delta (Δ) thresholds to dynamically refine the context provided to LLMs. This process ensures relevant information is captured and excess data pruned effectively, preventing overload.
(Figure 4)
Figure 4: HIRO Querying Mechanism.
Methods
The paper outlines a method where each node in a hierarchical document structure is initially evaluated based on its similarity to the query. Nodes surpassing a predefined Selection Threshold (S) are earmarked. For each of these nodes, their child nodes are examined, factoring in a Delta Threshold (Δ) to determine relevance and recursively ascertain optimal context. This dual-threshold approach dynamically adjusts the depth and breadth of retrieved information, balancing between granularity and efficiency.
Experiments
Datasets
The evaluation uses the NarrativeQA and QuALITY datasets. NarrativeQA contains narrative-focused content, ideal for testing pruning methodologies, while QuALITY challenges models with long texts requiring precise information extraction.
Results
HIRO demonstrated marked improvements over conventional methods, returning more concise context and heightened performance metrics on NarrativeQA. It showed efficiency gains by reducing computational overload while maintaining robust response generation. On QuALITY, HIRO maintained competitive scores, slightly lower in some metrics, indicating a trade-off between optimization and general performance nuances.
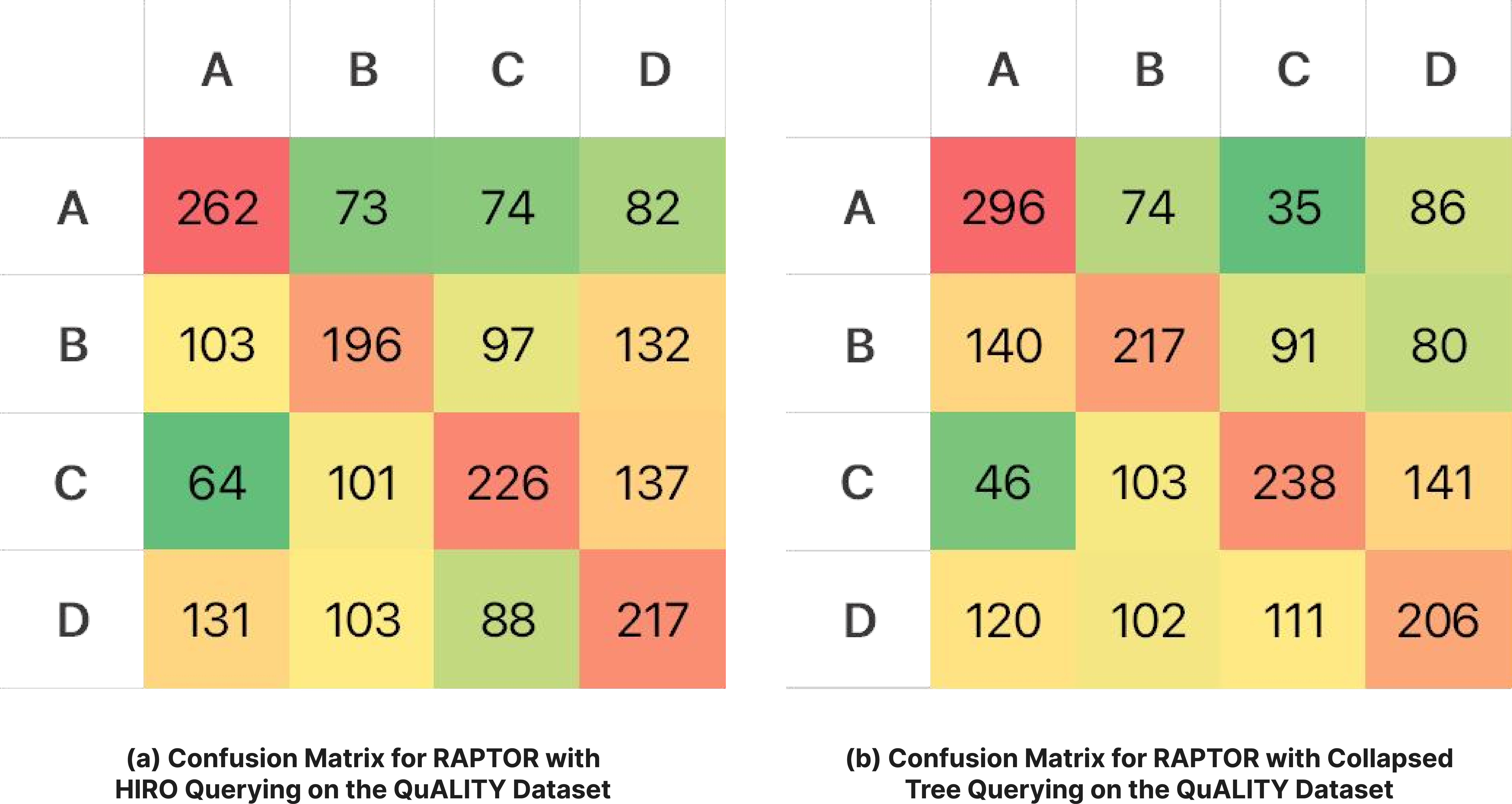
Figure 5: Absolute Impact of HIRO on the NarrativeQA Dataset.
(Figure 6)
Figure 6: Efficiency Analysis of HIRO on NarrativeQA Dataset.
(Figure 7)
Figure 7: Confusion Matrices for RAPTOR on the QuALITY Dataset.
Conclusion
HIRO proposes a significant enhancement to the traditional querying mechanisms in RAG systems. By strategically managing the context delivered to LLMs through hierarchical structures, it alleviates common overload issues that degrade model performance, achieving both more accurate and efficient retrieval and response generation. Future work can explore extending HIRO's methodology to various domains and datasets, continually improving the robustness and applicability of LLMs in dynamic, real-world contexts.