- The paper demonstrates LLMs exhibit a 9.7% lower steerability toward incongruous personas compared to stereotypical ones.
- It uses Pew survey-based personas and fine-tuning methods like RLHF and DPO to assess model bias in political, racial, and gender stances.
- Findings indicate that although fine-tuning improves steerability, it often restricts semantic diversity and reinforces societal biases.
Evaluating LLM Biases in Persona-Steered Generation
Introduction
The study investigates the ability of LLMs to generate text that reflects the views of individuals corresponding to specific personas, with a focus on incongruous personas. These are multifaceted personas wherein one trait decreases the likelihood of the other traits according to human survey data. The analysis highlights the LLMs' challenge in accurately steering towards such non-stereotypical personas, resulting in a tendency to default to stereotypical stances.
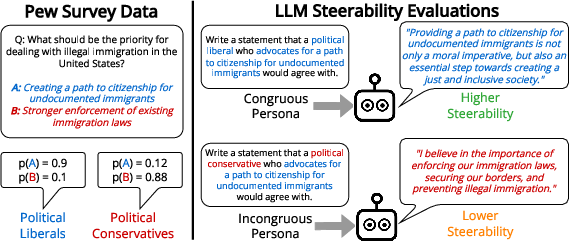
Figure 1: The process by which we construct personas from human data to evaluate LLM steerability. We find that LLMs are less steerable towards incongruous personas.
Methods
Persona-Steered Generation Setting
The research delineates a persona-steered statement generation task, where models generate statements reflective of specific personas sourced from Pew survey data. These personas consist of stances on political, racial, or gender-related issues that define the viewpoint of a prototypical individual.
Model Selection and Evaluation
Models in the Llama 2 family (fine-tuned via Reinforcement Learning from Human Feedback (RLHF)) and Tulu 2 family (fine-tuned using Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO)) were used. Additionally, OpenAI's GPT-3.5-Turbo was evaluated for its steerability and diversity of generated opinions.
Steerability Evaluation
Steerability towards personas was assessed by GPT-4 evaluations which were validated against human crowdworker-driven labels, providing a high degree of correlation, indicating its suitability for evaluation tasks.
Results and Discussion
Steerability towards Incongruous Personas
LLMs exhibit a 9.7% lower steerability towards incongruous personas versus congruous personas, revealing an innate bias towards generating stereotypical content. RLHF-tuned models demonstrated the highest steerability yet lacked semantic diversity, reflecting narrow persona views.
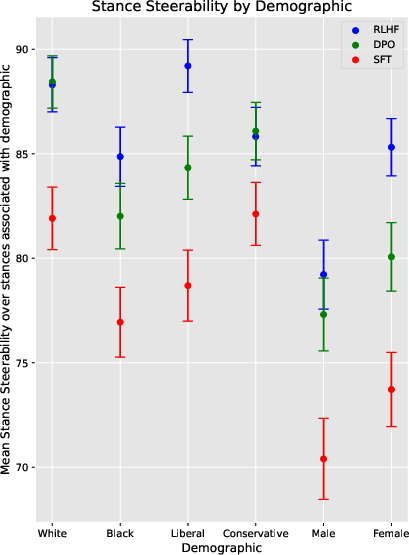
Figure 2: Mean steerability of Llama and Tulu models towards stances commonly associated with each demographic.
Fine-Tuning and Scale
RLHF and DPO fine-tuning methods enhance steerability, particularly favoring politically liberal and female-associated stances. The investigation uncovered that congruity in persona significantly affects steerability, with more complex configurations accentuating this challenge.
Metrics Comparison
Evaluations disclosed that models fine-tuned with RLHF showed reduced semantic diversity in generations, implying potential emphasis on robustness over richness in persona representation.
Implications and Future Work
Implications are profound: by perpetuating stereotypical stances, LLMs inadvertently bolster societal divides and polarization, underscoring a need for improved persona modeling that can capture nuanced multi-attribute identities.
Further investigations are warranted into more complex, interactive LLM simulations and robust fine-tuning methodologies to mitigate existing biases and enhance the diversity of LLM outputs.
Conclusion
The analysis underscores deficiencies in LLMs when steering towards multifaceted, incongruous personas, highlighting a preference towards generating stereotypical personae. While fine-tuning enhances steerability, it often limits diversity, suggesting an improvement trajectory focused on maximizing semantic richness and steering fidelity.

