- The paper introduces ALURE, an asynchronous framework that converts multimodal user activity into compact embeddings for optimized ad retrieval.
- It employs a custom Transformer-like model with modality-specific modules and advanced feature encodings to capture temporal and contextual nuances.
- Online A/B tests demonstrate significant gains in ad engagement by leveraging user similarity graphs constructed from these embeddings.
Async Learned User Embeddings for Ads Delivery Optimization: Technical Summary and Implications
Introduction and Motivation
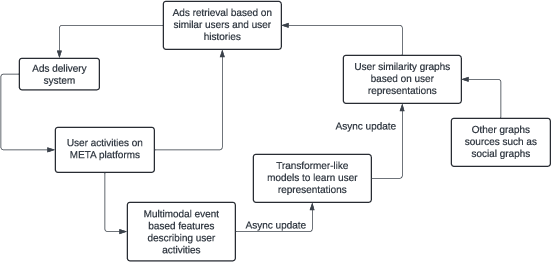
The paper presents a scalable framework for learning high-fidelity user embeddings asynchronously from multimodal, sequential user activity data, with the goal of optimizing large-scale ads delivery systems. The approach, termed Async Learned User Representation Embeddings (ALURE), leverages a custom Transformer-like architecture to encode diverse user behaviors and fuses these representations into a compact embedding space. These embeddings are then used to construct user similarity graphs, which drive candidate ad retrieval in a multi-stage ranking pipeline. The system is designed to operate at the scale of billions of users, with asynchronous updates to balance computational efficiency and model freshness.
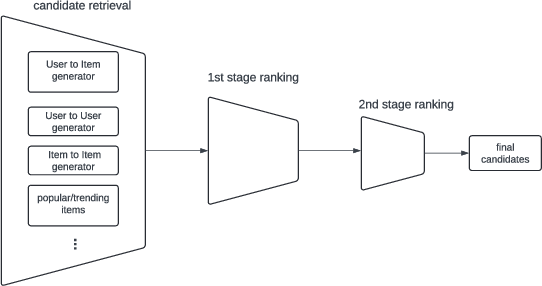
Figure 1: Ads delivery funnel with multi-stage ranking.
Multimodal Sequential User Representation Learning
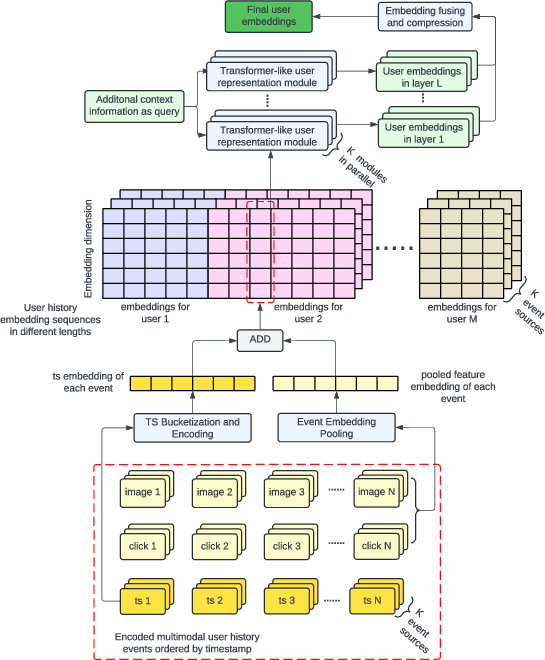
The core of the ALURE system is the transformation of rich, multimodal user activity logs into dense, informative embeddings. User histories include event-based features such as ad clicks, metadata, user-generated text, and visual content (e.g., images, videos encoded via RQ-VAE). These are treated as timestamped sequences, capturing both content and temporal dynamics.
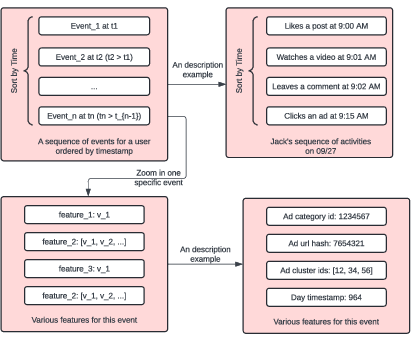
Figure 2: An example of user sequence feature.
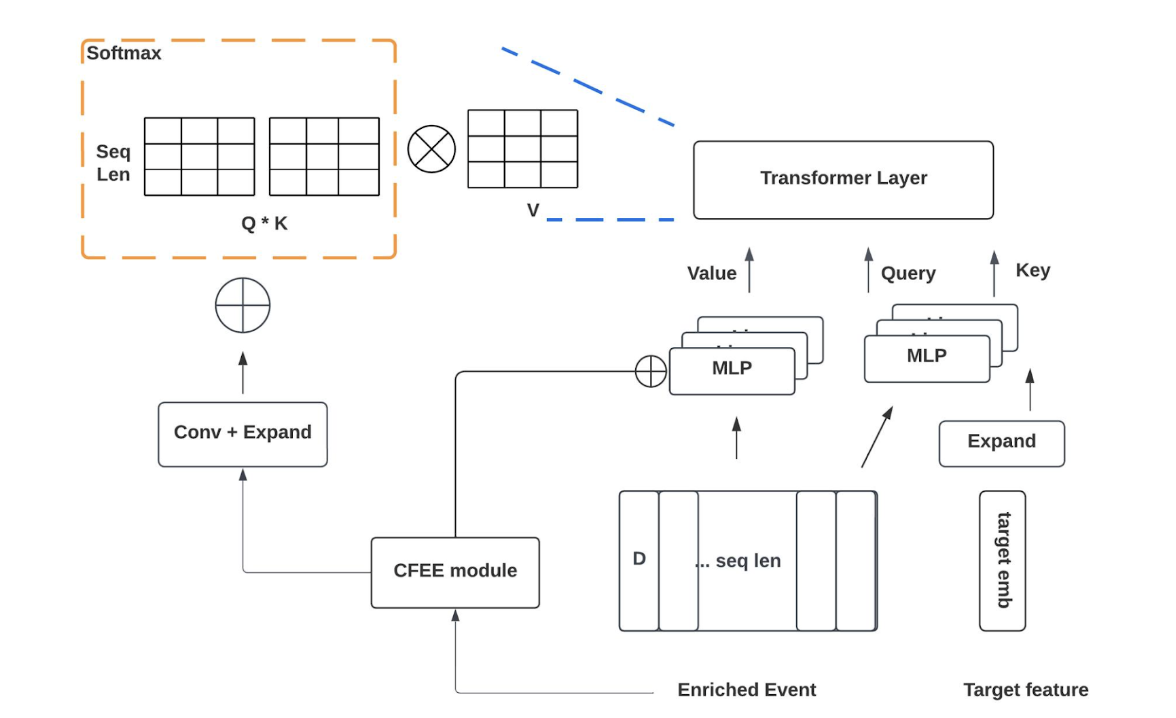
A custom Transformer-like model processes these sequences. Unlike standard Transformers, the architecture incorporates several domain-specific enhancements:
To address the high dimensionality of the resulting embeddings, a compression module is introduced. This module employs ResNet-style skip connections and/or an additional Transformer-like layer to aggregate and compress hundreds of intermediate embeddings into a compact set, reducing storage and computational costs for downstream graph construction.
Asynchronous Embedding Computation and System Scalability
A key design choice is the asynchronous computation and logging of user embeddings. Rather than computing embeddings in real time, the system precomputes and periodically refreshes them, decoupling embedding generation from online serving. This enables:
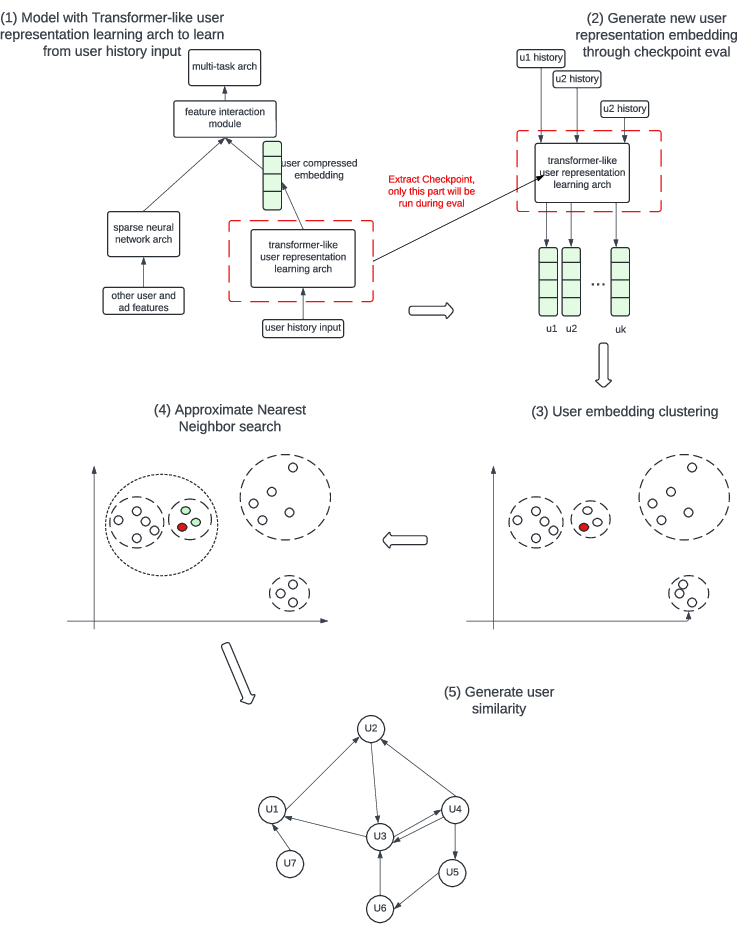
User Similarity Graph Construction
The ALURE embeddings serve as the basis for constructing user similarity graphs, which are central to the candidate retrieval stage in ads delivery. The process involves:
Ads Retrieval via User Graphs
The constructed user similarity graph is leveraged as a u2u generator in the candidate retrieval stage. For a given user, ads engaged by similar users are retrieved as candidates. Two retrieval strategies are employed:
- Direct ad engagement: Ads clicked or converted by a similar user are recommended.
- Account-level expansion: If a user converts on a product under an ad account, other ads from the same account are also considered.
This approach augments traditional retrieval sources (e.g., social graphs, historical interactions), increasing the diversity and relevance of candidate ads.
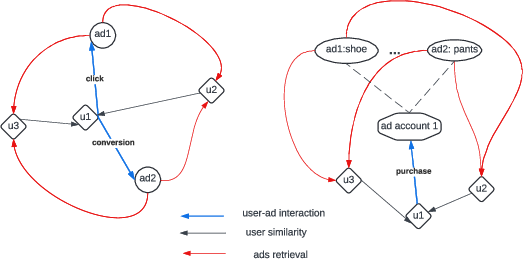
Figure 7: Retrieval Related Ads to similar users.
Experimental Results
Offline Evaluation
Embedding quality was validated by incorporating ALURE embeddings as features in production ads ranking models. Statistically significant improvements in Normalized Cross Entropy (NE) were observed:
- CTR tasks: 0.10–0.12% NE gain
- CVR tasks: 0.37% NE gain
These gains are non-trivial at production scale, indicating that the embeddings capture meaningful user preference signals.
Online A/B Testing
A/B tests compared three system variants:
- Control: Baseline retrieval without u2u graph augmentation.
- Version 1: Retrieval augmented with BFF (user following) and PPR (Personalized PageRank) graphs.
- Version 2: Version 1 plus ALURE-based user similarity graph.
Results:
- Version 1: -0.05% change (neutral, within statistical noise)
- Version 2: +0.28% statistically significant improvement in the primary online metric (total value generated from ads engagement).
The number of ads retrieved per user from ALURE was capped at 1500, with the distribution shown below.
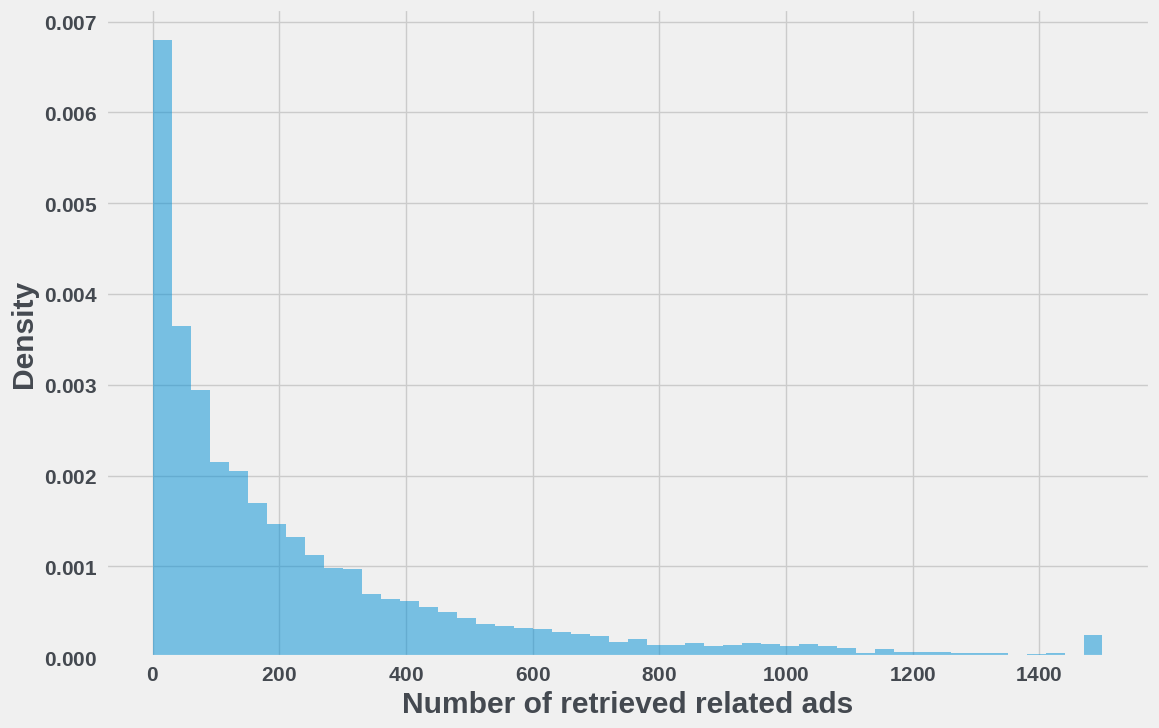
Figure 8: Distribution of user level number of retrieved related ads.
Implementation Considerations and Trade-offs
- Model Complexity vs. Latency: The asynchronous update mechanism allows for more complex embedding models without incurring online latency penalties, but introduces a trade-off between embedding freshness and computational cost.
- Embedding Compression: Aggressive compression is necessary for scalability but may risk information loss; the use of skip connections and additional interaction layers mitigates this.
- Graph Construction Frequency: Daily graph updates balance responsiveness to user behavior changes with infrastructure constraints; more frequent updates may be warranted in highly dynamic environments.
- Retrieval Diversity: The u2u graph approach increases candidate diversity but may introduce cold-start issues for users with sparse histories; hybrid retrieval strategies are recommended.
Theoretical and Practical Implications
The ALURE framework demonstrates that high-fidelity, asynchronously updated user embeddings can be effectively leveraged for large-scale retrieval in ads delivery systems. The integration of multimodal, temporally-aware sequence modeling with scalable graph construction provides a robust foundation for personalization at web scale. The observed online gains, while modest in absolute terms, are significant in the context of mature, high-traffic production systems.
Theoretically, the work highlights the importance of temporal and multimodal feature fusion, as well as the utility of asynchronous, decoupled representation learning in industrial recommender systems. The approach is extensible to other domains requiring scalable, up-to-date user modeling (e.g., content recommendation, social feed ranking).
Future Directions
Potential avenues for further research and development include:
- Real-time or near-real-time embedding updates for highly dynamic user segments.
- Adaptive refresh intervals based on user activity patterns or system load.
- Joint optimization of embedding learning and graph construction to further improve retrieval quality.
- Integration with LLMs for richer semantic user representations.
- Exploration of alternative graph construction and retrieval algorithms (e.g., GNN-based approaches).
Conclusion
The ALURE system provides a scalable, effective solution for learning and deploying high-quality user embeddings in large-scale ads delivery pipelines. By combining multimodal, temporally-aware sequence modeling with efficient, asynchronous computation and graph-based retrieval, the approach delivers measurable improvements in both offline and online metrics. The framework sets a strong precedent for future work in scalable, representation-driven personalization systems.