- The paper reveals that LC0's policy network encodes future move targets, as shown by activation patching causing a mean log odds decrease of 1.88 on key squares.
- It identifies critical attention mechanisms, especially head L12H12, which transfers future move information and significantly impacts move selection when ablated.
- A bilinear probe on layer 12 achieves 92% accuracy in predicting future moves, supporting the existence of explicit, decodable look-ahead representations.
Evidence of Learned Look-Ahead in the Policy Network of Leela Chess Zero
Introduction and Motivation
The question of whether neural networks, particularly in complex domains, internally perform algorithmic computations such as look-ahead or search—as opposed to relying solely on shallow heuristic aggregation—remains central in understanding the mechanistic capabilities and limitations of modern artificial agents. While prior mechanistic interpretability studies have largely focused on synthetic tasks and intentionally simple models, this work investigates whether sophisticated algorithmic reasoning appears in the policy network of Leela Chess Zero (LC0), a high-performance transformer-based chess engine. Notably, LC0 achieves a rating exceeding 2600 on Lichess using only a single forward pass through its policy network, analogous in size and architecture to GPT2-small.
Experimental Setup
The paper leverages LC0's architecturally unique property of treating each chessboard square as an input token, akin to LLMs. This structural alignment enables square-wise attribution analysis via activation patching and attention manipulation. To target network mechanisms demanding genuine look-ahead, the authors curate a dataset of puzzles from Lichess where a weaker model fails to identify the optimal move, yet LC0 succeeds. The resultant filtered set exhibits tactical complexity and a predominance of motifs requiring explicit calculation rather than heuristics (e.g., sacrificial sequences).
Causal Evidence of Look-Ahead via Activation Patching
A central experimental thrust employs activation patching, intervening on specific squares and layers by substituting their activations from corrupted board states and quantifying downstream effects on the policy output.
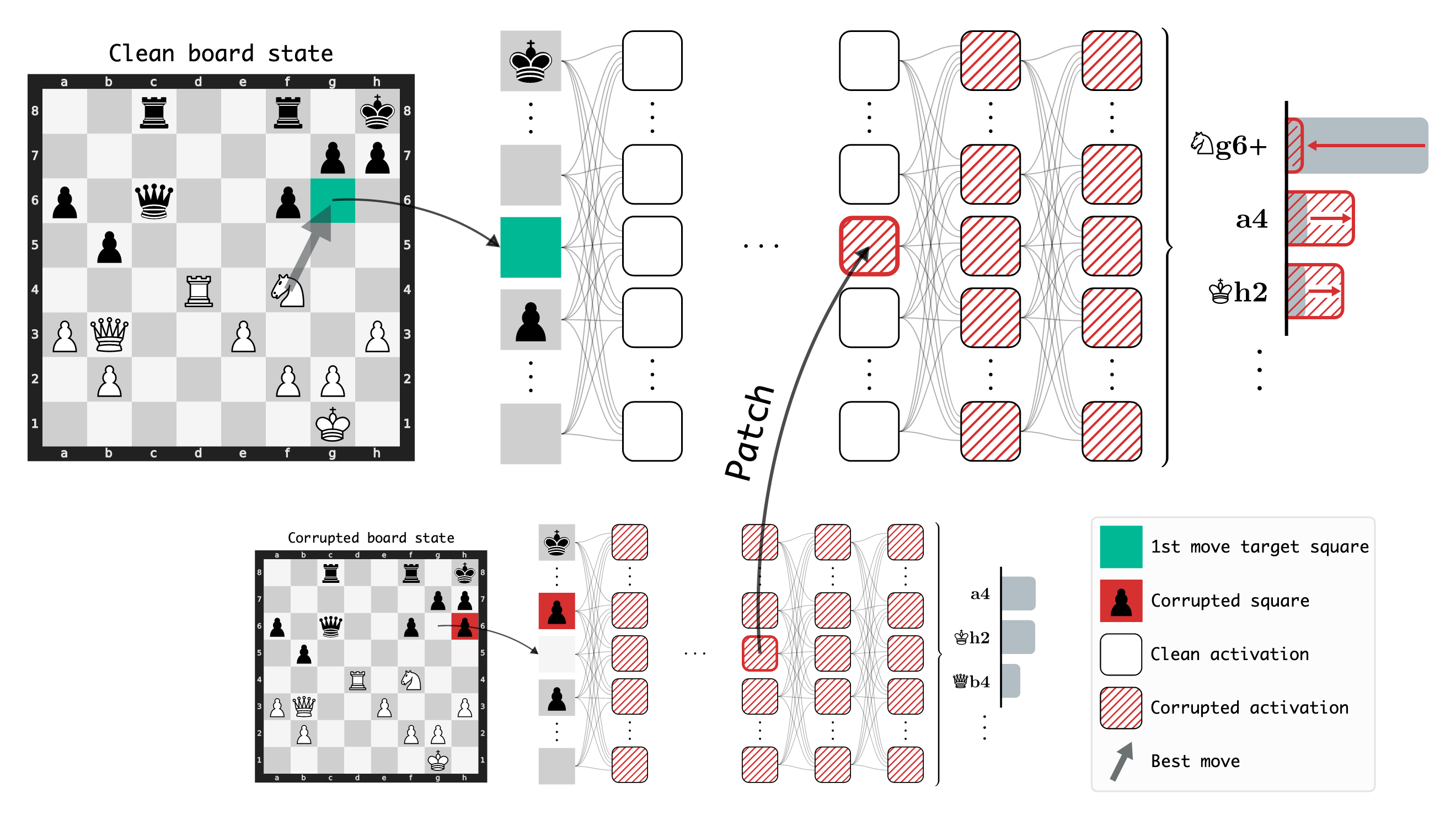
Figure 1: Activation patching illustrates that patching activations on specific squares/layers produces significant shifts in network output, implicating those locations in storing critical information.
Results show that patching the target square of the move two steps into the future yields a mean log odds decrease of $1.88$ in layer 10, indicating a substantial loss in probability of selecting the ground-truth move. In contrast, patching on unrelated squares produces much weaker effects, even when aggregating across all other squares. This establishes that LC0 actively represents future moves in a spatially localized fashion within the residual stream, and not as a diffuse, non-causal heuristic signal.
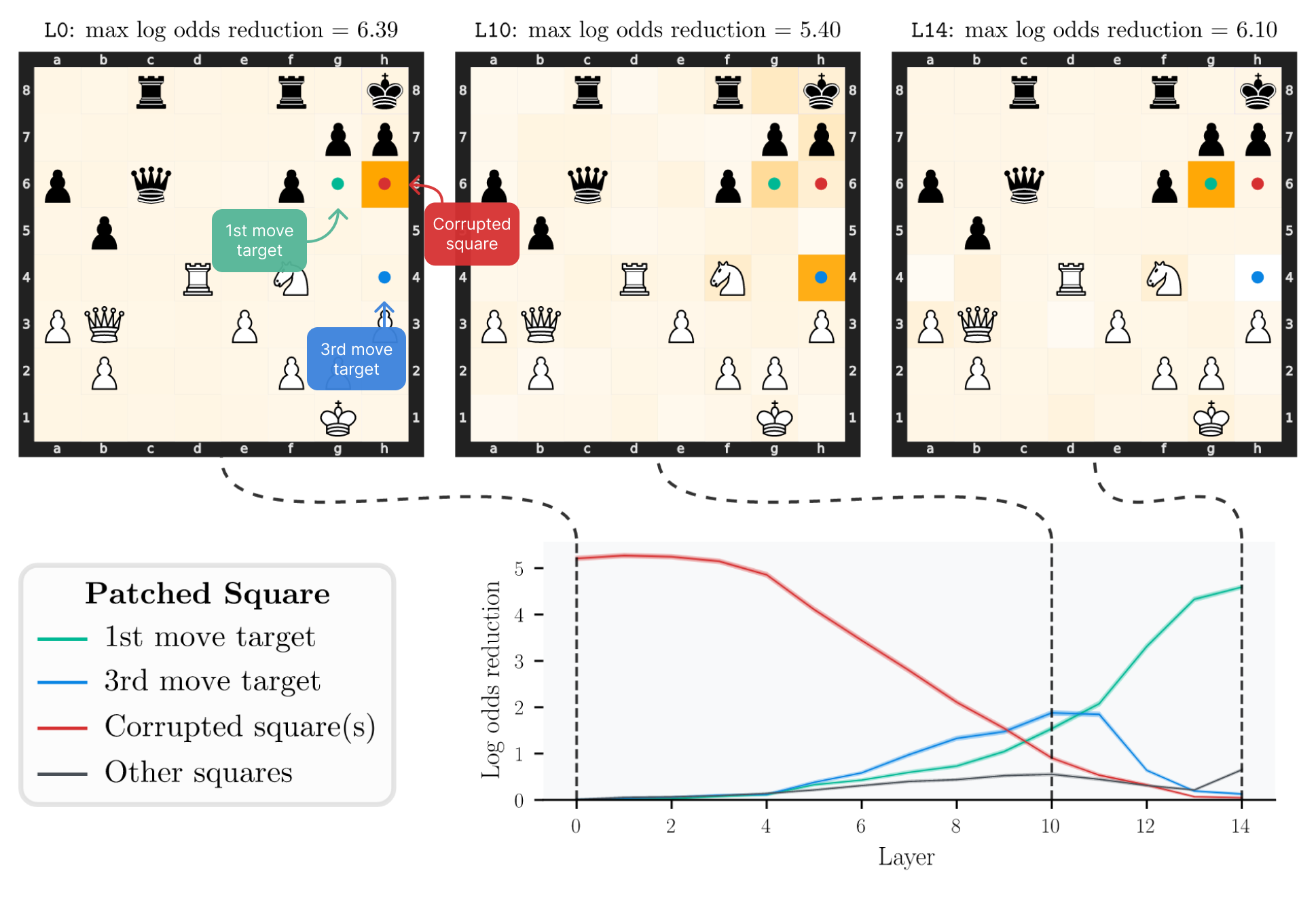
Figure 2: Residual stream activation patching demonstrates changing importance of squares across layers, with future move targets dominating in mid-layers.
In-depth analysis of attention heads uncovers specific heads that transfer information between temporally distinct squares. Head L12H12, in particular, exhibits a high attention score between the target square of the immediate move and that of a future move, frequently above all other entries. Ablating this single attention weight causes outsized effects, reducing correct move log odds by over 1.5 in more than 10% of puzzles, whereas ablating all 4095 other entries simultaneously has markedly smaller impact.

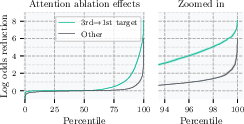
Figure 3: Patching individual attention head outputs reveals L12H12 as disproportionately influential in transmitting future move information.
Additionally, the authors identify "piece movement heads" by manually inspecting attention patterns that closely correspond to legal moves for specific pieces. Ablating information flow from future move target squares in these heads (but not others) significantly decreases model performance, especially when the principal variation exceeds three moves, implying these heads participate in forward analysis of tactical lines.

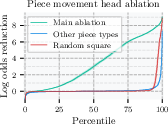
Figure 4: Piece movement heads visually attend to squares reachable by specific pieces, consistent across random puzzles and queries.
Probing for Explicit Future Move Representations
To further substantiate the encoding of future moves, a bilinear probe architecture is trained to predict the target square of the optimal move two steps ahead, motivated by the structure observed in L12H12's attention patterns. Using residual activations after layer 12, the probe achieves 92% accuracy in the filtered puzzle set, while probes on randomly initialized networks attain only 15%, congruent with chance. This implies the presence of stable, decodable representations of future move targets embedded within the residual stream.
Figure 1: A probe on layer 12 residual stream activations achieves near-perfect prediction of future move target squares, supporting explicit internal representation.
Theoretical and Practical Implications
This "existence proof" of learned look-ahead in LC0's policy network has several repercussions. First, it demonstrates that deep networks can, in complex real-world domains, spontaneously construct representations and causal pathways analogous to explicit search—even when trained on supervised targets generated by external MCTS. Second, the structural localization and decode-ability of move information argue for the viability of mechanistic interpretability approaches in agentic settings, not only language tasks. Third, the robust accuracy achieved by simple probes suggests that internal representations in transformers are highly structured and may be accessible to external analysis and manipulation. The presence of look-ahead mechanisms also provides cautionary context for potential risks from mesa-optimization, as discussed in literature such as Hubinger et al. (Hubinger et al., 2019), given that networks may learn advanced reasoning strategies not directly apparent from their training regimens.
The practical impact includes the possibility of using chess-playing models as test beds for interpretability and safety research, given their clear metrics, well-understood domain algorithms, and discrete, analyzable decision processes. Such findings invite parallel investigations in LLMs, where analogous mechanisms could underlie advanced reasoning capabilities.
Limitations and Future Directions
Despite the strong evidence, the work stops short of fully characterizing the precise algorithmic structure used for look-ahead, and does not address whether the network compares multiple lines of play or implements general search. Analysis is restricted to states filtered for tactical complexity, potentially over-representing scenarios where explicit calculation is favored over heuristics. The methods could be applied to less curated datasets and other domains to examine the generality of these mechanisms. Theoretically, integrating findings from mechanistic interpretability with formal descriptions of search and optimization in neural architectures remains an open challenge.
Conclusion
This study demonstrates, via causal interventions, attention head analysis, and probing, that the policy network of Leela Chess Zero encodes future move information and utilizes attention-based mechanisms for temporal propagation, indicative of learned look-ahead. These results inform both the interpretability and algorithmic analysis of advanced neural agents, providing avenues for mechanistic studies in other domains and highlighting the emergent capacity for algorithmic reasoning in large-scale network training.