- The paper investigates whether explicitly learning task-relevant latent variables improves in-context learning in Transformer models.
- Experimental results reveal that explicit models enhance interpretability and enable counterfactual interventions but do not consistently outperform implicit models on OOD tasks.
- Scaling trends show that while both model types perform similarly, explicit models require better prediction functions to leverage inferred latents effectively.
Latent Variable Inference and In-Context Learning
This paper (2405.19162) investigates whether explicitly learning task-relevant latent variables improves in-context learning (ICL) within Transformer models. The central hypothesis is that Transformers often rely on statistical shortcuts instead of inferring underlying generative latents, which limits their out-of-distribution (OOD) generalization. By modifying the Transformer architecture with a bottleneck to encourage explicit latent variable inference, the study challenges the assumption that avoiding shortcuts necessarily enhances generalization.
Implicit vs. Explicit Models for ICL
The paper distinguishes between two modeling paradigms: implicit and explicit. Implicit models, represented by standard Transformers, directly map from context and query to prediction, without explicitly disentangling context aggregation and predictive modeling. Explicit models, on the other hand, introduce a bottleneck that forces the model to first infer a task representation from the context, and then use this representation to make predictions on novel queries. This bottleneck is intended to prevent the query from directly attending to the context, encouraging the model to extract structured latent variables.
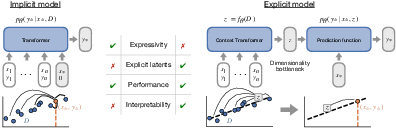
Figure 1: We compare the benefits of the implicit (left) and the explicit (right) model. Explicit models disentangle context aggregation and prediction into two separate functions, and have an inductive bias for inferring generative latent variables in order to solve the task.
The authors argue that explicit models should excel when the underlying data-generating process is parametric and low-dimensional, while implicit models may be better suited for non-parametric or high-dimensional scenarios. The study emphasizes that the aim is not to engineer the best possible explicit model architecture, but rather to investigate potential inductive biases for ICL by minimally modifying the standard Transformer.
Experimental Setup and Results
The study employs a range of tasks, including synthetic regression, classification, Raven's Progressive Matrices, Alchemy, and Gene Targeting, to evaluate the ID and OOD performance of implicit and explicit models. The OOD evaluation includes extrapolation in synthetic tasks and compositional generalization in reasoning tasks. The results indicate that explicit models do not consistently outperform implicit models on OOD data. In fact, in some cases, implicit models show slightly better generalization. This challenges the initial hypothesis that preventing non-parametric shortcuts would enhance generalization.
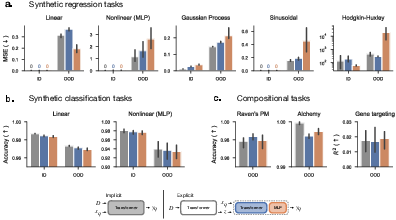
Figure 2: Comparison of implicit and explicit models both in-distribution (ID) and out-of-distribution (OOD) across a variety of domains: (a) synthetic regression, (b) classification, and (c) compositional generalization tasks. Implicit models are in shown \textcolor{gray}{gray}, explicit models with Transformer prediction in \textcolor{NavyBlue}{blue}, and with MLP prediction in \textcolor{Orange}{orange}.
Further analysis reveals that the explicit models often learn to extract relevant task latents, but the prediction function struggles to utilize them effectively for robust prediction.

Figure 3: Performance comparisons on a subset of tasks where the true latent variable $$ and prediction function g are known. Implicit models are in shown \textcolor{gray}{gray} and explicit models with Transformer prediction are in \textcolor{NavyBlue}{blue}.
Interpretability and Counterfactual Interventions
The study demonstrates that explicit models offer enhanced interpretability. Linear decoding from the bottleneck is often successful in recovering the true latent variables. Furthermore, the authors use Distributed Alignment Search (DAS) to identify units in the implicit and explicit models that can be manipulated to obtain correct counterfactual predictions. The results show that the explicit model allows for successful counterfactual interventions by manipulating the bottleneck representation, whereas the implicit model does not.
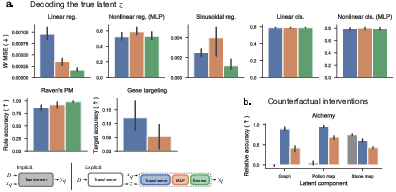
Figure 4: Explicit models are interpretable as the bottleneck allows us to (a) linearly decode the true latent, and (b) intervene on it to obtain correct counterfactual predictions. Implicit models are shown in \textcolor{gray}{gray}.
Scaling Trends
An analysis of scaling trends in linear regression reveals that OOD task performance scales similarly for both implicit and explicit models, with the implicit model generally outperforming the explicit model unless the latter uses the known prediction function. Latent variable decoding accuracy in the explicit model improves with reduced uncertainty about the latent variable and increased model capacity.
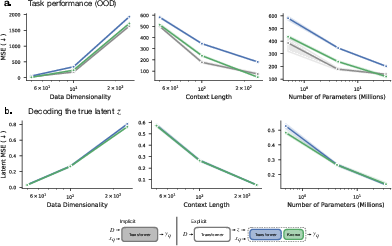
Figure 5: We analyze (a) Linear regression OOD task performance and (b) latent variable linear decoding performance as a function of model and task parameters. Task performance scales similarly for implicit (\textcolor{gray}{gray}) and explicit models with Transformer prediction (\textcolor{NavyBlue}{blue}).
Implications and Future Directions
The findings suggest that the limitations of Transformers in learning generalizable ICL solutions are not solely due to non-parametric shortcuts that bypass latent variable inference, but also stem from fundamental architectural limitations. The study highlights the need for inductive biases in the prediction function to better leverage inferred latent variables. Future research directions include incorporating such inductive biases and improving amortized methods for in-context prediction, as well as exploring neurosymbolic AI approaches.
Conclusion
This paper (2405.19162) challenges the prevailing notion that statistical shortcuts are the primary obstacle to generalization in ICL. By demonstrating that explicitly learning task-relevant latent variables does not guarantee improved OOD performance, the study redirects attention to the importance of the prediction model and its ability to effectively utilize inferred latents. The work underscores the need for architectural innovations that facilitate structured ICL solutions and enhance generalization capabilities in Transformers.

