- The paper presents a novel benchmark evaluating domain-specific RAG models using Chinese enrollment data.
- It employs six key evaluation metrics, including structural analysis, time-sensitive problem solving, and noise robustness.
- Experimental results reveal the superiority of HTML-based data retrieval in reducing hallucinations and enhancing model accuracy.
Overview of "DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation"
"DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation" introduces a benchmark designed to evaluate the effectiveness of Retrieval-Augmented Generation (RAG) models in domain-specific contexts, such as college enrollment systems. The authors focus on evaluating LLMs in scenarios where domain-specific knowledge is critical, highlighting challenges associated with providing expert information that is not typically included in general pre-training datasets like Wikipedia.
Introduction to RAG and Benchmark Creation
The paper sets the context by addressing the limitations of LLMs, particularly their tendency for hallucination and difficulty in updating real-time information. Retrieval-Augmented Generation (RAG) models are proposed as methodologically superior by incorporating external data through information retrieval systems to enhance domain-specific knowledge and reduce fabrication.
The benchmark named DomainRAG focuses on Chinese university enrollment data, showcasing the importance of tailored LLM settings for specific domains. Six key abilities pertinent to effective RAG systems—conversational facilitation, structural analysis, faithfulness, denoising, time-sensitive problem solving, and multi-document interaction—are assessed using this benchmark.
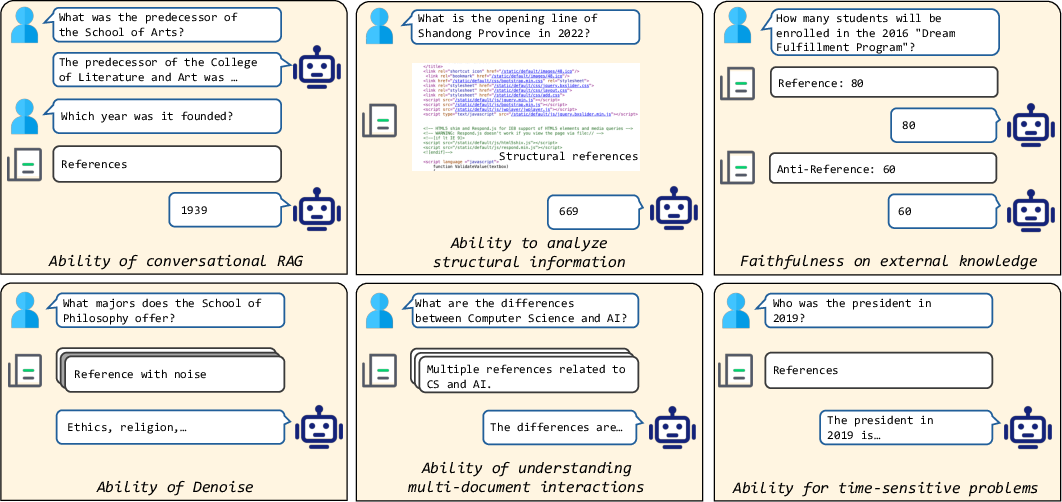
Figure 1: Important abilities for RAG models.
Dataset Construction and Evaluation Criteria
The dataset comprises various sub-datasets targeting the aforementioned abilities. These sub-datasets include conversational QA, structural QA, faithful QA, noisy QA, time-sensitive QA, and multi-document QA, each designed to rigorously test specific capabilities of RAG models.
The document corpus from enrollment websites in China comprises both HTML and text data, with the former allowing the evaluation of structural information analysis capabilities. For the implementation scope, both golden references (man-made annotations) and anti-references (modified answers counter to textual data) are utilized to juxtapose the performance of LLMs in adhering to external factual knowledge.
Experimental Results
The empirical analysis involves evaluating well-known models like Llama, Baichuan, ChatGLM, and GPT occurrences. It reveals that LLMs underperform on domain-specific queries without external help, affirming the necessity for RAG systems. The golden reference setting versus close-book trials indicates substantial reliance on external knowledge for accurate expert-level responses.
Advanced results show that HTML content provides superior performance compared to pure text for models pre-trained with structured information (e.g., GPT-3.5), emphasizing the significance of structural information comprehension in achieving higher accuracy.
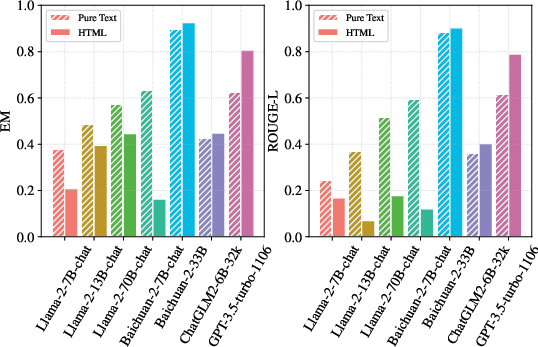
Figure 2: The experiments on the structural QA dataset.
Additionally, noise robustness analysis through blended reference trials highlights RAG models' sensitivity to noise and document order, suggesting improvements in retrieval-engine robustness and ordering strategies.
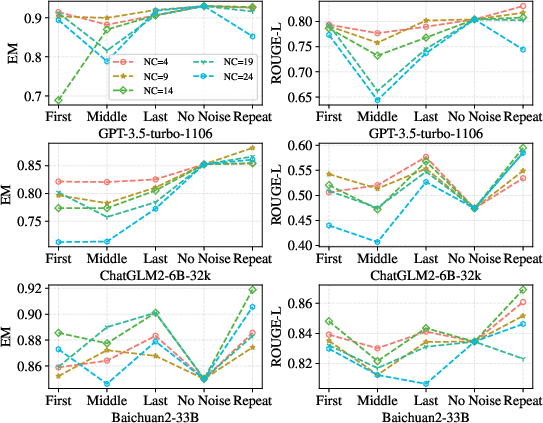
Figure 3: Experiments in different noise ratio settings.
Implications and Future Directions
The evaluation substantiates the critical role RAG models play in bridging the gap between LLM capabilities and domain-specific applications. It calls for ongoing refinement in conversational history understanding, structural information leveraging, denoising efficiency, and multi-document interaction handling.
Further appliance of this benchmark could steer enhancements in practical implementations of RAG by integrating more sophisticated retrieval methods and fostering LLM adaptations receptive to dynamic domain-specific knowledge updates.
Conclusion
The development and analysis of the DomainRAG benchmark provide essential insights into the performance and adaptability of retrieval-augmented generation systems in specified contexts. RAG models hold potential for amplifying LLM utility across various expert-driven fields by minimizing inaccuracy and enriching domain-specific content interpretation. As the exploration of such benchmarks expands, future work might focus on optimizing retrieval mechanisms and model training methodologies for even finer semantic and factual precision.

