- The paper introduces an automated feedback approach that uses compiler success and CLIP scores to filter and iteratively refine synthetic UI code data.
- It employs a multi-stage training pipeline combining supervised finetuning and preference alignment to boost both syntactic correctness and semantic relevance.
- Empirical results demonstrate a significant increase in compilation rates and competitive performance compared to proprietary models in UI code generation.
Automated Feedback for LLM-Based UI Code Generation: An Analysis of UICoder
Introduction
The paper "UICoder: Finetuning LLMs to Generate User Interface Code through Automated Feedback" (2406.07739) presents a systematic approach for improving LLMs in the domain of user interface (UI) code generation, specifically targeting SwiftUI. The authors address the scarcity of high-quality, domain-specific training data and the limitations of relying on expensive human feedback or proprietary model distillation. Their method leverages automated feedback—compilers and vision-LLMs—to iteratively filter, score, and refine self-generated synthetic datasets, enabling the finetuning of LLMs for robust UI code generation. The resulting UICoder models demonstrate strong empirical performance, approaching that of larger proprietary models, and outperform all other downloadable baselines.
Methodology
Multi-Stage Training Pipeline
The training pipeline consists of three primary stages: (1) base model selection, (2) supervised finetuning with automated feedback, and (3) preference alignment. The process is depicted in the following flow chart:
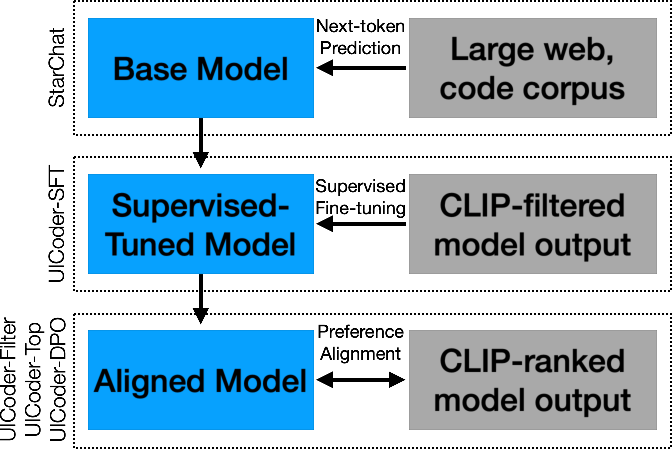
Figure 1: A flow chart showing an overview of the multi-step training process, including a base model, supervised-tuned model, and an aligned model.
Data Generation and Filtering
- Synthetic Data Generation: The base LLM (StarChat-Beta, a 15B parameter model) is prompted to generate SwiftUI code from a curated set of UI descriptions.
- Automated Filtering: Generated samples are filtered using:
- Compilation Success: Only compilable programs are retained.
- CLIP Score: A vision-LLM (CLIP) scores the semantic alignment between the rendered UI screenshot and the input description.
- De-duplication: Density-based clustering (DBSCAN) on CLIP embeddings removes visually redundant samples.
Iterative Self-Improvement
The filtered high-quality samples are used to finetune the LLM, which is then used to generate improved datasets in subsequent iterations. This bootstrapping process is repeated, progressively enhancing the model's ability to generate syntactically correct and semantically relevant UI code.
Preference Alignment
After supervised finetuning, three alignment strategies are explored:
- Direct Preference Optimization (DPO): Pairwise ranking of outputs using automated rules, with DPO applied for reward modeling.
- Top Output Supervision: Supervised finetuning on the highest-ranked output per prompt.
- Filter-then-Train: Additional iteration of the filter-then-train process without explicit ranking.
Training Infrastructure
The infrastructure comprises distributed GPU servers for code generation, macOS-based renderers for screenshot generation, and automated pipelines for scoring and dataset assembly. LoRA is used for parameter-efficient finetuning, and QLoRA is employed for DPO due to VRAM constraints.
Experimental Evaluation
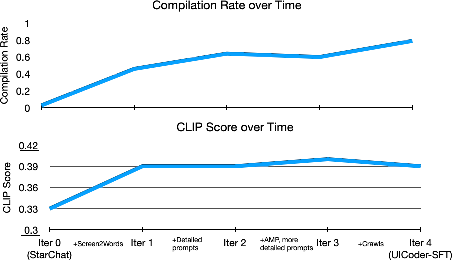
The iterative training process yields substantial improvements in both automated metrics:
The largest gains occur in the initial iterations, with diminishing returns in later stages. The inclusion of LLM-augmented and paraphrased descriptions, as well as platform diversity (iOS and Android), further enhances model robustness.
Baseline and Distillation Comparisons
UICoder models are benchmarked against proprietary (GPT-3.5, GPT-4), restricted (WizardCoder, MPT-30B-Chat), and permissive (StarChat-Beta, Octocoder) baselines. Additionally, the utility of UICoder-generated data for distillation is demonstrated by finetuning other LLMs (MPT-30B, MPT-7B, Octocoder) on the synthetic dataset.
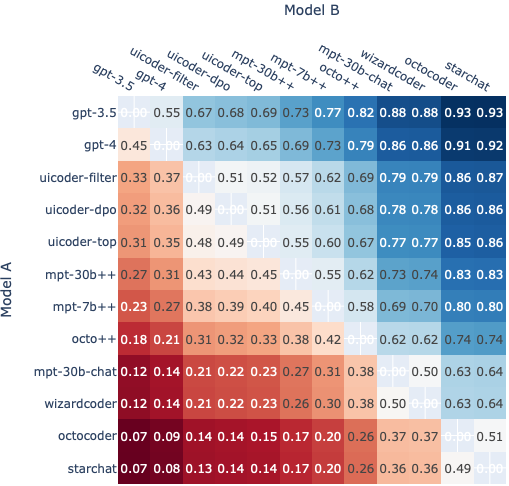
Figure 3: Matrix shows the predicted win probability of model A against model B. The training technique significantly improved the performance of an initially poorly-performing base model (StarChat) to competitive among larger proprietary models (UICoder).
Key findings:
- UICoder-Top achieves a compilation rate of 0.82, surpassing GPT-4 (0.81) and approaching GPT-3.5 (0.88).
- CLIP scores for UICoder variants (0.393–0.404) are close to proprietary models (0.416–0.419).
- Distilled models (e.g., MPT-30B++) also show marked improvements, validating the generalizability of the synthetic dataset.
Qualitative Analysis
The paper provides qualitative evidence of the model's ability to generate visually plausible and structurally complex UIs from natural language descriptions.
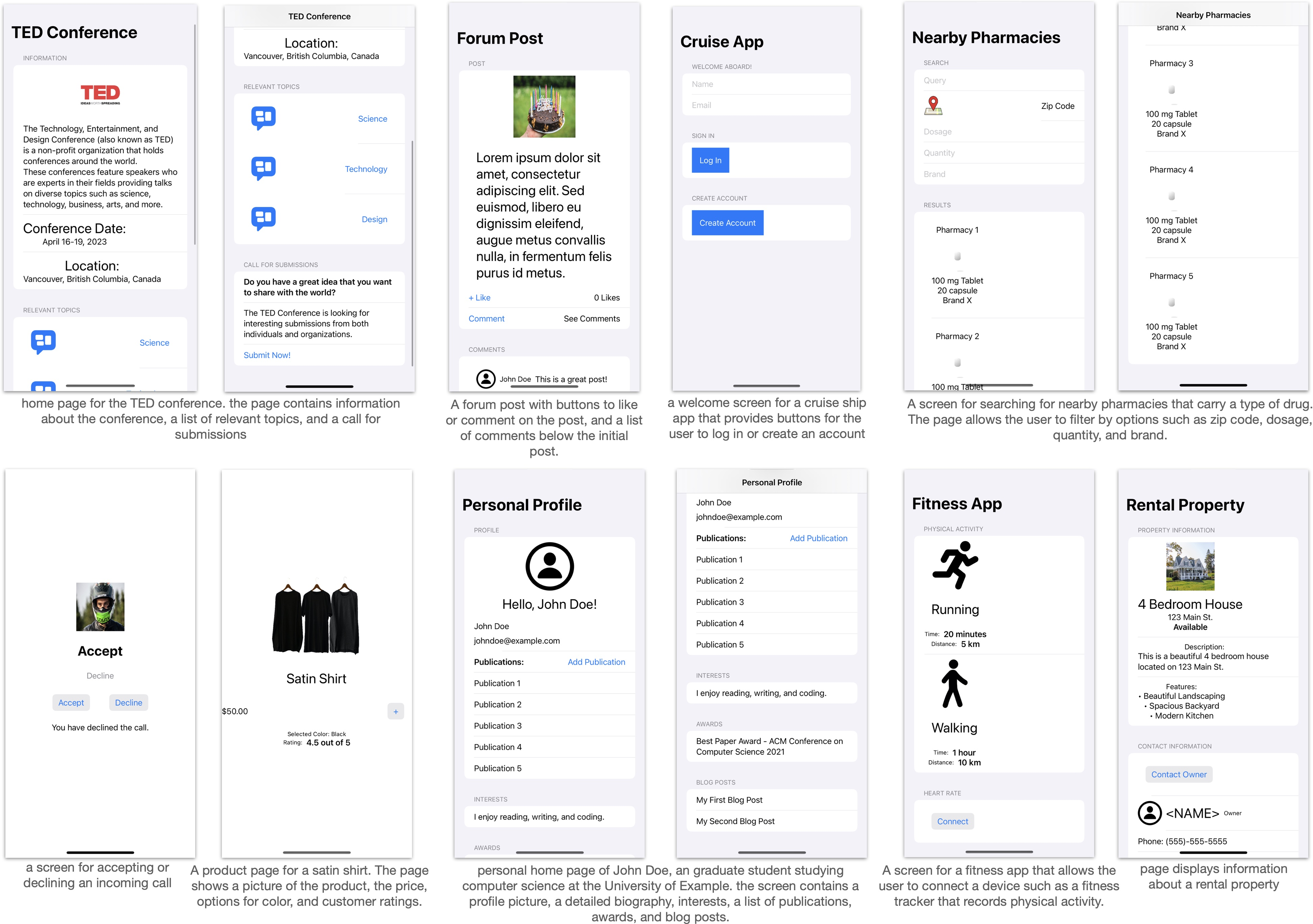
Figure 4: Screenshots rendered from SwiftUI code generated by the models. For illustration purposes, stock photos and icons were manually included; the model-generated code was not modified except for image asset names.
Limitations
The approach is subject to several limitations:
- Domain Specificity: The focus on SwiftUI limits immediate applicability to other toolkits, though the methodology is generalizable.
- Synthetic Data Bias: Reliance on self-generated data may constrain diversity and realism.
- Automated Feedback Granularity: Compilation success is a binary signal; CLIP scores may not capture subtle design or accessibility issues.
- Evaluation Scope: Human evaluation is limited to expert raters and static screenshots, potentially underrepresenting usability and interactivity.
Implications and Future Directions
Practical Implications
- Open-Source Model Enhancement: The method enables significant improvements to open-source LLMs in specialized domains without proprietary data or human annotation.
- Automated Feedback Loops: Compiler and VLM-based feedback can be integrated into other code generation or domain-specific LLM finetuning pipelines.
- Data Efficiency: The iterative, filter-then-train paradigm demonstrates strong data efficiency, especially in low-resource domains.
Theoretical Implications
- Self-Improvement via Automated Feedback: The results support the hypothesis that LLMs can be bootstrapped in underrepresented domains through self-generated, automatically filtered data.
- Preference Modeling: The limited gains from DPO and preference alignment suggest that further research is needed to optimize reward modeling in code generation tasks.
Future Work
- Generalization to Other Toolkits: Extending the methodology to web (React, HTML/CSS) or cross-platform (Flutter) UI code generation.
- Enhanced Feedback Signals: Incorporating program analysis, static verification, or more sophisticated VLMs for finer-grained feedback.
- Broader Evaluation: Scaling human evaluation to include end-users and interactive assessments; direct measurement of code quality and maintainability.
Conclusion
UICoder demonstrates that automated feedback from compilers and vision-LLMs can be effectively leveraged to finetune LLMs for UI code generation, circumventing the need for human-labeled data or proprietary model outputs. The approach yields models that are competitive with state-of-the-art proprietary systems and establishes a reproducible, scalable framework for domain-specific LLM enhancement. The release of model weights and synthetic datasets further facilitates research and application in UI code generation and related areas.