- The paper presents a novel approach to unsupervised domain adaptation by reframing the problem as multiple-objective optimization via prompt gradient alignment.
- It leverages domain-agnostic and domain-specific prompts with gradient norm penalization to balance feature discriminability and generalization.
- Empirical results on benchmarks like ImageCLEF, Office-Home, and DomainNet demonstrate superior performance over traditional UDA methods.
Enhancing Domain Adaptation through Prompt Gradient Alignment
Introduction
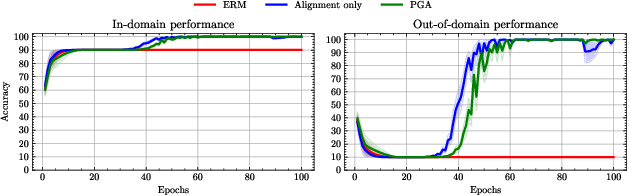
The paper "Enhancing Domain Adaptation through Prompt Gradient Alignment" presents a novel approach to Unsupervised Domain Adaptation (UDA) by leveraging large-scale pre-trained vision-LLMs through prompt learning. Traditional UDA methods focus on creating domain-invariant features, which may compromise feature discriminability. Instead, this method reframes UDA as a multiple-objective optimization problem, with each task represented by a domain loss. By aligning per-objective gradients, the authors aim to foster consensus between source and target domains. The procedure includes fine-tuning through prompt learning and penalizing gradient norms to ensure the model's generalization capability.
Framework and Implementation
The proposed method employs prompt learning on CLIP-based models, which utilize vision-language components to achieve high generalization. In the approach, domain-specific and domain-agnostic prompts are constructed. This allows for capturing shared knowledge across domains while maintaining specific features.
- Prompt Design:
- Domain-Agnostic Prompt Psh: Shared among all domains, includes class-specific tokens.
- Domain-Specific Prompts PS,i and PT: Tailored for individual source and target domains.
- Gradient Alignment Strategy:
- Gradient Norm Penalization:
- To counteract overfitting, the method penalizes the norm of gradients. This steers optimization toward flatter minima, thus enhancing the model's generalization potential.
Theoretical Analysis
The paper proposes an information-theoretic generalization bound to explain the benefits of prompt gradient alignment. Under the assumption of R-subgaussian loss functions, the analysis provides bounds on the generalization error and suggests reductions through gradient norm penalization and inter-domain gradient matching. This theoretical insight supports the intuition that gradient alignment and norm penalties can significantly improve prediction accuracy on target domains.
Experimental Validation
Empirical tests demonstrate that the proposed Prompt Gradient Alignment (PGA) approach surpasses existing UDA methods across various benchmarks like ImageCLEF, Office-Home, and DomainNet. Results indicate marked improvements in scenarios where CLIP's zero-shot performance is robust, and even in challenging domains like QuickDraw. Multi-source extensions of PGA, named MPGA, showcase state-of-the-art results through careful inter-domain gradient alignment across several domains.
Conclusion
The method "Enhancing Domain Adaptation through Prompt Gradient Alignment" defines a practical and theoretically grounded process for UDA by utilizing pre-trained vision-LLMs and adaptable prompt learning. Through gradient alignment and norm penalization, this approach achieves superior performance on benchmark datasets. Future explorations could explore sophisticated prompt designs to further narrow domain shifts, expanding the applicability and efficiency of the gradient alignment strategy.