TabularFM: An Open Framework For Tabular Foundational Models
Abstract: Foundational models (FMs), pretrained on extensive datasets using self-supervised techniques, are capable of learning generalized patterns from large amounts of data. This reduces the need for extensive labeled datasets for each new task, saving both time and resources by leveraging the broad knowledge base established during pretraining. Most research on FMs has primarily focused on unstructured data, such as text and images, or semi-structured data, like time-series. However, there has been limited attention to structured data, such as tabular data, which, despite its prevalence, remains under-studied due to a lack of clean datasets and insufficient research on the transferability of FMs for various tabular data tasks. In response to this gap, we introduce a framework called TabularFM, which incorporates state-of-the-art methods for developing FMs specifically for tabular data. This includes variations of neural architectures such as GANs, VAEs, and Transformers. We have curated a million of tabular datasets and released cleaned versions to facilitate the development of tabular FMs. We pretrained FMs on this curated data, benchmarked various learning methods on these datasets, and released the pretrained models along with leaderboards for future comparative studies. Our fully open-sourced system provides a comprehensive analysis of the transferability of tabular FMs. By releasing these datasets, pretrained models, and leaderboards, we aim to enhance the validity and usability of tabular FMs in the near future.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open problems that remain unresolved and could guide follow-up research.
- Scope and scale of pretraining data
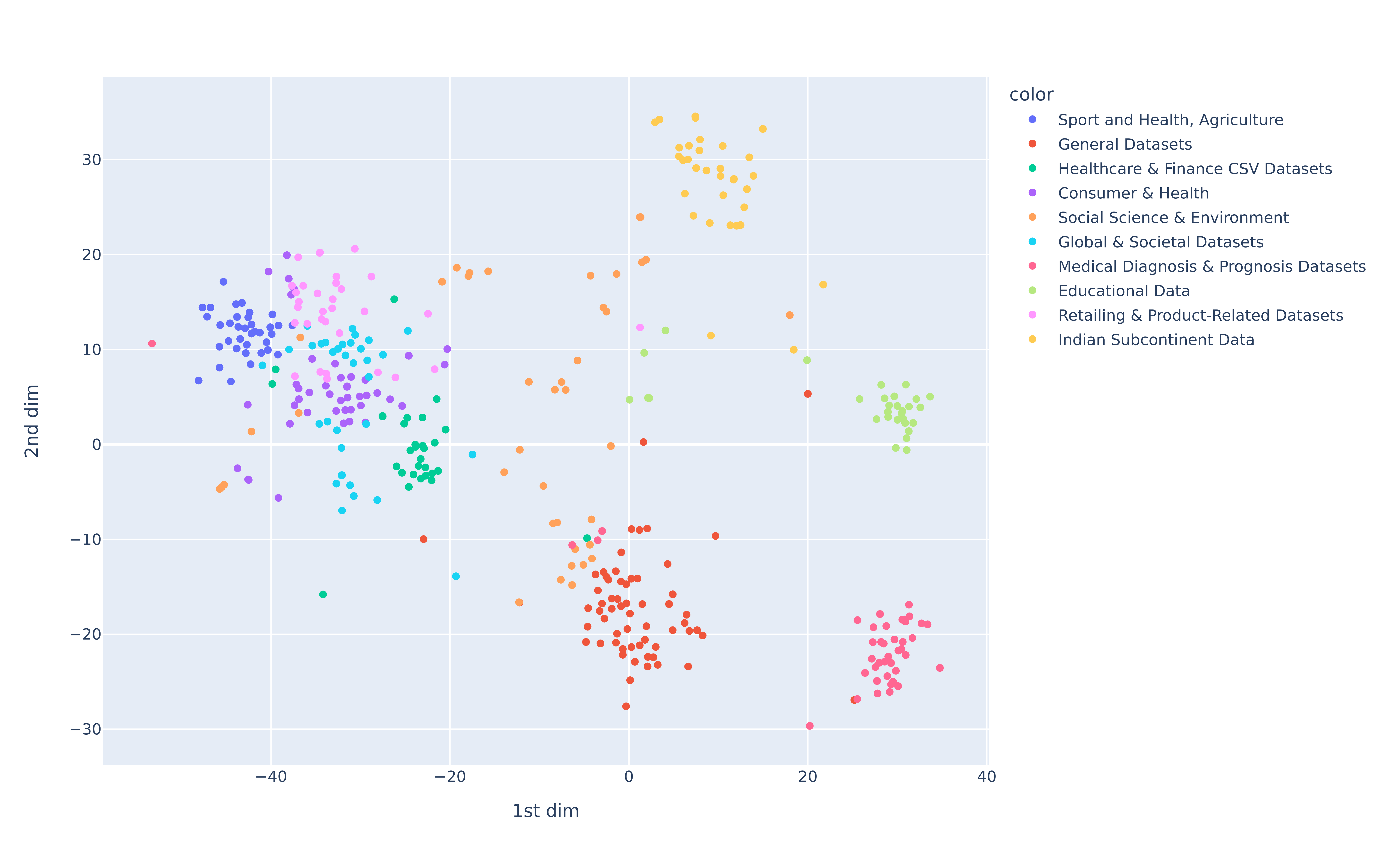
- The “cleaned” corpus shrinks from ~1M raw tables to only 2,693 usable tables; it is unclear whether transferability conclusions hold at larger, more diverse scales and in non-public/enterprise domains.
- Lack of analysis on dataset biases induced by sourcing only from Kaggle and GitHub (topic skew, language skew, quality skew) and how these biases affect transfer.
- No ablation on how the degree of table heterogeneity (schemas, domain coverage, cardinalities) influences pretraining benefits.
- Domain split validity and leakage
- The “domain-based” split relies on k-means over BERT embeddings of table names; this risks leakage via naming conventions and does not ensure distributional independence at the value level.
- No alternative domain partitioning strategies (e.g., based on value distributions, metadata fields, provenance/repo, or leave-one-domain-out) are tested to validate robustness of transfer claims.
- Evaluation scope: synthetic data quality vs task utility
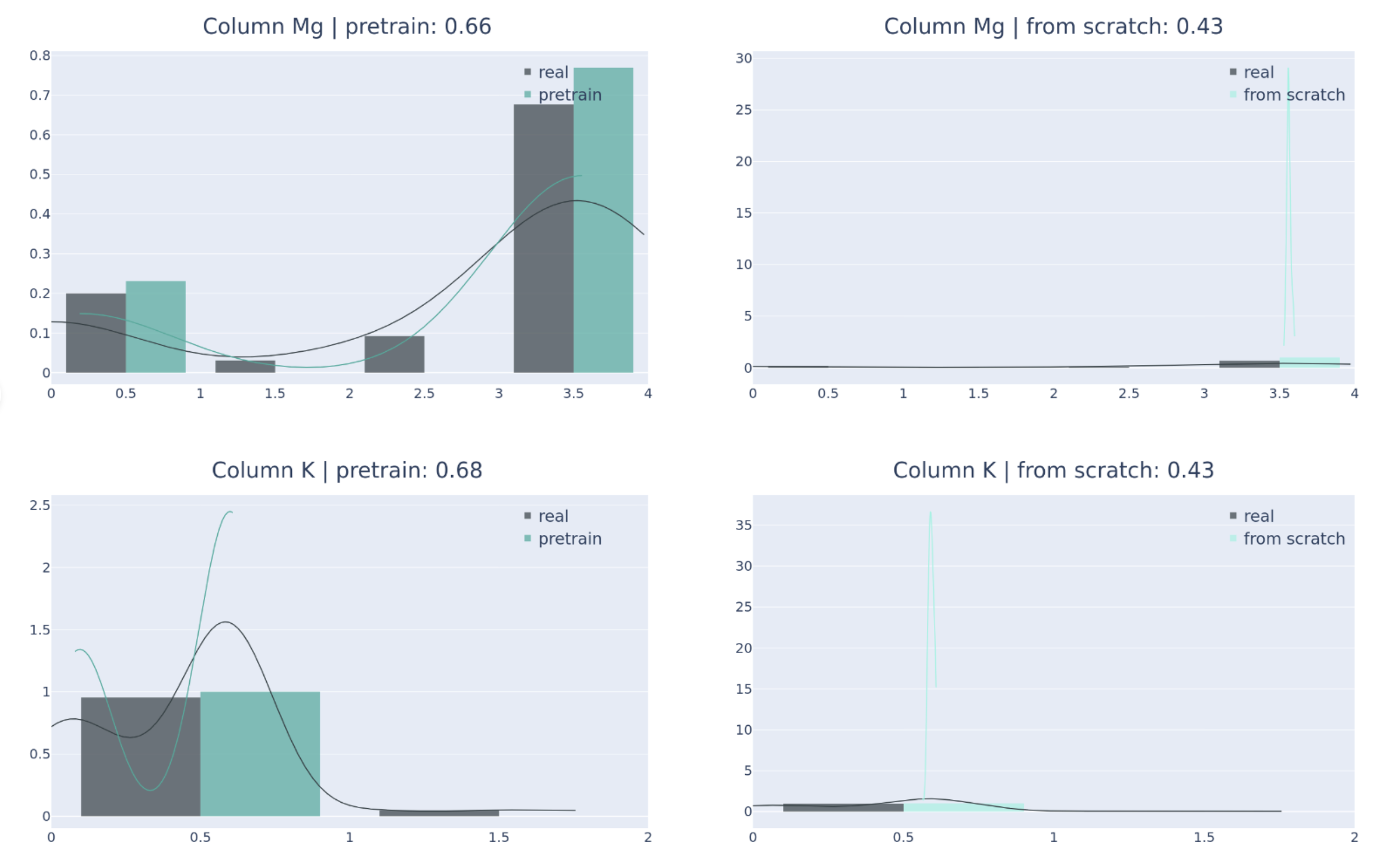
- Transferability is assessed only through synthetic-versus-real similarity (column shapes, pairwise correlations) rather than downstream task utility (classification/regression, imputation, anomaly detection).
- No TSTR/TSLR-style evaluations (Train on Synthetic, Test on Real / vice versa) or linear-probe tests on learned representations to verify practical utility of the pretraining.
- Metrics and statistical rigor
- Evaluation relies on marginal distributions and Pearson pairwise correlations; higher-order dependencies, nonlinear relationships, and constraint satisfaction (e.g., functional dependencies) are not measured.
- No classifier two-sample tests, mutual information, copula-based distances, or multi-variate goodness-of-fit metrics to capture complex tabular structure.
- Multiple-comparisons handling and robustness across random seeds are not reported; sensitivity to evaluation protocol (sample sizes, subsampling strategy) is unexplored.
- Missing data, outliers, and real-world artifacts
- Datasets were filtered to remove noisy/unstructured content; the framework does not model missingness patterns, outliers, or data-entry errors common in real-world tables.
- No evaluation of imputation capability or how pretraining affects robustness to missing values and extreme values.
- Categorical encoding and scalability
- One-hot encoding is used for categorical variables; the framework does not address high-cardinality categories, rare category handling, or memory-efficient encodings (e.g., hashing, learned embeddings).
- No analysis of how category cardinality and imbalance affect pretraining transfer and model stability.
- Units, scales, and semantic typing
- Preprocessing normalizes numerics using mixture-of-Gaussians per column but does not incorporate units, value ranges, or semantic types; cross-table comparability of semantically similar columns is therefore unclear.
- Open question: which semantic signals (types, units, ontologies, value vocabularies) most improve cross-table transfer?
- Column-name dependence and obfuscation
- LLM-based methods and metadata use heavily depend on column names; there is no evaluation with obfuscated, noisy, multilingual, or synonym-rich schema names to test semantic robustness beyond surface tokens.
- It remains unclear how much transfer stems from general world knowledge in GPT-2 versus actual tabular structure learning.
- Metadata design and incorporation
- The proposed STVAEM (dataset-level “signature” from column-name embeddings) did not help; there is no systematic exploration of alternative metadata (types, units, statistical profiles, schema graphs) or how to incorporate them (adapters, prompts, multi-task losses).
- No experiments with ontology alignment, schema linking, or entity/value-level metadata that could bridge schema heterogeneity.
- Permutation invariance and table symmetries
- CTGAN/TVAE variants are not permutation-invariant; the impact of column order and row order is not ablated.
- No evaluation of architectures explicitly enforcing set/sequence invariances (e.g., DeepSets, Set Transformers, permutation-invariant positional encodings) or order-agnostic serializations for LLMs.
- LLM adaptation challenges
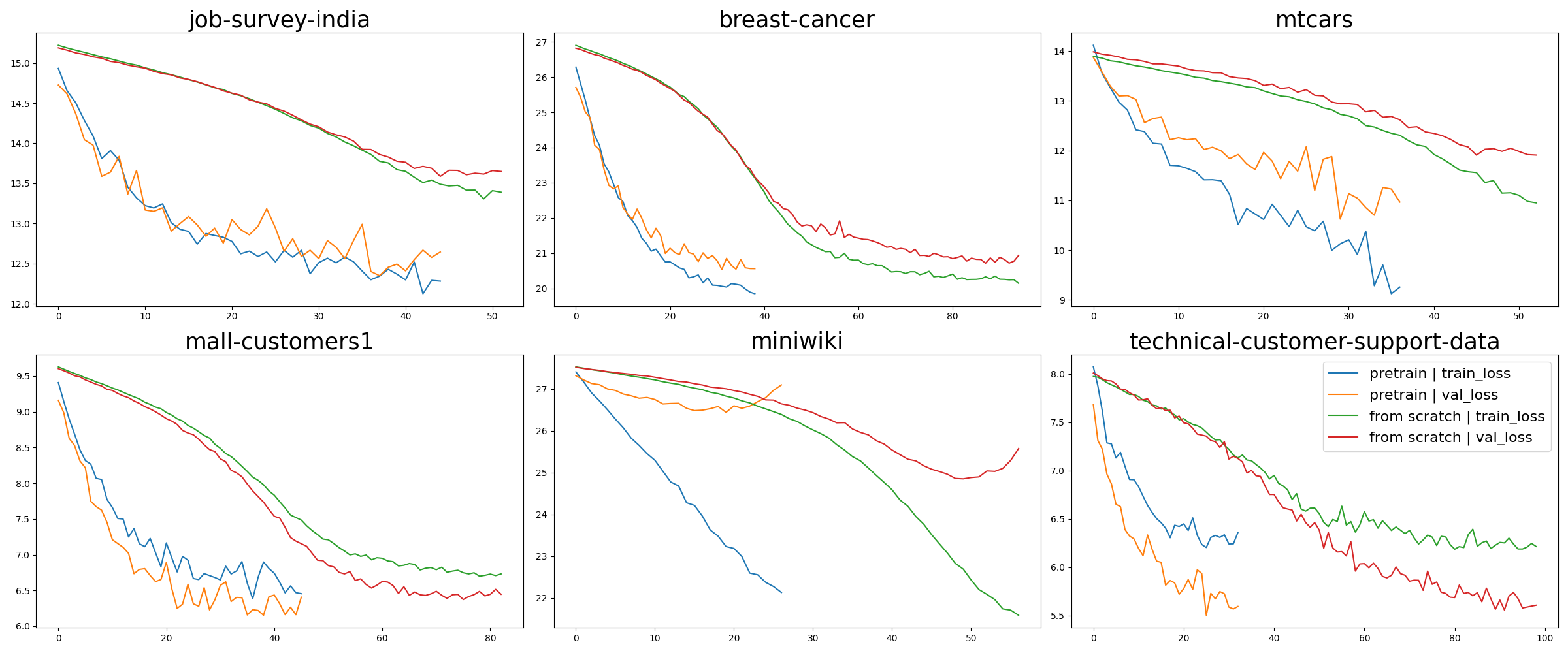
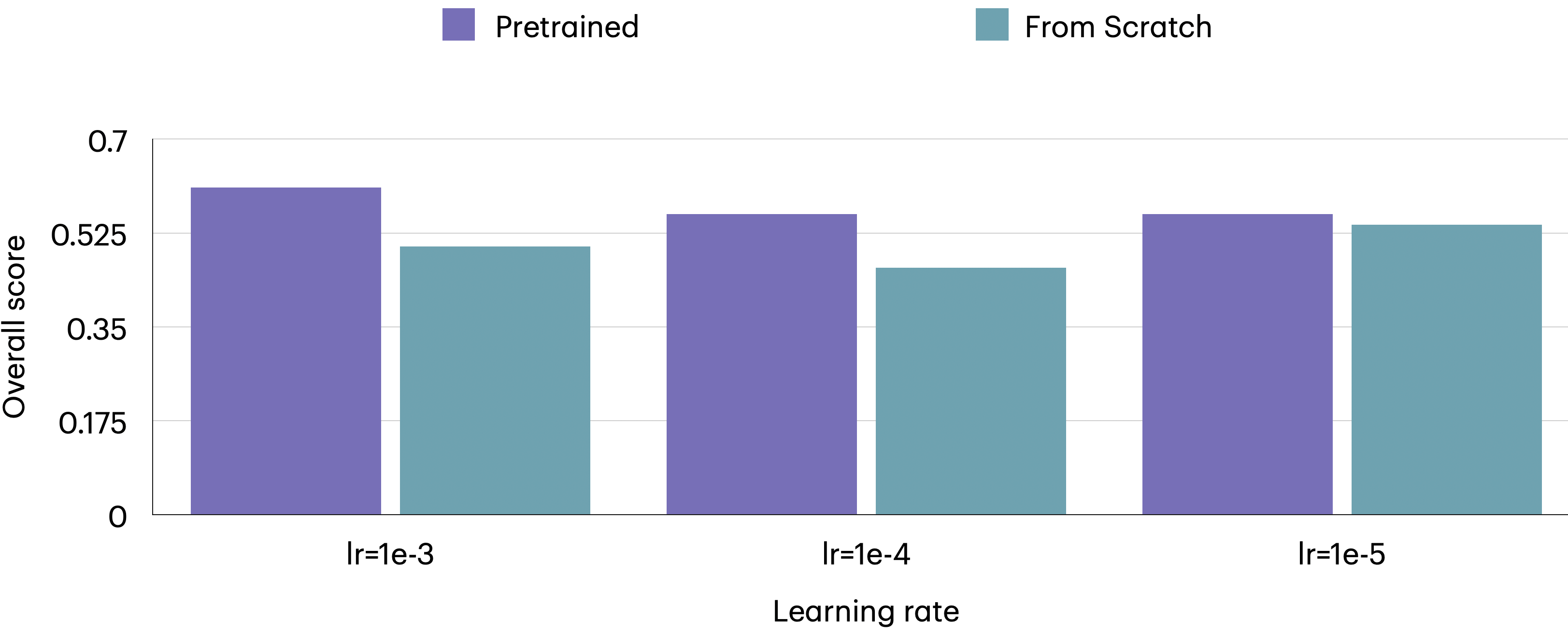
- Fine-tuning GPT-style models on the provided tabular corpora hurts performance; the causes (catastrophic forgetting, insufficient data scale, poor serialization, optimization settings) remain untested.
- No exploration of parameter-efficient tuning (LoRA, adapters), replay/regularization for anti-forgetting, curriculum learning, or serialization/prompting ablations to stabilize tabular adaptation.
- Architectural coverage and baselines
- The framework evaluates only CTGAN/TVAE family and one LLM-based generator; modern alternatives (e.g., diffusion models for tables like TabDDPM, normalizing flows, CTAB-GAN+, masked autoencoders, FT-Transformer/SAINT/TabTransformer) are absent.
- Classical probabilistic baselines (Gaussian copulas, Bayesian networks) are missing, limiting interpretability of gains.
- Privacy, memorization, and safety
- No privacy audits (membership inference, attribute inference, record linkage) or differentially private training; the risk of memorization in generative tabular FMs is unquantified.
- No fairness/bias assessment (e.g., transfer on sensitive attributes like Age/Gender), nor analysis of spurious correlations that may be amplified by pretraining.
- Representations beyond generation
- The framework focuses on data synthesis; it is unclear whether pretrained encoders yield transferable representations for non-generative tasks (e.g., few-shot classification/regression, retrieval, causal discovery).
- No release/evaluation of reusable tabular encoders with task-agnostic objectives (contrastive, masked-cell modeling).
- Constraint and relational awareness
- Row/column-level constraints (uniqueness, sums, monotonicity), and inter-column logical relations are not modeled or evaluated in generation quality.
- Only single-table settings are considered; multi-table, relational schemas (foreign keys, joins) and cross-table pretraining are unexplored.
- Temporal, spatial, and mixed-type columns
- The framework excludes temporal, geospatial, free-text, image-in-cell, and other mixed types frequently present in tabular data; typed handling and cross-modal pretraining remain open.
- The impact of date/time-specific semantics and seasonality on transfer is not evaluated.
- Hyperparameter, compute, and scaling laws
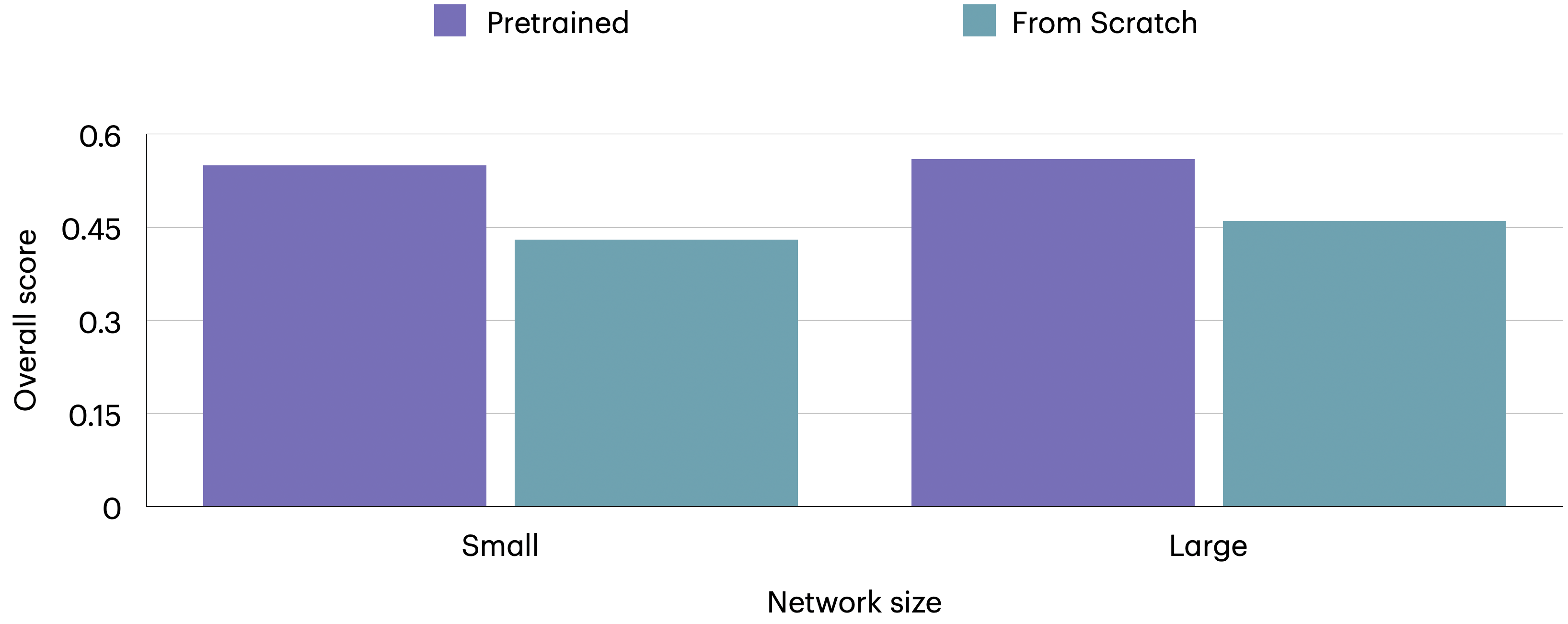
- Pretraining budgets are limited (single A100, 2 days cap); undertraining may confound negative LLM fine-tuning results.
- No systematic scaling-law study (model size, data size, training steps) to map performance vs. resources.
- Reproducibility and licensing
- Kaggle license restrictions prevent full release of trained models, impeding reproducibility; community-standard, fully open benchmarks/splits are still missing.
- Seed control, run-to-run variance, and environment determinism are not documented across all experiments.
- Cross-lingual and multi-locale generalization
- No analysis of column/value languages, locale-specific formats (decimal separators, dates, currencies), or multilingual embeddings for cross-lingual transfer.
- Robustness and security
- Adversarial robustness (e.g., to schema perturbations, value corruptions) and distribution shift resilience are not evaluated.
- No study of how small schema changes (renaming, reordering, type-casting) affect pretrained model performance.
- Interpretability of transferred “knowledge”
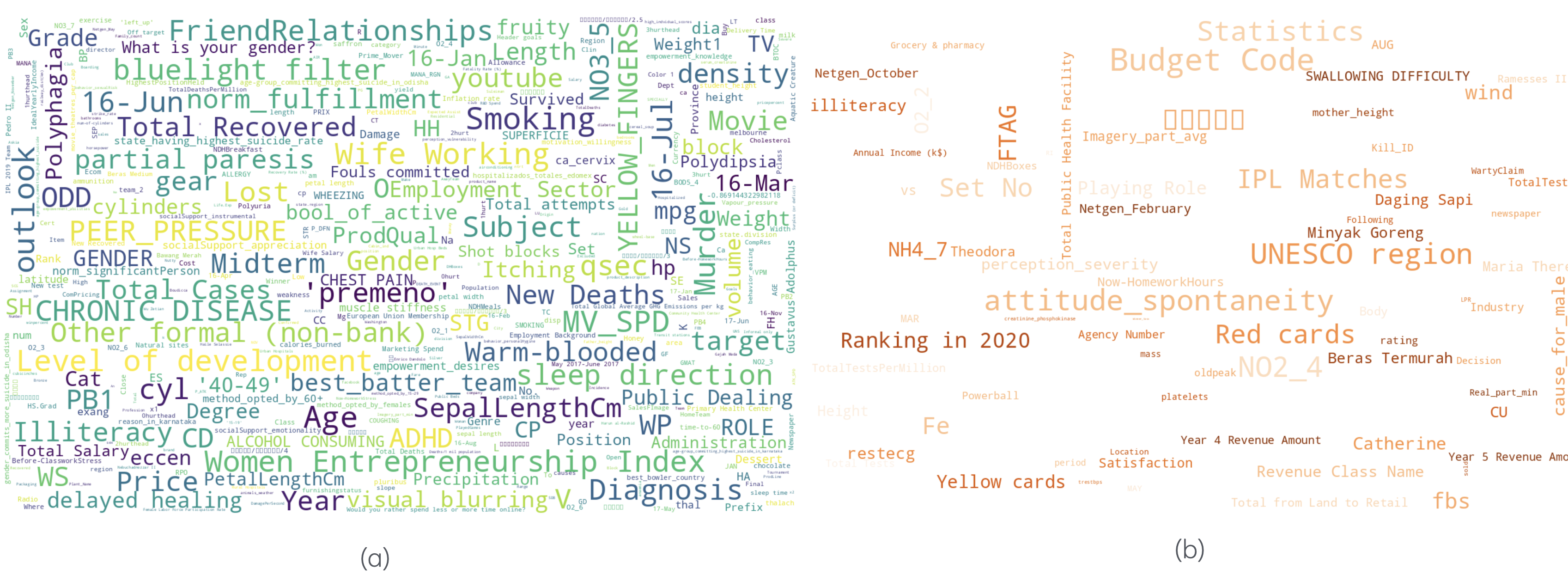
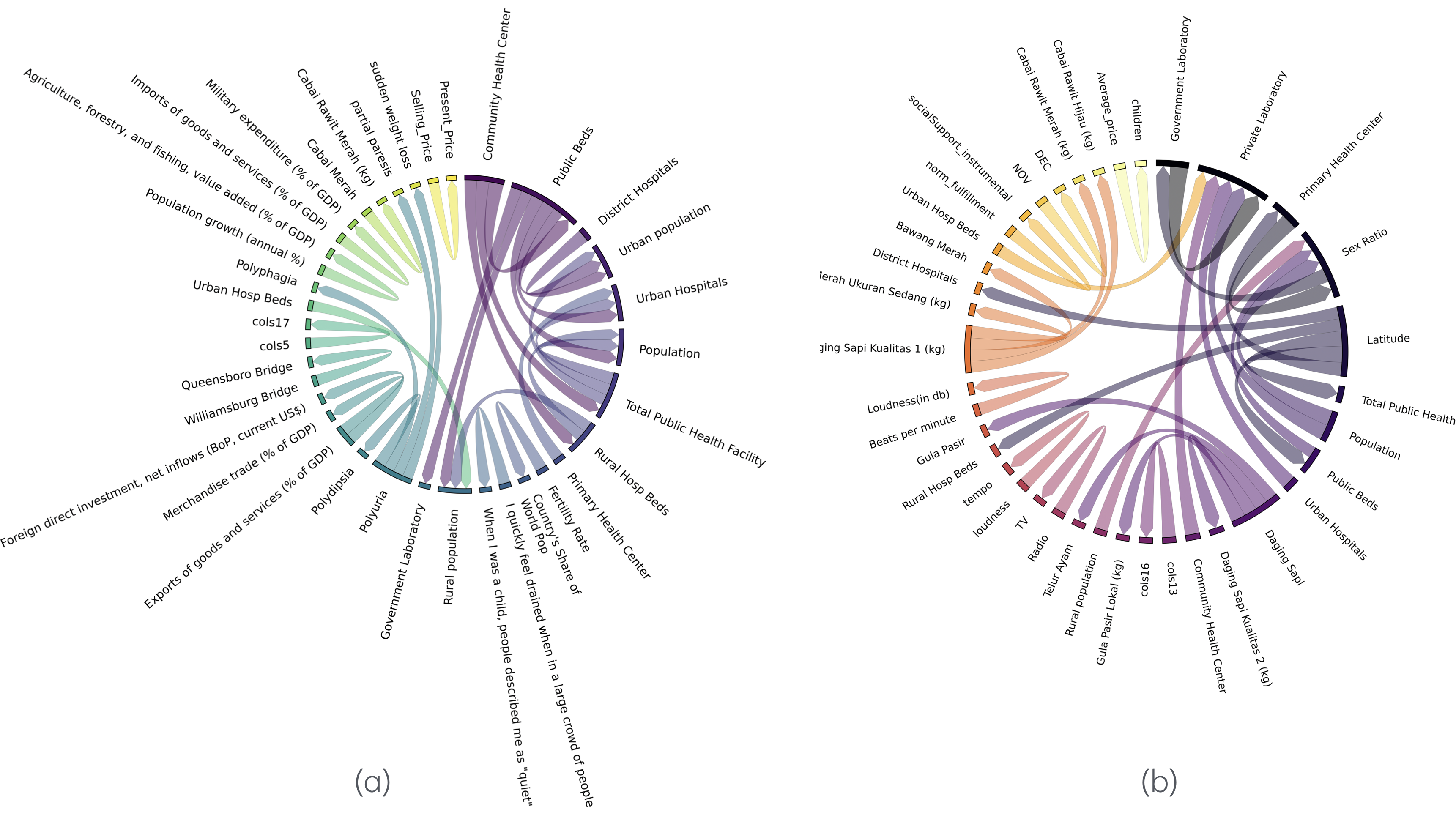
- Qualitative wordcloud/correlation analyses are suggestive but not causal; controlled studies are needed to validate which correlations truly generalize and which are dataset artifacts.
- Leaderboard design and standardization
- The proposed leaderboards center on synthetic data fidelity; standardized suites spanning utility, privacy, fairness, robustness, and constraint satisfaction are needed for comprehensive FM assessment.
- Generalization to unseen schemas (zero-shot)
- The framework does not evaluate zero-shot generation or adaptation to entirely unseen schemas (novel columns and combinations) without fine-tuning.
- Environmental impact
- No reporting on energy/carbon costs or efficiency comparisons across methods, which are increasingly expected for FM research.
Collections
Sign up for free to add this paper to one or more collections.

