- The paper identifies key security threats in AI agents, detailing vulnerabilities like prompt injection, backdoor attacks, and tool exploitation.
- It employs a structured survey to analyze risks across the perception, brain (LLM misalignment and hallucinations), and action modules.
- The paper recommends future research directions including robust input inspection, bias mitigation, and secure memory management for ethical deployment.
AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways
In recent developments, AI agents have emerged as sophisticated software entities designed to autonomously execute tasks and make decisions based on predefined objectives and data inputs. These agents have demonstrated their proficiency across various domains, yet they introduce critical security challenges. This essay provides an authoritative summary of the paper "AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways", aiming to dissect the security vulnerabilities and propose pathways for enhanced protection.
Introduction to AI Agents
AI agents exhibit intelligent behavior through autonomy, reactivity, proactiveness, and social ability, operating by perceiving inputs, reasoning about tasks, planning actions, and executing tasks with tools. The integration of LLMs like GPT-4, combined with AI agents, has significantly transformed multiple industries including healthcare, finance, and customer service. Despite these advancements, AI agents present unresolved security challenges due to their sophisticated operations across diverse environments.
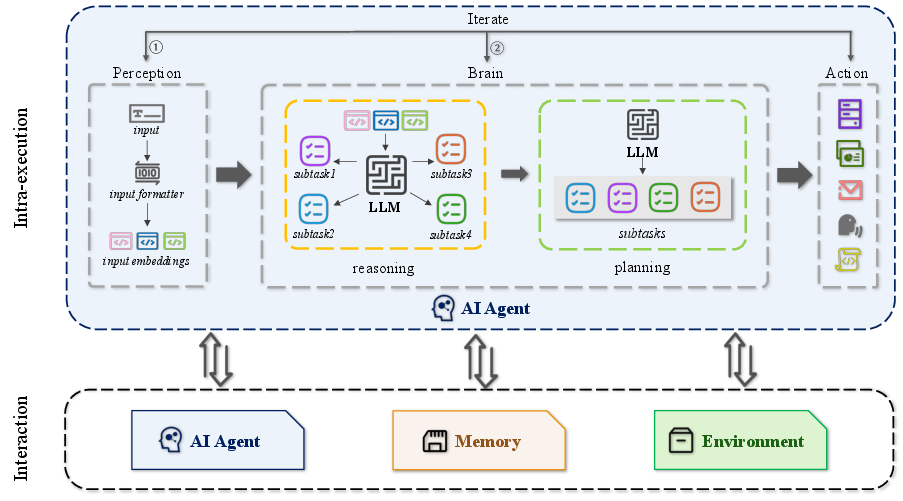
Figure 1: General workflow of AI agent. Typically, an AI agent consists of three components: perception, brain, and action.
Security Threats Faced by AI Agents
The perception component, responsible for processing multi-modal and multi-step data, is prone to adversarial attacks. Prompt injection attacks are prominent, where malicious actors manipulate input prompts to bypass constraints and expose sensitive data. Attacks like goal hijacking and prompt leaking can alter task execution and reveal proprietary knowledge, respectively.
Vulnerabilities in the Brain Module
The brain module, anchored in LLMs, faces several threats:
- Backdoor Attacks: Hidden backdoors in LLMs allow malicious manipulation, triggering incorrect outputs based on specific inputs.
- Misalignment: Incompatible alignment between agent behavior and human expectations can lead to ethical and social threats such as discrimination and misinformation.
- Hallucinations: LLM-based agents might generate implausible or incorrect statements due to data compression and inconsistency.
Planning threats arise when agents generate flawed plans due to complexities in long-term planning, highlighting the inherent robustness issues of LLMs.
Action Module Threats
The internal execution known as actions involves tool manipulation, which is vulnerable to two threat sources:
- Agent2Tool Threats: Active threats materialize through generated action inputs, potentially compromising tool performance and data privacy.
- Supply Chain Threats: Security vulnerabilities in the tools themselves, such as buffer overflow or SQL injection, can distort action execution.
Interaction-Based Security Challenges
Threats from Operational and Physical Environments
Various environments introduce unique threats:
- Simulated Environment: Risks include anthropomorphic attachment and misinformation, necessitating ethical guidelines.
- Physical Environment: Vulnerabilities in sensors and data inputs can lead to compromised agent systems.
Multi-Agent System Interaction
AI agents operating in multi-agent systems provide benefits like improved decision-making but also introduce threats due to secret collusion, amplified errors, and adversarial competition. Robust frameworks are essential to mitigate these risks.
Memory Interaction Threats
Memory interaction, critical for retaining and applying learned knowledge, faces threats related to data poisoning and privacy violations. Vector databases utilized in long-memory storage can be exploited for adversarial attacks and inference privacy risks.
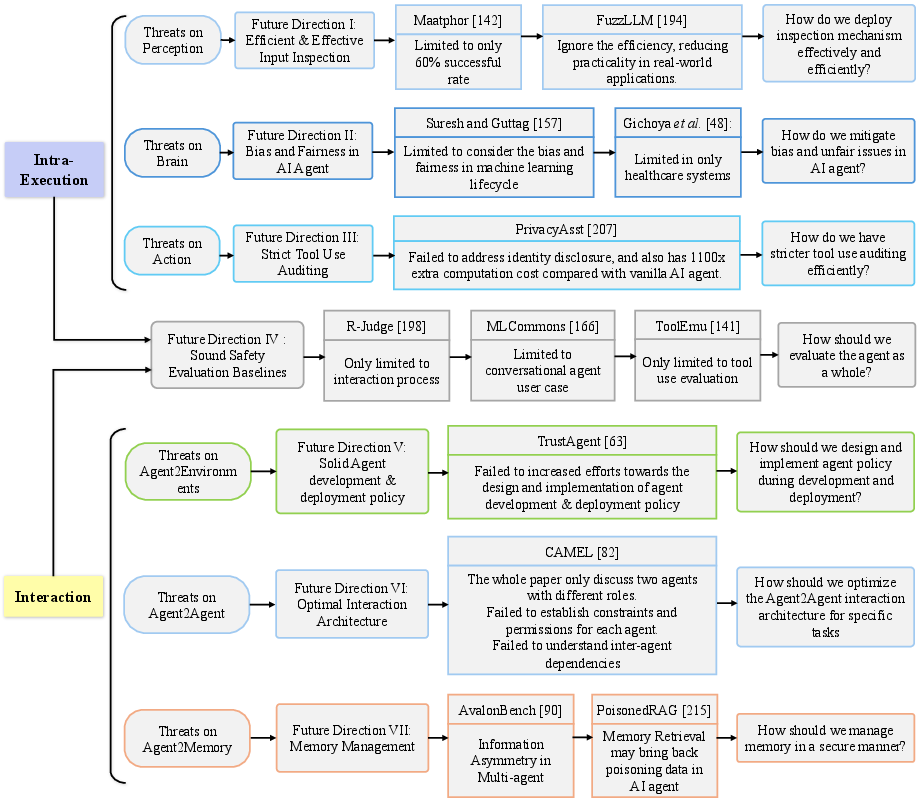
Figure 2: Illustration of Future Directions
Future Research Directions
The paper emphasizes the need for efficient input inspection mechanisms, bias and fairness improvements, strict tool auditing, robust memory management, and optimal interaction frameworks. These directions aim to provide comprehensive solutions to enhance the security and ethical deployment of AI agents.
Conclusion
This survey categorizes and evaluates critical security threats associated with AI agents and highlights current limitations in protective measures. By addressing key knowledge gaps, this research aims to guide future efforts in developing robust and secure AI systems, ensuring safer integration across various sectors. Further exploration into these challenges will catalyze the advancement of more reliable and ethically aligned AI agent applications.