- The paper proposes a novel document-level claim extraction approach that integrates summarization and decontextualization for independent claim evaluation.
- It employs BertSum and DocNLI models alongside a QA-driven context generation process to refine and prioritize check-worthy claims.
- Experiments on the AVeriTeC-DCE dataset demonstrate significant precision improvements, indicating enhanced performance in automated fact-checking.
Document-level Claim Extraction and Decontextualisation for Fact-Checking
Introduction
The paper "Document-level Claim Extraction and Decontextualisation for Fact-Checking" addresses the challenge of efficiently selecting claims from documents that fact-checkers need to verify. Traditional claim extraction methodologies predominantly operate at the sentence level, identifying if a sentence contains a claim worth verifying. However, documents present a more complicated scenario where multiple claims, potentially not all central to the document, exist. This work proposes a document-level approach, integrating extractive summarization with decontextualization to streamline the claim extraction process for fact-checking.
Methodology
The approach introduced in the paper encompasses several stages, each contributing to the extraction of salient claims from documents that are interpretable without their original context.
The claim extraction process begins with identifying central sentences within a document using BertSum, an extractive summarization model. This model ranks sentences by their relevance to the document's main theme. Furthermore, to reduce redundancy and ensure diversity of claims, a model called DocNLI processes these ranked sentences to remove those with entailed repetitive content.
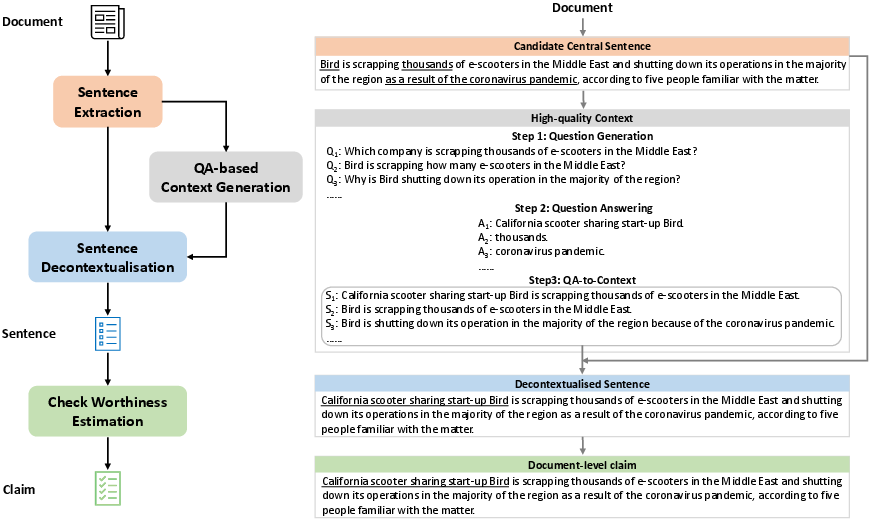
Figure 1: An overview of the document-level claim extraction framework, illustrating the process from extractive summarization to claim check-worthiness classification.
Context Generation and Decontextualization
Once central sentences are determined, the system identifies ambiguous information units such as named entities or pronouns. It generates questions targeting these units and employs a QA model to retrieve context from the document itself. This QA-derived context aids in rewriting sentences to be understood independently of their source, using a seq2seq model for decontextualization, enriching the sentences with crucial contextual data.

Figure 2: Case studies of sentence decontextualisation solving linguistic problems, such as coreference resolution, global scoping, and bridge anaphora.
Estimation of Claim Check-worthiness
The final decontextualized sentences undergo evaluation through a classifier that assigns a check-worthiness score, ensuring only substantial claims proceed to fact-checking. The classifier distinguishes between Check-worthy Factual Sentences, Unimportant Factual Sentences, and Non-Factual Sentences based on their likelihood to present verifiable claims.
Results and Evaluation
The framework is evaluated using a newly derived dataset, AVeriTeC-DCE. It improves the precision of identifying central sentences to 47.8% at Precision@1, a notable enhancement over previous systems like Claimbuster. In addition, the approach demonstrates robust performance in evidence retrieval, with precision gains indicating that decontextualized sentences significantly enhance claim validation efficacy.
Moreover, through both automatic and human evaluations, the effectiveness of the decontextualization process is affirmed. Human evaluators recognize the claims extracted by the proposed method as more central and check-worthy compared to traditional methods.
Conclusion
This document-level claim extraction method enriches the fact-checking pipeline by prioritizing essential claims and providing contextually independent formulations. The ability to parse documents holistically enhances the relevance and accuracy of automated fact-checking systems. Future work could explore extending this methodology to multimodal content, addressing platform-specific claim dynamics, and improving cross-domain generalization capabilities.

