- The paper introduces a novel method that uses fine-tuned LLMs to post-process and correct speaker mislabeling in ASR-generated transcripts.
- It employs an ensemble of ASR-specific models fine-tuned via QLoRA to generalize across different systems and significantly reduce error metrics.
- The approach enhances practical applications by achieving improved diarization accuracy without increasing inference time.
LLM-Based Speaker Diarization Correction: A Generalizable Approach
The paper "LLM-based speaker diarization correction: A generalizable approach" (2406.04927) explores the application of LLMs to improve speaker diarization accuracy in transcripts generated by Automated Speech Recognition (ASR) systems. The study presents a post-processing strategy leveraging fine-tuned LLMs to correct speaker mislabeling and offers a pathway towards achieving ASR-agnostic diarization tools.
Introduction and Background
Speaker diarization, the process of identifying distinct speakers in audio recordings, is crucial for accurate conversation interpretation, particularly in domains like medical transcription and legal proceedings. Existing diarization solutions often involve acoustic analysis through methods like Pyannote or x-vector clustering. End-to-end systems integrating transcription with diarization are also popular but have limitations due to dependencies on specific ASR outputs.
ASR systems such as AWS Transcribe, Azure Speech to Text, and WhisperX vary in their diarization techniques and accuracy. The inconsistency across ASRs affects the generalizability of post-processing correction methods. To address these challenges, the authors fine-tune LLMs using the Fisher corpus, a vast dataset of conversational transcripts, to understand and correct diarization errors.
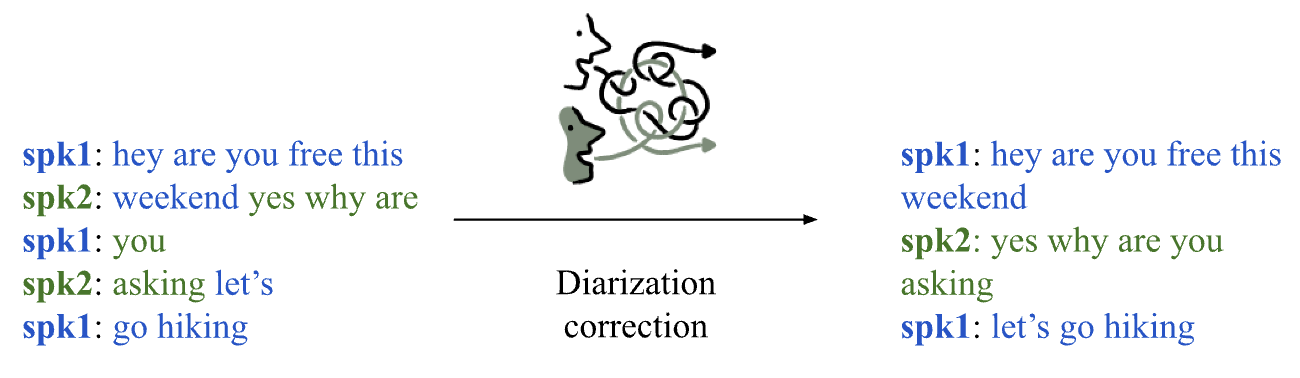
Figure 1: Accurate speaker diarization is necessary for interpretation of important conversations.
Methodology
Data and Preprocessing
The English Fisher corpus, comprising 1,960 hours of transcribed phone conversations, is utilized for fine-tuning and evaluating the LLM models. This dataset supports diverse speaking styles and demographics, providing a robust foundation for training. ASR tools from AWS, Azure, and WhisperX generate the initial transcripts, which are then standardized and pre-processed to align speaker labels using a Transcript-Preserving Speaker Transfer (TPST) algorithm.

Figure 2: Creation of oracle transcripts using the TPST algorithm. Words and speaker labels are extracted from each transcript. The algorithm aligns word sequences, such that the resulting speaker labels from the reference transcript match the text of the ASR transcript. This corrects speaker labeling in the ASR transcript without changing the underlying transcription.
Model Fine-Tuning and Evaluation
The Mistral 7B model serves as the baseline for fine-tuning. Separate models tailored for AWS, Azure, and WhisperX transcripts are trained using Quantized Low-Rank Adaptation (QLoRA) and Flash attention for computational efficiency. An ensemble model combining these ASR-specific models is developed to enhance generalization across different ASR systems.
Diarization accuracy is measured using delta concatenated minimum-permutation word error rate (deltaCP) and delta speaker-attributed word error rate (deltaSA), metrics that isolate errors introduced by speaker mislabeling from transcription inaccuracies.
Results
Baseline ASR outputs demonstrate varying levels of word error rates (WER) and diarization accuracy, with Azure showing the best and WhisperX the poorest performance. The fine-tuned LLMs markedly improve diarization accuracy, as evidenced by significant reductions in deltaCP and deltaSA values compared to baseline error rates.
The ensemble model outperforms individual ASR-specific models, showcasing its ability to generalize across different ASR outputs. The improvement in accuracy was achieved without increasing inference time or altering the model architecture, suggesting practical applicability for real-time processing.
Discussion
The results underscore the necessity of fine-tuning for LLM-driven diarization correction. Zero-shot models, lacking task-specific adaptation, perform poorly due to diverse ASR output characteristics. Although fine-tuned models exhibit ASR-specific improvements, the ensemble approach demonstrates potential for broader applicability and better generalization, even for previously untested ASR tools like GCP.
Future work can address the limitations by testing on diverse conversational domains, extending to multilingual datasets, and integrating multimodal data for robust solutions. Incorporating contextual metadata (e.g., speaker roles) could enhance the system's understanding and accuracy of speaker labeling.
Conclusion
The research highlights the effectiveness of fine-tuning LLMs for diarization correction while identifying limitations in ASR-specific adaptations. The proposed ensemble model offers a promising path towards achieving ASR-agnostic speaker diarization solutions, facilitating integration into a wide range of applications dependent on accurate transcription and speaker differentiation. By making these models accessible through public APIs, the study paves the way for improved computational tools in fields reliant on precise audio analysis.

