- The paper introduces AV-DiT, a model that leverages a frozen image diffusion transformer with lightweight, modality-specific adapters for joint audio and video generation.
- The paper employs temporal adapters and LoRA modules to ensure video temporal continuity and audio-image domain alignment, as evidenced by improved FVD, KVD, and FAD metrics.
- The paper demonstrates that pre-trained image models, when coupled with efficient adapters, can reduce parameter count and computational cost while delivering state-of-the-art multimodal synthesis.
Efficient Joint Audio-Visual Generation with AV-DiT
Introduction
AV-DiT introduces a parameter-efficient paradigm for audio-visual generative modeling, addressing the challenge of simultaneous high-quality audio and video generation. Prior approaches typically employ either single-modality diffusion transformers (DiTs) or rely on computationally intensive, fully trainable multimodal architectures. AV-DiT leverages a shared, frozen DiT backbone pre-trained on image-only data, augmenting it with lightweight, modality-specific adapters. This design delivers state-of-the-art (SOTA) performance on standard benchmarks while drastically reducing the amount of tunable parameters and computational resources required. The model demonstrates that image-only pre-training, with targeted parameter-efficient adaptations, is sufficient for joint audio-video synthesis.
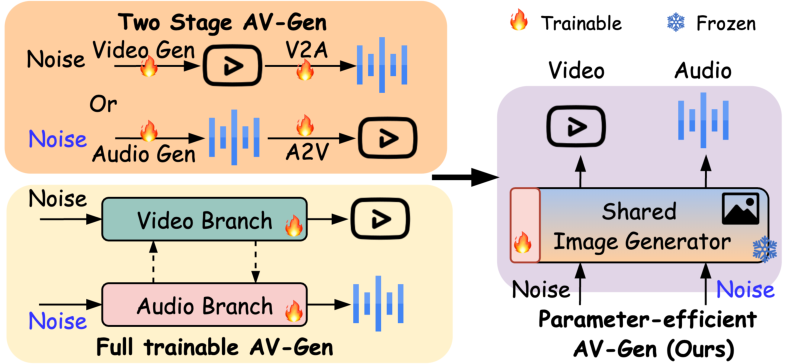
Figure 1: Comparison of the AV-Gen (AV-DiT) model with existing audio-video generative methods.
Architecture and Methodology
AV-DiT is structured around three core adaptations to the frozen image DiT backbone, enabling it to simultaneously synthesize temporally consistent video and realistic, scene-coherent audio:
- Temporal Consistency for Video Generation: Temporal adapters are inserted into the DiT to ensure frame-level continuity and motion coherence in the generated video sequences. Only the temporal adapters are trainable; the remainder of the backbone is frozen.
- Mitigating Audio-Image Domain Gap: For the audio branch, LoRA modules and lightweight adapters are injected into the self-attention projections, bridging the semantic and distributional gap between the image pre-training domain and the audio spectrogram target space.
- Audio-Visual Feature Interaction: Shared DiT blocks, augmented only with LoRA adapters, facilitate alignment and mutual conditioning between audio and video representations, supporting cross-modal coherence.
The overall training is conducted entirely in the latent space, utilizing pretrained variational autoencoders (VAEs) for both modalities and operating on noise-prediction objectives typical of the DDPM formulation.
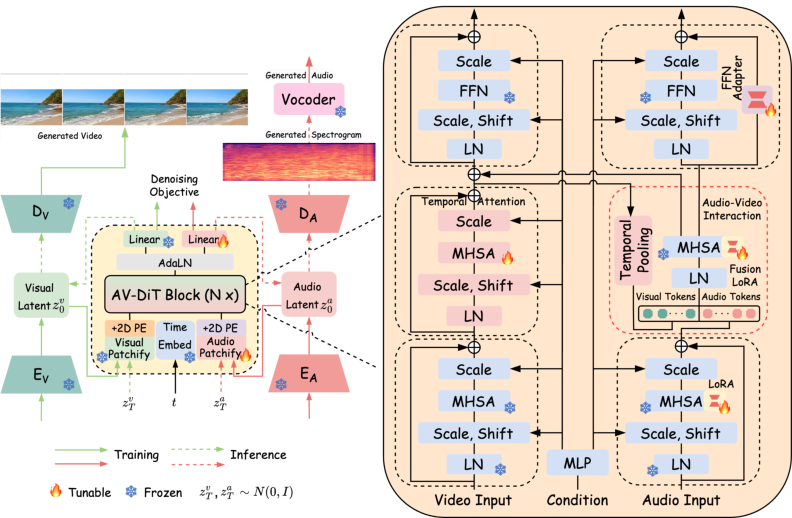
Figure 2: AV-DiT architecture: a shared, frozen pre-trained DiT backbone with modality-specific trainable adapters for efficient joint audio and video generation.
Experimental Evaluation
Experiments are performed on the AIST++ (music and dance) and Landscape (natural scene) datasets, benchmarking against SOTA methods including MM-Diffusion and Seeing and Hearing. Evaluation metrics include Frechet Video Distance (FVD), Kernel Video Distance (KVD) for video; Frechet Audio Distance (FAD) for audio; and inference speed. Training and evaluation adhere to rigorous standards, including five-run averages for statistical confidence.
Key empirical findings:
- On AIST++, AV-DiT achieves the best FVD (68.88), indicating robust temporal and visual fidelity. KVD (21.01) is competitive, with MM-Diffusion attaining a slightly lower value but at 2.7× the parameter count.
- In audio, AV-DiT delivers a lower FAD (10.17) than the primary baselines, despite its backbone never being pre-trained on audio data directly.
- For the Landscape dataset, AV-DiT attains FVD of 172.69, KVD of 15.41, and FAD of 11.17, outperforming Seeing and Hearing across all dimensions.
AV-DiT's parameter count is 159.91M, compared to MM-Diffusion's 426.16M, and it yields a 3× speedup in inference.

Figure 3: Qualitative comparison on Landscape scenes shows AV-DiT generating more coherent videos and audio spectrograms with fewer artifacts than MM-Diffusion.
Ablation Analysis
The ablation studies robustly demonstrate the architectural importance of each module:
- Removing temporal adapters causes FVD to degrade sharply from 68.88 to 365.71, confirming their critical role for temporal video fidelity.
- Elimination of audio adapters and LoRA modules in the audio branch results in moderate but consistent drops across all metrics, corroborating their necessity for effective domain adaptation.
- Self-attention-based fusion outperforms cross-attention, achieving better FVD/FAD with fewer trainable parameters, indicating that efficient multimodal alignment emerges from shared attention mechanisms paired with lightweight adapters.
Qualitative Results
Visual and auditory inspection reveals that AV-DiT consistently generates videos with realistic motion and scene-aware soundtracks. Generated spectrograms and waveform reconstructions are less noisy, and exhibit structures more faithfully matching scene events (e.g., the synchrony of dance steps and music, or environmental sounds in landscape scenes).
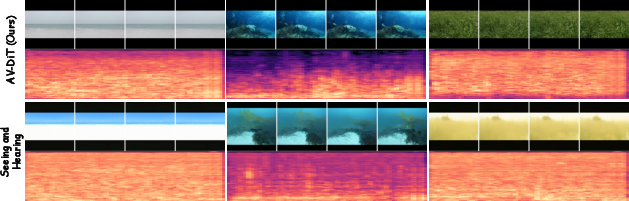
Figure 4: AV-DiT generation results on Landscape; generated video and sound are more coherent and realistic compared to Seeing and Hearing.
Implications and Future Directions
AV-DiT decisively demonstrates that multimodal generation does not require monolithic, densely trainable backbones. Instead, the transfer of pre-trained image foundation models to new modalities is not only viable, but efficient and empirically effective, provided that modality-specific adapters are carefully engineered. This paradigm enables resource-constrained research environments to participate in high-quality multimodal model development.
The modularity and efficiency of AV-DiT invite extensions in several directions:
- Conditional generation (class or text conditioned) can be incorporated via minor adjustments, leveraging the same frozen backbone.
- Further efficiency can be realized via quantization, pruning, or acceleration of the diffusion sampling process to meet real-time generation demands.
- The architecture is extensible to additional sensory modalities, contingent on the engineering of appropriate adapters.
- Ethical considerations on the deployment of such generative models, particularly in creative, educational, or accessibility contexts, will benefit from continued research especially concerning potential misuse of synthetic content.
Conclusion
AV-DiT establishes a new benchmark for efficient, high-fidelity joint audio and video synthesis, validating that an image-pretrained diffusion transformer, augmented with a minimal set of modality-specific adapters, surpasses prior state-of-the-art both in quality and computational footprint. This approach materially advances the field of multimodal generative modeling and provides a scalable framework for further research in efficient, adaptable, and high-quality sensory content generation (2406.07686).