- The paper introduces a novel quantization method achieving lossless W8A8 and minimal W4A8 degradation with a 2.5x size reduction and 1.5x speedup.
- It details token-wise, dynamic, and timestep-aware quantization techniques that specifically address variance challenges in diffusion transformers.
- Extensive experiments confirm that ViDiT-Q maintains FP16-level performance, making it viable for efficient deployment in resource-constrained environments.
Introduction and Objective
The paper "ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation" (2406.02540) introduces a novel quantization method tailored specifically for Diffusion Transformers (DiTs), addressing unique challenges posed by the large model sizes and computational demands involved in visual generation tasks. Despite the significant performance of DiTs in generating realistic media content, their large memory consumption and latency issues impede practical deployment, especially on edge devices. ViDiT-Q aims to resolve these concerns by employing Post-Training Quantization (PTQ) techniques to efficiently compress the model, reducing computational and memory overhead while preserving output quality.

Figure 1: We introduce ViDiT-Q, a quantization method specialized for diffusion transformers used in image and video generation. ViDiT-Q achieves lossless W8A8 quantization and minimal visual quality degradation at W4A8, gaining 2.5x model size reduction and a 1.5x latency speedup.
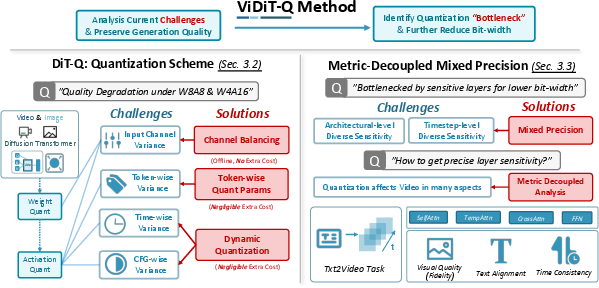
DiTs pose specific quantization challenges not observed in conventional CNN-based diffusion models, primarily because of the variance in data across multiple dimensions. These include input-channel, token, timestep, and CFG (classifier-free guidance) levels. Existing quantization strategies fail to maintain quality across these dimensions due to fixed quantization parameters, hindering application to lower bit-widths like W4A8, which often result in image degradation or unreadable content. By conducting a detailed data distribution and sensitivity analysis, the paper identifies these primary obstacles and proposes solutions through an improved quantization framework.

Figure 2: The Challenges for existing diffusion quantization methods, and ViDiT-Q's solutions. ViDiT-Q introduced improved quantization scheme tailored for DiT to achieve lossless W8A8, and metric decoupled mixed precision tailored for video generation to mitigate degradation for W4A8.
ViDiT-Q Framework
ViDiT-Q introduces several key innovations in diffusion transformer quantization. These include:
Metric Decoupled Mixed Precision
To further enhance quantization effectiveness at lower bit-width operations, ViDiT-Q-MP employs a metric-decoupled approach. By closely analyzing the influence of quantized layers on evaluation metrics such as quality, text-video alignment, and temporal consistency, this strategy identifies sensitive layers and applies mixed-precision techniques to optimize bit-width specifications without incurring performance degradation.

Figure 4: The quantization ``bottleneck'' phenomenon and the motivation of metric decoupled analysis.
Experimental Results
Comprehensive evaluations demonstrate that ViDiT-Q delivers significant advancements over baseline PTQ methods. The quantization with ViDiT-Q consistently achieves lossless visual quality at W8A8 and maintains quality at W4A8 with minimal degradation, thereby facilitating substantial memory reduction and increased inference speed. DiT models quantized using ViDiT-Q exhibit comparable performance to FP16 baselines across various quality metrics, underscoring the method's effectiveness and resilience.

Figure 5: Performance of ViDiT-Q text-to-image generation on COCO. Left: The metric scores of PixArt-alpha and PixArt-Sigma quantization. Right: Generated image comparison of W8A8 quantization.
Hardware Optimization
From a hardware resource perspective, ViDiT-Q achieves a 2.5x reduction in model size and 1.5x latency speedup, demonstrating its suitability for deployment in resource-constrained environments. By focusing on quantization of linear layers and leveraging techniques such as FlashAttention, ViDiT-Q efficiently minimizes latency and optimizes memory usage.
Conclusion
ViDiT-Q represents a significant advancement in the quantization techniques applicable to diffusion transformers, specifically tailored for both image and video generation tasks. By addressing variance across key data dimensions and employing mixed precision, ViDiT-Q achieves a balanced trade-off between computational efficiency and output quality. Future work may involve further refinement of sensitivity analysis and optimization processes, aiming to expand applicability across diverse hardware configurations and operational contexts.