EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture
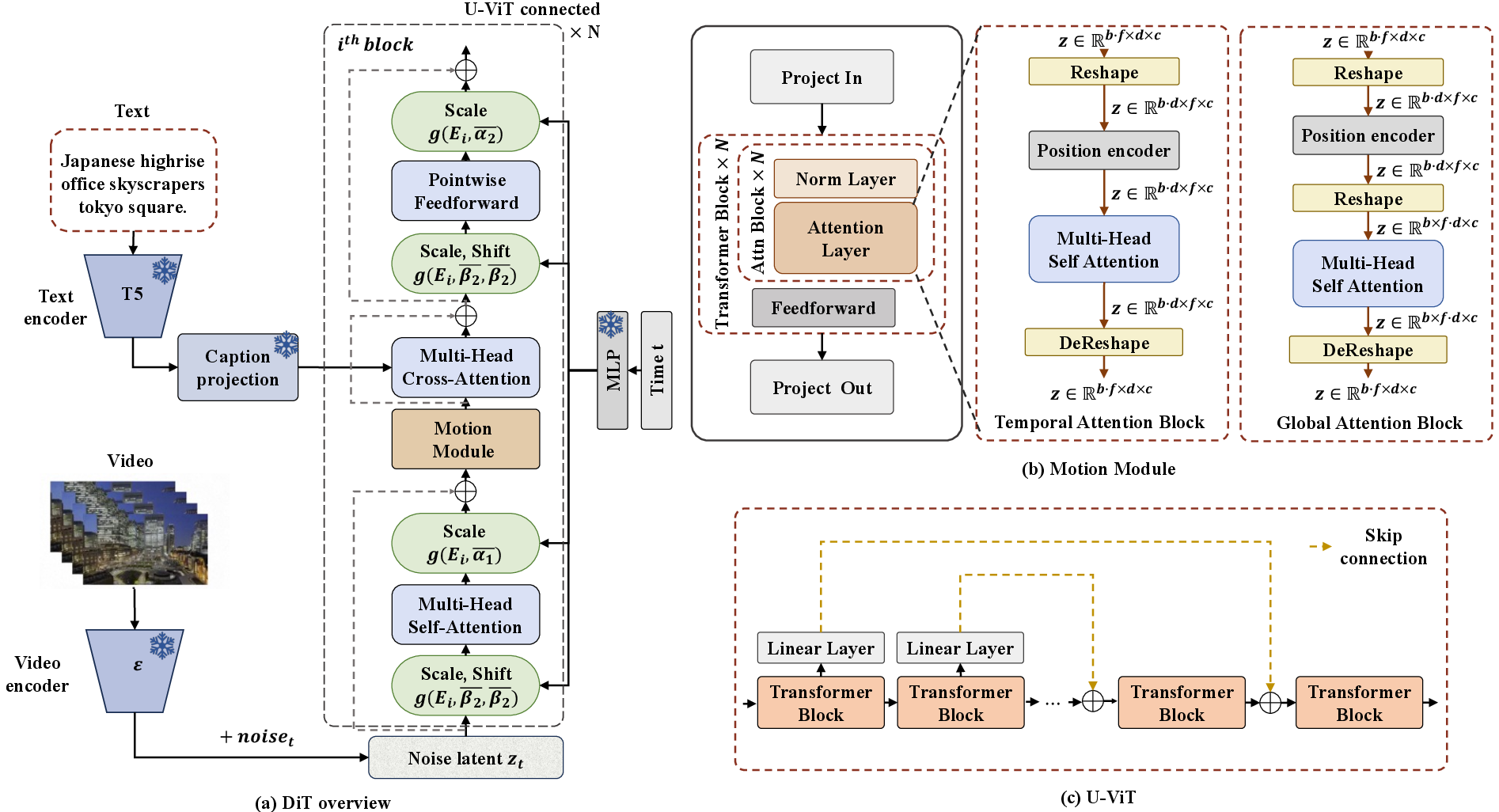
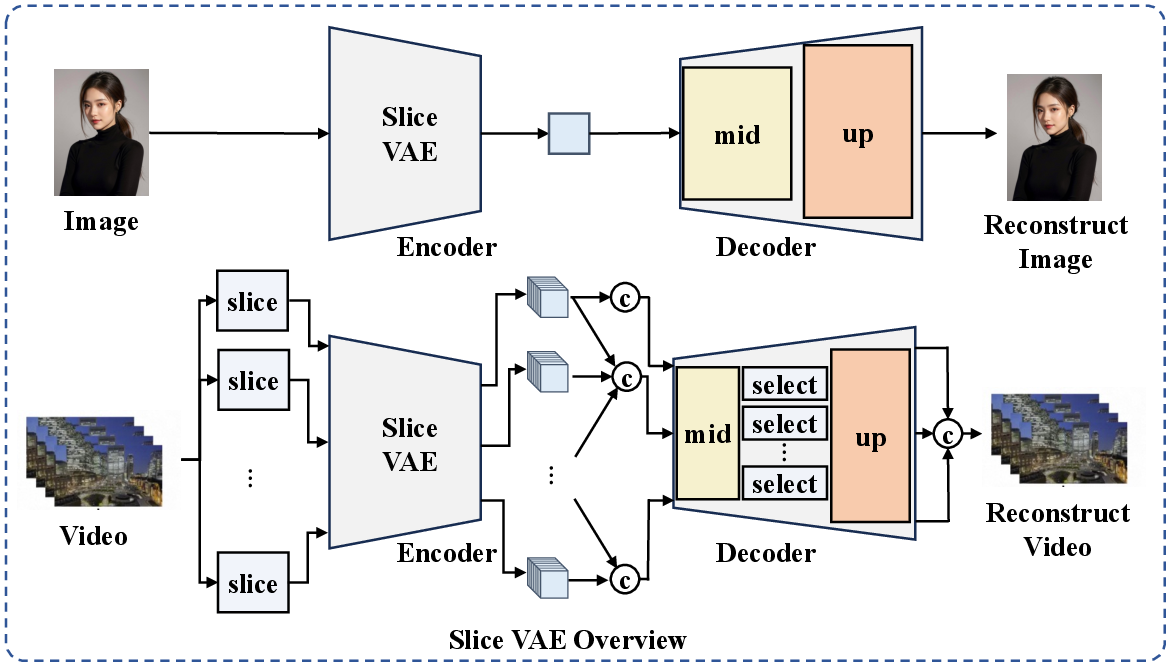
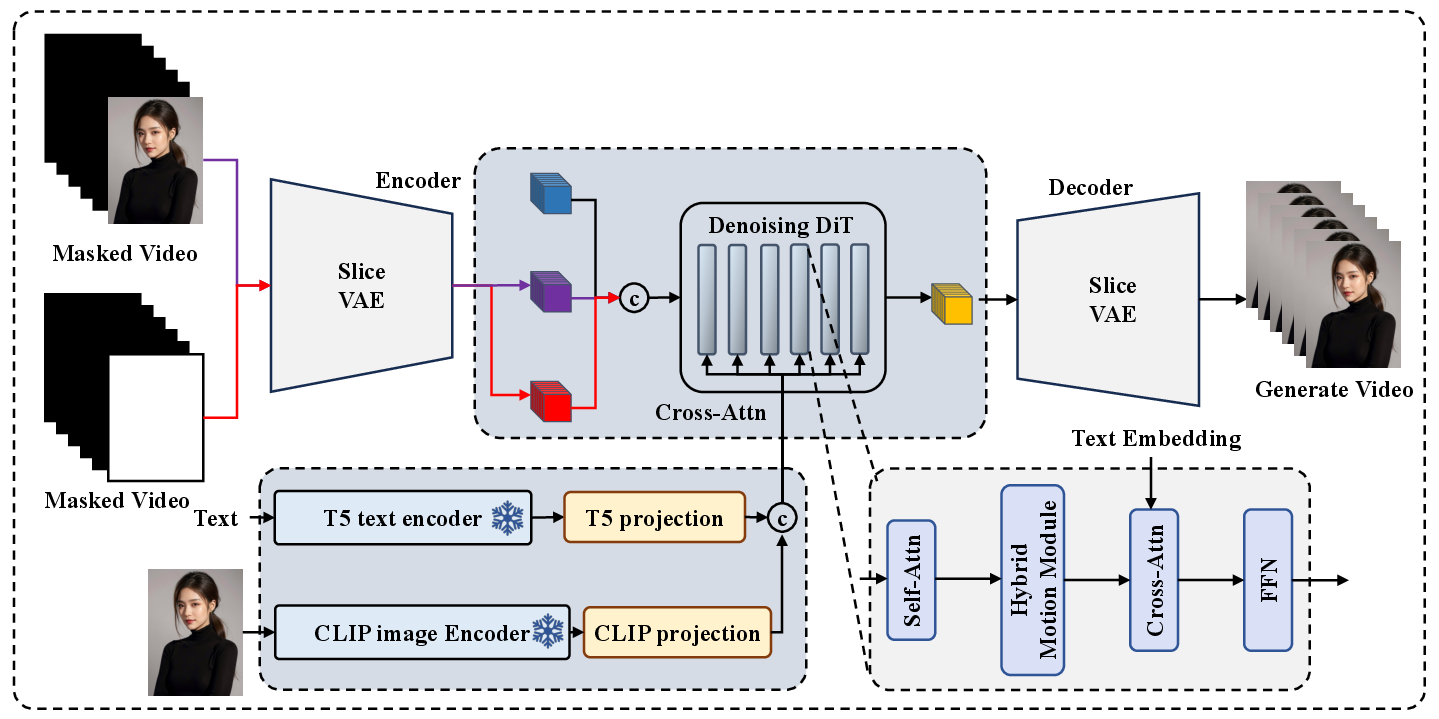
Abstract: This paper presents EasyAnimate, an advanced method for video generation that leverages the power of transformer architecture for high-performance outcomes. We have expanded the DiT framework originally designed for 2D image synthesis to accommodate the complexities of 3D video generation by incorporating a motion module block. It is used to capture temporal dynamics, thereby ensuring the production of consistent frames and seamless motion transitions. The motion module can be adapted to various DiT baseline methods to generate video with different styles. It can also generate videos with different frame rates and resolutions during both training and inference phases, suitable for both images and videos. Moreover, we introduce slice VAE, a novel approach to condense the temporal axis, facilitating the generation of long duration videos. Currently, EasyAnimate exhibits the proficiency to generate videos with 144 frames. We provide a holistic ecosystem for video production based on DiT, encompassing aspects such as data pre-processing, VAE training, DiT models training (both the baseline model and LoRA model), and end-to-end video inference. Code is available at: https://github.com/aigc-apps/EasyAnimate. We are continuously working to enhance the performance of our method.
- All are worth words: A vit backbone for diffusion models. In CVPR.
- Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127.
- Videocrafter1: Open diffusion models for high-quality video generation.
- Videocrafter2: Overcoming data limitations for high-quality video diffusion models.
- Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.
- Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725.
- hpcaitech. 2024. Open-sora: Democratizing efficient video production for all. https://github.com/hpcaitech/Open-Sora.
- PKU-Yuan Lab and Tuzhan AI etc. 2024. Open-sora-plan.
- Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355.
- Vila: On pre-training for visual language models.
- Videofusion: Decomposed diffusion models for high-quality video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- OpenAI. 2024. Video generation models as world simulators. https://openai.com/index/video-generation-models-as-world-simulators/.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67.
- High-resolution image synthesis with latent diffusion models.
- Stability-AI. 2023. sd-vae-ft-ema. https://huggingface.co/stabilityai/sd-vae-ft-ema.
- Zachary Teed and Jia Deng. 2020. Raft: Recurrent all-pairs field transforms for optical flow. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pages 402–419. Springer.
- Modelscope text-to-video technical report. arXiv preprint arXiv:2308.06571.
- Language model beats diffusion–tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

