- The paper introduces a latent diffusion model that achieves zero-shot any-to-any singing voice conversion by mitigating timbre leakage using a novel singer guidance mechanism.
- It leverages VAE pre-training with a DDPM-style diffusion process and classifier-free guidance to ensure accurate latent representation conversion.
- Experimental evaluations on the OpenSinger dataset demonstrate improved naturalness and similarity metrics across both seen and unseen scenarios.
Summary of the Paper "LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance"
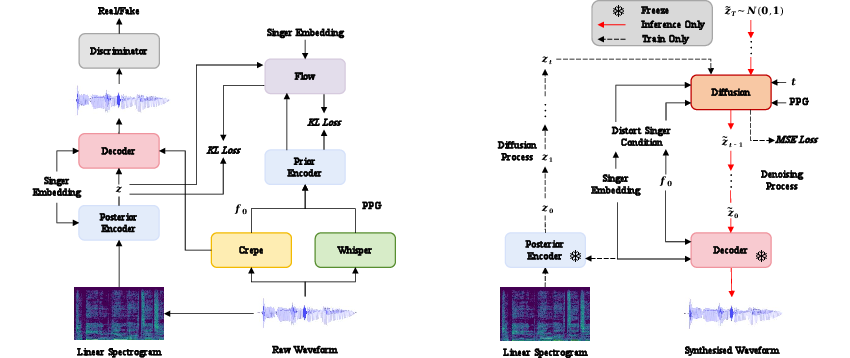
The paper introduces the Latent Diffusion Model for Singing Voice Conversion (LDM-SVC), a novel approach addressing the challenge of zero-shot any-to-any singing voice conversion utilizing a latent diffusion model with singer guidance capabilities. The primary goal of this approach is to convert a singing voice from one singer to another while minimizing timbre leakage, which often leads to the converted voice sounding like the original singer. This is achieved through the use of a latent diffusion model applied in the hidden space, along with a classifier-free guidance mechanism.
Pre-training with Variational Autoencoder
The initial step in the process involves pre-training a Variational Autoencoder (VAE) using the So-VITS-SVC framework, based on the VITS framework. This framework is comprised of three key components: the posterior encoder, the prior encoder, and the decoder.
Once trained, the posterior encoder compresses the linear spectrogram to generate latent representations used as prediction targets for the latent diffusion model.
Latent Diffusion Process
The core of LDM-SVC lies in utilizing a latent diffusion model for the transformation of the latent representations. This process follows the Denoising Diffusion Probabilistic Models (DDPM) method, characterized by:
- Forward Process: Transforming the original data distribution into a standard Gaussian distribution using a predetermined noise schedule.
- Denoising Process: Iteratively sampling the target data from Gaussian noise by reversing the forward process through a parameterized denoising distribution.
The configurations used for the diffusion process align with DiffSVC, with adaptations such as predicting latent representations directly from Gaussian White Noise during inference, enhancing consistency and reducing mismatches between training and testing phases.
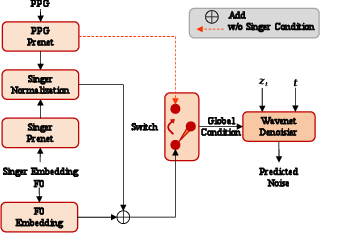
Singer Guidance Mechanism
To further decouple timbre information from source audio, the paper introduces a singer guidance mechanism based on classifier-free guidance strategies. This mechanism uses speaker condition layer normalization and operates by training the model to predict both conditional and unconditional diffusion scenarios:
The model performs better by linearly combining predictions, allowing for more effective suppression of original timbre attributes during the conversion process.
Experimental Evaluation
The system was validated using the OpenSinger dataset, demonstrating superior performance in zero-shot scenario tasks compared to existing models. Evaluation using subjective (SMOS, NMOS) and objective (SSIM, FPC) metrics revealed:
- Improved similarity and naturalness due to the latent diffusion approach.
- Enhanced conversion outcomes using the singer guidance mechanism, especially in zero-shot conditions.
Notably, the LDM-SVC system achieved closer results in both seen and unseen scenarios, confirming its efficacy across various test conditions.
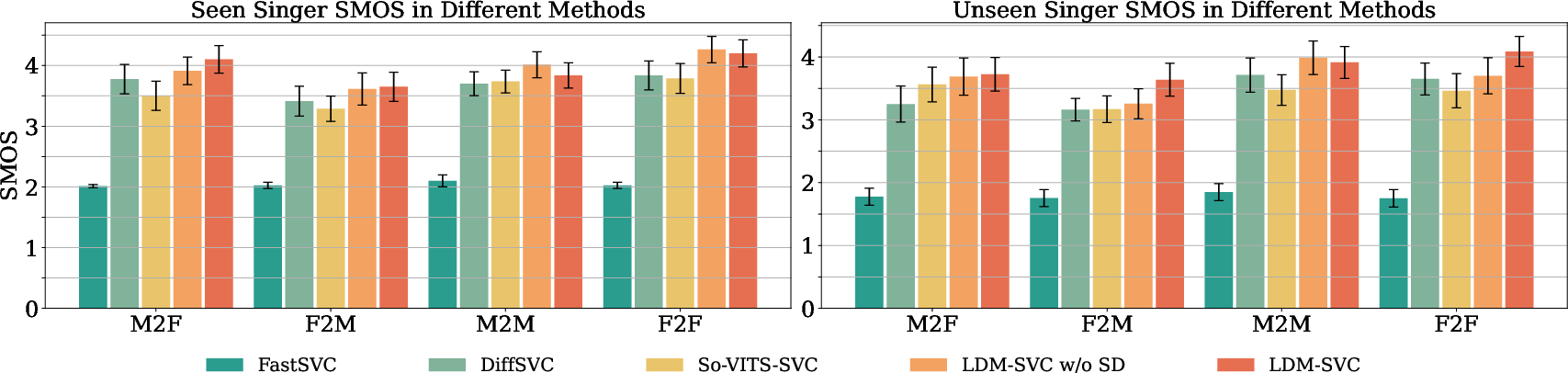
Figure 3: Detailed SMOS for seen and unseen scenarios, including M2M, M2F, F2M, and F2F.
Conclusion
LDM-SVC proposes a sophisticated mechanism for singing voice conversion, demonstrating significant improvements in handling timbre leakage. The novel interplay of latent diffusion and classifier-free guidance positions it as a competitive solution for zero-shot SVC tasks. As future work, cross-domain SVC tasks, such as converting speech into singing voice, are potential avenues for exploration, addressing limitations present in low-resource environments.