- The paper introduces a novel single-codebook design that enhances TTS efficiency, outperforming multi-codebook codecs on metrics like STOI and PESQ.
- It employs a VQ-VAE architecture with a Conformer encoder and convolutional decoder to compactly encode Mel Spectrograms while extracting robust phonetic features.
- Extensive experiments show that Single-Codec achieves high-quality, zero-shot speech synthesis at a reduced bandwidth of 304 bps while improving intelligibility.
The paper "Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation" (2406.07422) introduces a novel approach named Single-Codec for efficient speech generation. Typical multi-codebook speech codecs utilized in LLM-based TTS systems suffer from inefficiency due to multi-sequence discrete representation. Single-Codec offers a solution by employing a single-codebook representation, enhancing performance while reducing bandwidth.
Methodology
Architecture of Single-Codec
Single-Codec leverages a VQ-VAE-based architecture to encode and reconstruct speech using a Mel Spectrogram. This setup differentiates itself from traditional raw waveform approaches, allowing more compact and efficient speech information preservation. Key components of the architecture include a Conformer-based encoder and a convolution-based decoder facilitated by vector quantization for high-quality Mel Spectrogram reconstruction and yielding discrete speech codes.
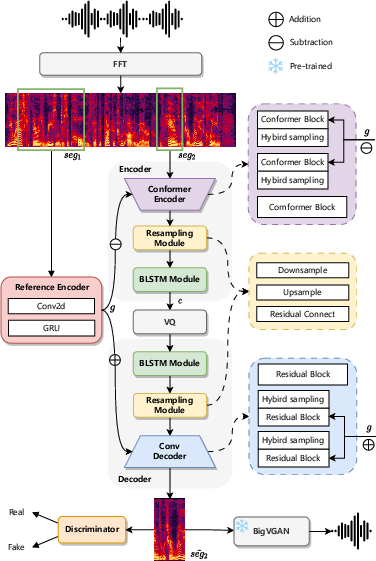
Figure 1: The architecture of Single-Codec.
Encoders and Decoders
The suite of enhancements includes a global reference encoder tailored for decoupling time-invariant speech information, which results in better phonetic information extraction in single-codebook discrete units. The reference encoder processes input segments of 600 frames, providing robust global features essential for capturing precise acoustic details.
Contextual and Hybrid Sampling Modules
To bolster speech content modeling, a BLSTM module is integrated, facilitating improved contextual correlations between adjacent frames. Additionally, a hybrid sampling module that combines convolution with pooling (for downsampling) and transposed convolution with replication (for upsampling) effectively minimizes sampling loss, bridging the gap left by conventional sampling methods.
Single-Codec incorporates a resampling module aimed at refining the phonetic relevance of extracted features. By employing downsampling for local modeling and uplifting quality via residual connections, the model ensures information extracted holds reduced temporal variance but higher phonetic fidelity, contributing to better clustering within the codebook.
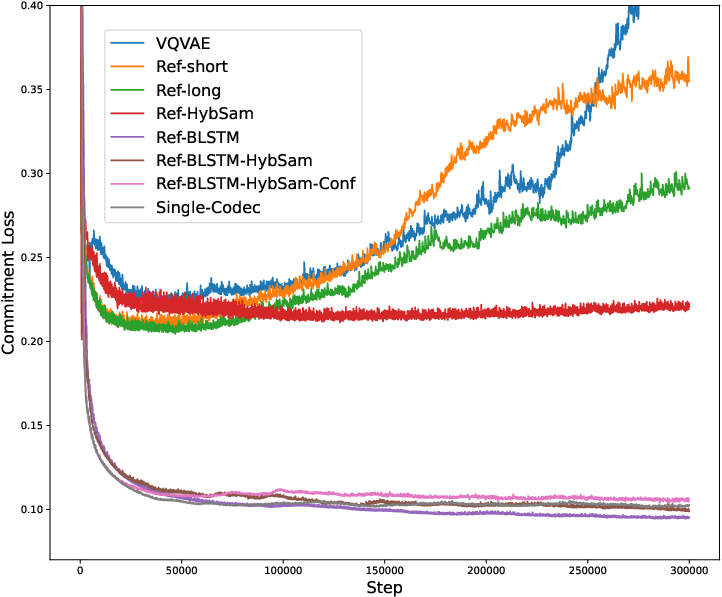
Figure 2: The commitment loss of different codecs while training.
Experiments and Evaluation
Evaluation Metrics
The performance of Single-Codec is corroborated through extensive evaluations leveraging metrics such as STOI, PESQ, MCD, UTMOS, and speaker similarity (SPK) scores. These metrics captured both objective speech reconstruction fidelity and subjective listener experience across various codec settings.
When compared with established multi-codebook codecs like EnCodec and TiCodec, Single-Codec showcases superior reconstruction performance at a reduced bandwidth requirement of 304 bps. The single-sequence approach not only challenges the multi-sequence limitations but also promises higher intelligibility and natural speech synthesis.
Zero-shot TTS and Ablation Studies
Empirical results confirm Single-Codec as a capable codec for high-quality TTS, particularly in zero-shot scenarios. The ablation studies further spotlight the contributions of individual components, such as the reference encoder and sampling modules, in refining codec performance and stability.
Conclusion
The introduction of Single-Codec marks a significant stride towards efficient and high-performance speech generation. It offers a streamlined process for encoding and decoding speech, without the complexity seen in existing multi-codebook architectures. By optimizing for a single-sequence model, it opens avenues for further advancements in LLM-based TTS applications with potential expansions into multilingual settings where efficient speech synthesis remains intricate. Future work could focus on refining these codec architectures to optimize computational efficiency further while maintaining high fidelity output.