- The paper demonstrates that sharper loss landscapes correlate with increased catastrophic forgetting, using metrics like Surface Curvature and Average Gradient.
- The study introduces SAM, a two-step gradient descent approach that flattens the loss landscape and reduces forgetting during fine-tuning.
- Results across diverse models and datasets show improved general task performance and robustness with SAM compared to existing methods.
Revisiting Catastrophic Forgetting in LLM Tuning
Introduction
The paper "Revisiting Catastrophic Forgetting in LLM Tuning" addresses a critical issue in the fine-tuning of LLMs: Catastrophic Forgetting (CF). CF occurs when models lose previously acquired knowledge upon learning new information. This paper aims to establish the connection between the flatness of the model's loss landscape and the severity of CF, proposing Sharpness-Aware Minimization (SAM) as a viable method to alleviate CF by optimizing the loss landscape.
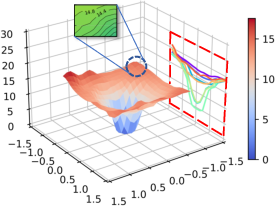
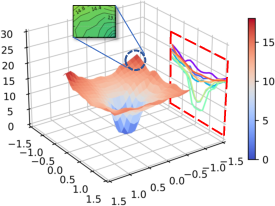
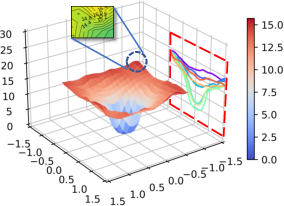
Figure 1: Alpaca.
Correlation Between Loss Landscape Flatness and Catastrophic Forgetting
The study investigates the relationship between CF and loss landscape flatness through several analyses: loss landscape visualization, calculations of flatness degree metrics (Surface Curvature, Average Gradient, and Mean Absolute Gradient), and assessments of the models' general task performance. The analyses demonstrate a strong correlation between sharper loss landscapes and elevated CF.
The visualization results indicate that increasingly difficult tasks exacerbate the disturbance in the loss landscape contours, reflecting a direct relationship between more challenging task adaptation during continuous learning and CF severity.
Mitigating Catastrophic Forgetting with Sharpness-Aware Minimization
To address CF, the paper introduces Sharpness-Aware Minimization, which aims to flatten the loss landscape from an optimization perspective. SAM employs perturbations constrained by a radius ρ to ensure robustness against minor variations in the landscape, effectively reducing the sharpness and, consequently, the model's susceptibility to CF during fine-tuning.
The SAM approach involves optimizing the model weights through a two-step gradient descent process. This method is integrated with standard optimizers to facilitate seamless implementation alongside existing strategies.
Experimental Setup and Results
Datasets and Model Selection
Experiments are conducted on several instruction fine-tuning datasets such as Alpaca, ShareGPT52K, MetaMathQA, Open-Platypus, and Auto-Wiki. The models used range from smaller ones like TinyLlama-1.1B to larger models like Llama2-13B, ensuring the robustness of SAM across different model sizes.
Evaluation Metrics
The performance evaluation employs a series of benchmarks covering domain knowledge, reasoning, understanding, and examination tasks. Results indicate that SAM mitigates CF effectively, demonstrating improvements in general task performance across diverse datasets and models.
Quantitative metrics reveal a significant decline in CF severity when SAM is applied, achieving noticeable performance improvements even on larger models prone to higher CF risks.
Complementary Benefits of SAM
SAM not only outperforms existing CF-mitigation methods such as Wise-FT and Rehearsal but also enhances their effectiveness when used concurrently. The orthogonality of SAM allows it to incrementally benefit these methods, suggesting its potential as a staple strategy for CF mitigation in LLM tuning.
Conclusion
This research provides an empirical foundation establishing the link between loss landscape flatness and CF in LLMs, offering SAM as a compelling method to enhance model resilience against CF. The paper's findings suggest future exploration in optimizing training strategies and curriculum learning to further diminish CF across LLM lifecycle stages.
Future work could explore other factors influencing CF and explore broad strategies applicable during various lifecycle phases, refining the existing landscape for large-scale model fine-tuning.

