- The paper introduces OmegaPRM, a novel MCTS-based approach that automates process supervision for intermediate reasoning steps in LLMs.
- It employs a divide-and-conquer strategy to annotate over 1.5 million process annotations, leading to a 36% improvement on the MATH benchmark.
- The study demonstrates scalable, cost-effective process supervision that enhances LLM reasoning in complex mathematical tasks.
Automated Process Supervision for Enhanced Mathematical Reasoning in LLMs
Improving the mathematical reasoning capabilities of LLMs represents a significant research challenge, particularly for tasks demanding complex multi-step reasoning such as solving math problems or coding. This paper explores the application of process supervision to refine the intermediate reasoning steps of LLMs through a novel Monte Carlo Tree Search (MCTS) algorithm named OmegaPRM.
Process Supervision and its Implementation
Chain-of-Thought (CoT) prompting has demonstrated efficacy in breaking down reasoning tasks into sequential steps, mimicking human cognitive processes. However, CoT’s performance can be hindered by issues related to greedy decoding strategies. Existing methods, such as self-consistency prompting and supervised fine-tuning with question-solution pairs, provide enhancements but fail to comprehensively address these limitations due to the inadequacy in rewarding intermediate steps.
Outcome Reward Models (ORM) address the need to verify output correctness, yet they focus on final answer verification rather than supervising the intermediate reasoning steps. Addressing this gap, Process Reward Models (PRM) introduce the concept of process supervision which provides more granular feedback by rewarding or penalizing each reasoning step, thereby enhancing the model's reasoning capabilities.
Developing high-quality process supervision data historically relied on human annotations or computationally intensive per-step Monte Carlo Estimation methods. To overcome these challenges, the paper presents OmegaPRM, an MCTS-based approach that automates this data collection process effectively.
Monte Carlo Tree Search (MCTS) and OmegaPRM
OmegaPRM adapts the MCTS algorithm for process supervision. It uses a novel divide-and-conquer strategy to efficiently locate and annotate the first error in a CoT reasoning tree. This method allows the generation of more than 1.5 million process annotations, forming the basis for training a highly effective PRM.
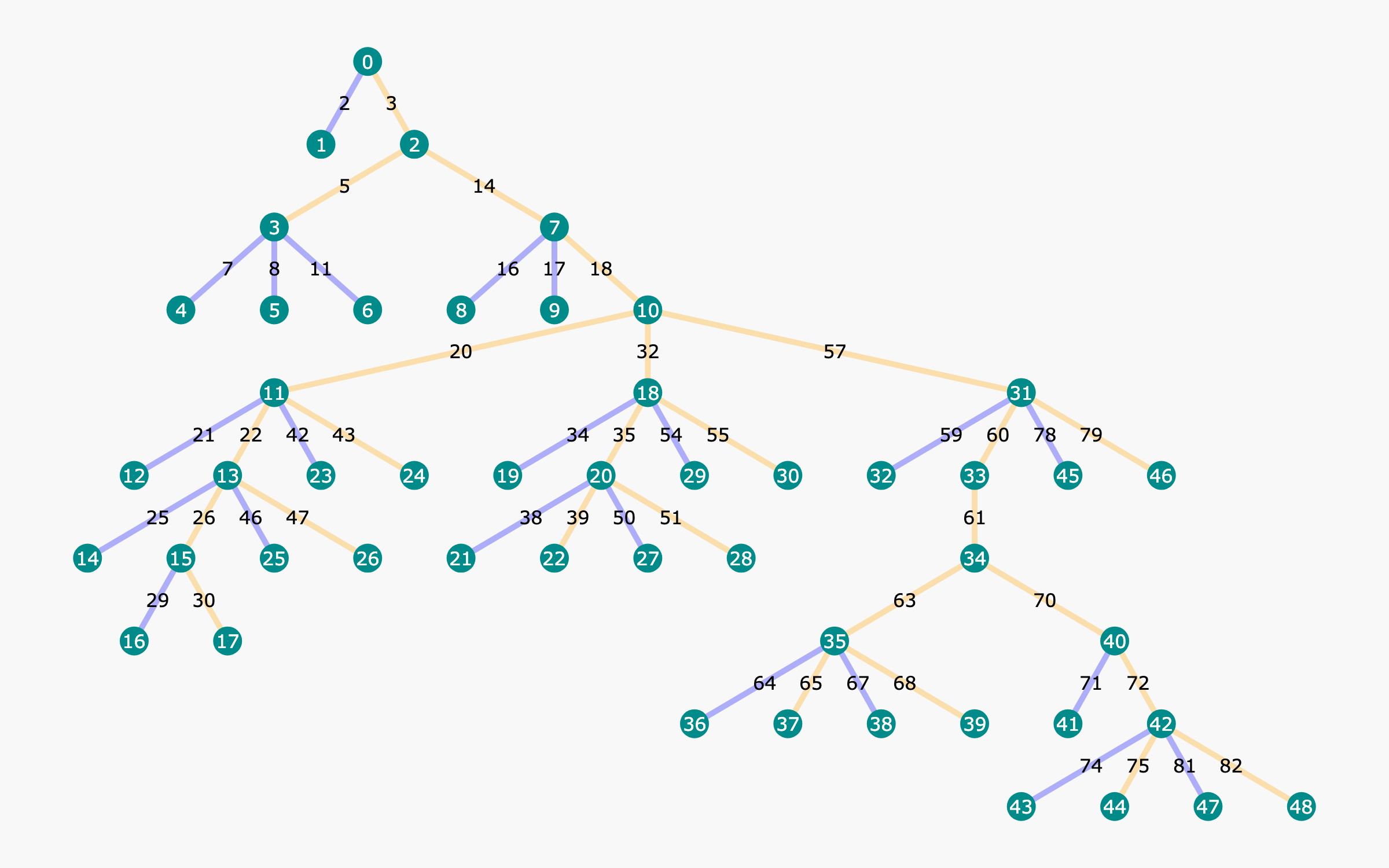
Figure 1: Example tree structure built with our proposed OmegaPRM algorithm.
The algorithm constructs a reasoning path tree, where each node represents partial solutions within the CoT framework, evaluated using Monte Carlo simulations (Figure 2).
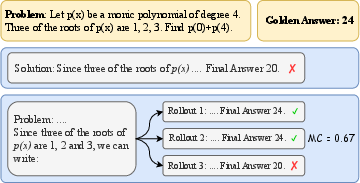
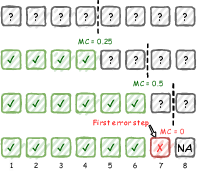
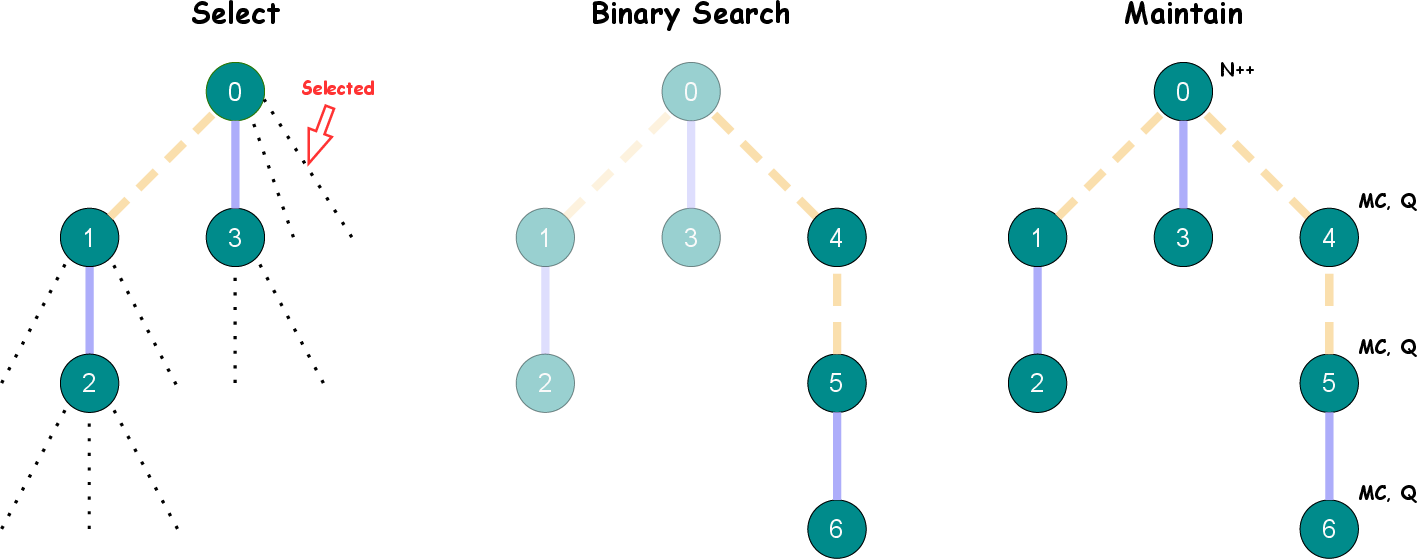
Figure 2: Monte Carlo estimation of a prefix solution.
This approach not only improves annotation efficiency but also offers a scalable solution readily applicable to various LLM reasoning tasks, significantly reducing reliance on extensive human supervision.
An empirical analysis demonstrates that PRMs utilizing OmegaPRM-derived annotations outperform alternative datasets such as PRM800K and Math-Shepherd in reasoning accuracy. The weighted self-consistency algorithm, combined with PRM outcomes, achieved a notable 69.4% success rate on the MATH benchmark, illustrating a 36% improvement over the baseline model performance.
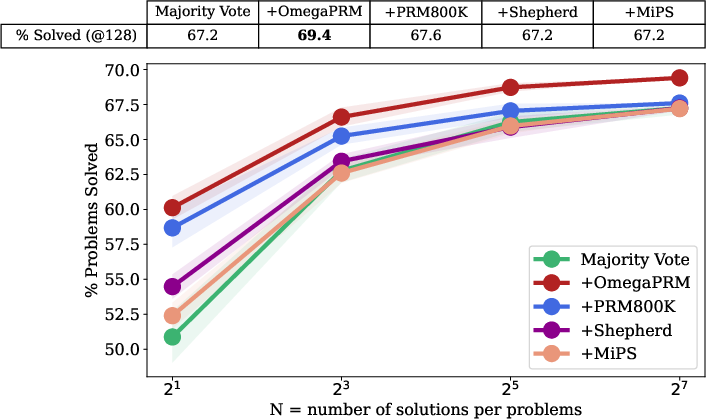
Figure 3: A comparison of PRMs trained with different process supervision datasets, evaluated by a PRM-weighted majority voting.
Additionally, classical tree search-based state transition models and data-driven heuristics ensure optimal tree traversal while balancing exploration and exploitation decisions essential for reasoning step verification.
Implications and Future Prospects
OmegaPRM highlights the potential of automated process annotation to significantly elevate the reasoning abilities of LLMs in complex mathematical tasks. The efficiency of the OmegaPRM method marks an advancement towards economically viable and computationally efficient process supervision frameworks.
In terms of future explorations, integrating human insights with automated annotations could offer comprehensive and nuanced process supervision. Further adaptations may encompass extending the OmegaPRM utility beyond structured tasks, addressing open-ended challenges.
Conclusion
OmegaPRM represents a critical step toward advancing the reasoning proficiency of LLMs by leveraging an innovative automation strategy in process supervision. This work paves the pathway for future research into cost-effective, high-quality data collection methods capable of scaling up integrated reasoning models, potentially transforming their applicability in multifaceted domains.