- The paper introduces two architectures, W2Vanilla and W2VAligned, which leverage pre-trained Wav2vec2.0 embeddings to predict oral reading fluency.
- It employs mean pooling and word-level pooling to capture both global and nuanced speech patterns essential for fluency assessment.
- Evaluation reveals that ASR task-specific pre-training significantly enhances model performance in predicting fluency scores.
Deep Learning for Assessment of Oral Reading Fluency
Introduction
"Deep Learning for Assessment of Oral Reading Fluency" explores the application of deep learning techniques, particularly Wav2vec2.0, for assessing oral reading fluency. This paper addresses the need for scalable, automated fluency assessments and investigates an end-to-end approach leveraging pre-trained models to predict fluency scores based on audio recordings. The methodology promises to alleviate challenges related to limited labeled datasets through self-supervised learning frameworks.
Wav2vec2.0 Based Architecture
W2Vanilla
The W2Vanilla architecture utilizes pre-trained Wav2vec2.0 embeddings, which undergo mean pooling across utterances followed by a series of fully-connected layers for comprehensibility score prediction. This model exhibits superior performance compared to traditional systems based on hand-crafted features, indicating the robustness of Wav2vec2.0 embeddings in capturing relevant fluency features.
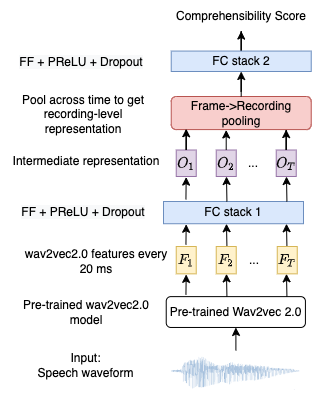
Figure 1: W2Vanilla Architecture.
W2VAligned
An extension to the Vanilla architecture, W2VAligned introduces word-level pooling to retain prosodic features. Word boundaries are determined through forced alignment, allowing the model to capture inter-word variations critical to fluency assessments. However, complexity introduced by this architecture does not consistently translate into better performance.
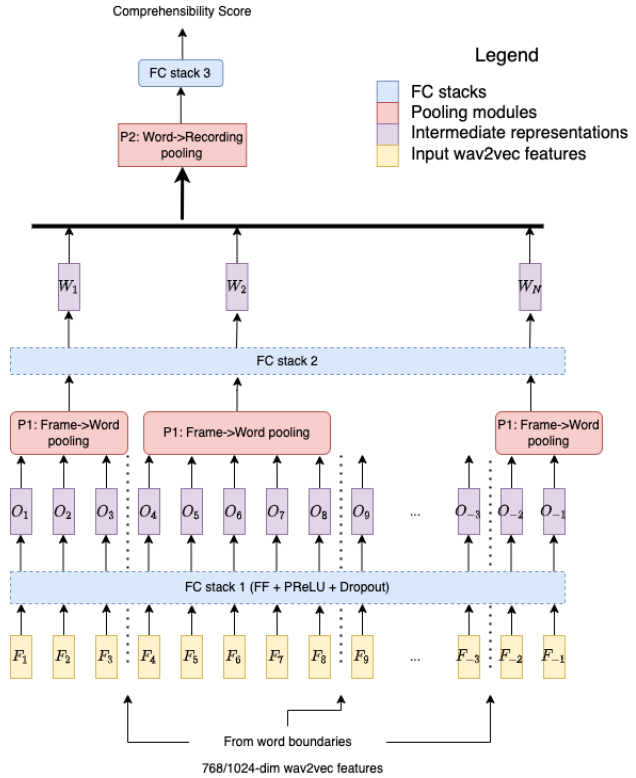
Figure 2: W2VAligned Architecture.
Evaluation of Pre-trained Models
Various Wav2vec2.0 pre-trained models were evaluated for their efficacy in fluency prediction. Notably, the wav2vec2-large-960h-lv60-self model excelled, benefiting from its ASR task-oriented self-training methodology, illustrating that ASR task-specific pre-training enhances model performance in comprehensibility assessments. Differences in performance underscore the significance of pre-training datasets and methodologies on task outcomes.
Probing and Analysis
Probing the representations yielded insights into the model's ability to capture linguistic features. Results demonstrated significant correlations between learned embeddings and high-level fluency features such as speech rate and phrase boundaries, as illustrated below:
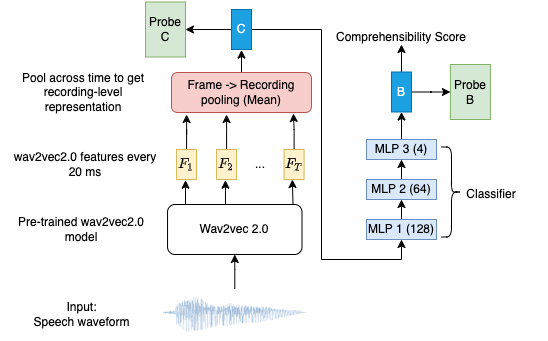
Figure 3: Location of probes in the Vanilla architecture. C is obtained on mean pooling the frame-level representations extracted from a pre-trained (frozen) wav2vec model. On passing it through 3 hidden layers with [128, 64, 4] hidden units, we get a compressed representation B ∈R4.
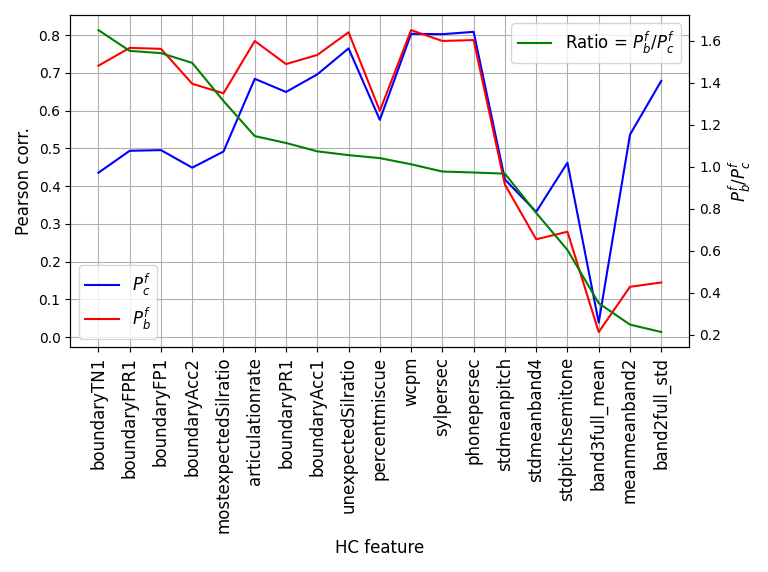
Figure 4: Pcf (Performance on wav2vec embedding), Pbf (Performance on bottleneck embedding) and the ratio PcfPbf, sorted in descending order.
Conclusion
The proposed end-to-end approach showcases the potential of deep learning frameworks for assessing oral fluency, outperforming traditional methods reliant on hand-crafted features. Probing results suggest that while Wav2vec2.0 embeddings effectively capture certain fluency-related features, further optimization and experimentation, particularly with complementary feature sets, could enhance predictive capabilities. Future work could leverage this line of research, exploiting large-scale unlabeled audio data for improved fluency assessment models.