- The paper proposes Multi-Mix augmentation which generates multiple interpolations per sample pair to reduce gradient variance and enhance regularization.
- The paper demonstrates Multi-Mix's effectiveness with improved performance in image classification, object localization, and speech recognition tasks.
- The paper shows that increasing interpolations (optimal K=5) accelerates convergence and enhances model robustness across various applications.
Mixup Augmentation with Multiple Interpolations
Introduction and Background
The paper focuses on data augmentation strategies, specifically mixup and its variants, which enhance the generalization capabilities of deep learning models by generating new training samples through linear interpolation of existing sample pairs. Despite the success of mixup, the generation of a single interpolated sample from each pair may restrict its augmentation ability. This paper introduces a simple extension of mixup called multi-mix, which generates multiple interpolations for each sample pair, thus providing more informative training samples that better guide the learning process and reduce the variance of stochastic gradients.
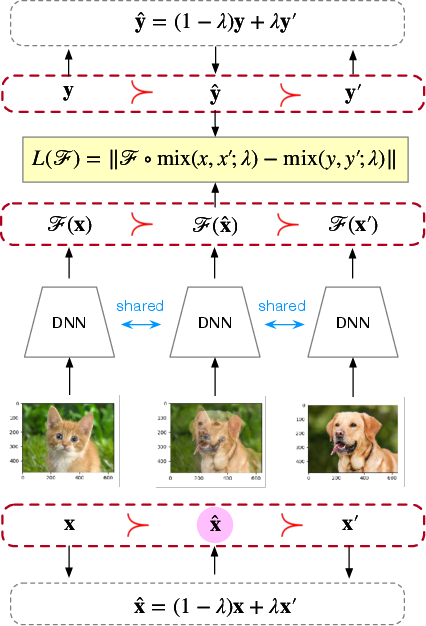
Figure 1: An example of mixup training, involving a mixing coefficient λ=0.5, demonstrating improvements in model performance through ordered mixup transformations.
Multi-Mix Approach
Multi-Mix Implementation
The multi-mix technique involves generating multiple interpolations between sample pairs, improving the regularization path information that mixup transformations provide. This is realized by extending several mixup variants:
- Input Mixup: Multiple input sample interpolations are created using different mixing coefficients, allowing for diverse augmentation.
- Manifold Mixup: Mixing occurs at hidden layers instead of just the input layer, fostering smoother boundaries and enhanced generalization.
- Cutmix and Puzzle-mix Extension: Multi-box selection or mask-mixing strategies are applied to cutmix and puzzle-mix methods to generate multiple augmentations.

Figure 2: Demonstrates the interpolations generated by input mixup (top), cutmix (middle), and puzzle-mix (bottom), providing evidence of extensive augmentation paths.
Theoretical Insights
The paper provides theoretical analysis showing that multi-mix can effectively reduce the stochastic gradient variance, thereby accelerating convergence and enhancing robustness. Proposition 1 states that the variance of the gradients decreases as the number of interpolations increases, suggesting an optimization benefit.
Experimental Evaluation
The effectiveness of the multi-mix method is evaluated across various domains including image classification, object localization, robustness testing, transfer learning, and speech recognition:
- Image Classification: Multi-mix consistently outperformed standard mixup variants in generalization capability on CIFAR-100 and ImageNet-1K datasets.
- Object Localization: Multi-mix led to higher localization accuracy in tasks such as weakly-supervised object localization (WSOL) demonstrating better representation learning.
- Corruption Robustness: Networks trained with multi-mix showed improved resilience against background corruption.
- Transfer Learning: Enhanced transferability was observed with quicker adaptation in fine-tuning steps on CUB 200-2011 datasets.
- Calibration: Networks trained with multi-mix displayed better-calibrated predictions, reflecting more reliable confidence measures.









Figure 3: Example localization results showcasing the ability of multi-mix trained networks to accurately predict bounding boxes in weakly-supervised settings.
Ablation Studies
Further investigations validate the positive impact of varying the number of interpolations K. Empirical results indicate significant performance boosts with increasing K, supporting theoretical claims of gradient variance reduction. Optimal performance was reached with K=5 interpolations, balancing computational cost and model benefits.
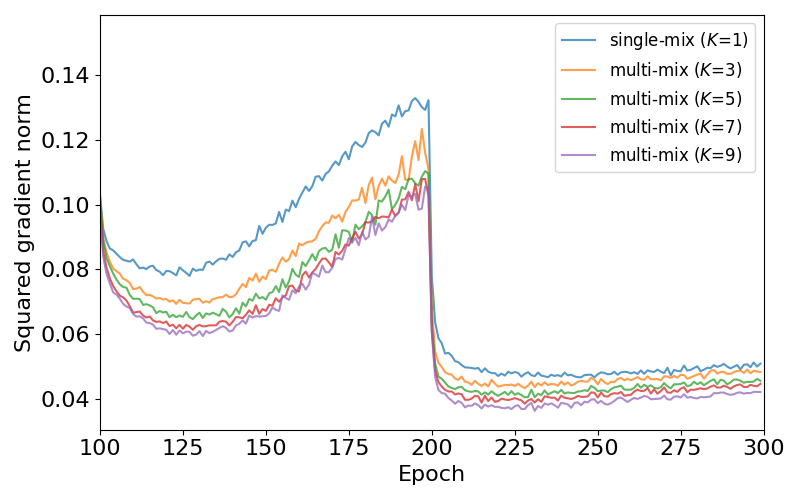
Figure 4: Shows the ℓ2-norm of gradients across training epochs in CIFAR-100, validating theoretical claims of variance reduction ('learning rate decay' effect noted at epoch 200).
Conclusion
Multi-mix presents a straightforward yet effective augmentation strategy that leverages multiple interpolations to improve data diversity, regularization paths, and ultimately model robustness and generalization. This extension on mixup techniques promotes more informative learning and serves as a beneficial augmentation tool in various deep learning applications. Future work could explore adaptive strategies for determining optimal K across different datasets to further refine the approach.

