LLMs achieve adult human performance on higher-order theory of mind tasks
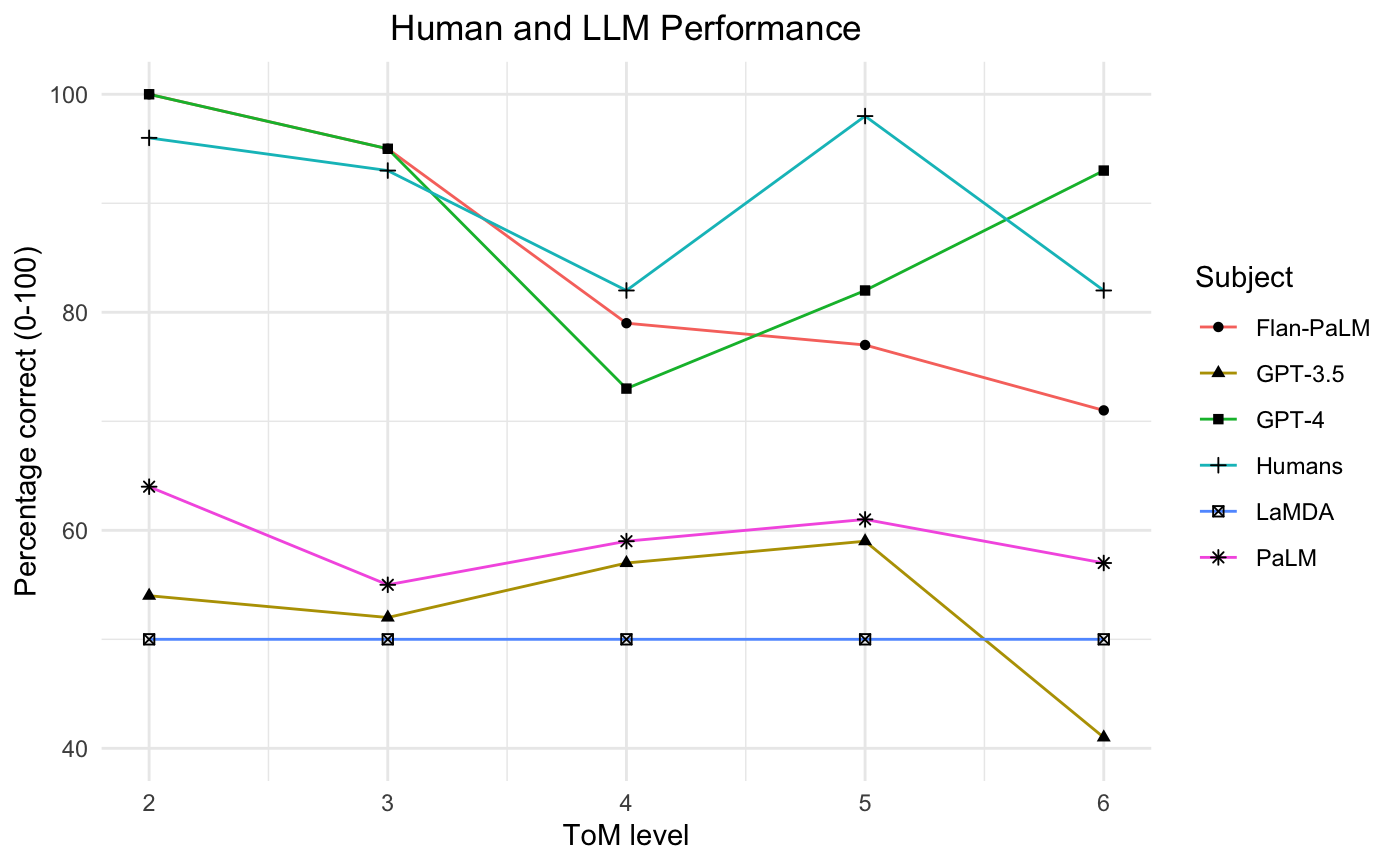
Abstract: This paper examines the extent to which LLMs have developed higher-order theory of mind (ToM); the human ability to reason about multiple mental and emotional states in a recursive manner (e.g. I think that you believe that she knows). This paper builds on prior work by introducing a handwritten test suite -- Multi-Order Theory of Mind Q&A -- and using it to compare the performance of five LLMs to a newly gathered adult human benchmark. We find that GPT-4 and Flan-PaLM reach adult-level and near adult-level performance on ToM tasks overall, and that GPT-4 exceeds adult performance on 6th order inferences. Our results suggest that there is an interplay between model size and finetuning for the realisation of ToM abilities, and that the best-performing LLMs have developed a generalised capacity for ToM. Given the role that higher-order ToM plays in a wide range of cooperative and competitive human behaviours, these findings have significant implications for user-facing LLM applications.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Paying attention to inattentive survey respondents. Political Analysis, 27(2):145–162, 2019.
- Does the autistic child have a “theory of mind”? Cognition, 21(1):37–46, 1985.
- Google colaboratory. Building machine learning and deep learning models on google cloud platform: a comprehensive guide for beginners, pages 59–64, 2019.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- The problematic concept of native speaker in psycholinguistics: Replacing vague and harmful terminology with inclusive and accurate measures. Frontiers in psychology, 12:715843, 2021.
- Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024.
- Michael C Corballis. The evolution of language. 2017.
- Negotiating with other minds: the role of recursive theory of mind in negotiation with incomplete information. Autonomous Agents and Multi-Agent Systems, 31:250–287, 2017.
- Higher-order theory of mind is especially useful in unpredictable negotiations. Autonomous Agents and Multi-Agent Systems, 36(2):30, 2022.
- Robin IM Dunbar. The social brain: mind, language, and society in evolutionary perspective. Annual review of Anthropology, 32(1):163–181, 2003.
- A mechanism-based approach to mitigating harms from persuasive generative ai. arXiv preprint arXiv:2404.15058, 2024.
- Camila Fernández. Mindful storytellers: Emerging pragmatics and theory of mind development. First Language, 33(1):20–46, 2013.
- The ethics of advanced ai assistants. arXiv preprint arXiv:2404.16244, 2024.
- Understanding social reasoning in language models with language models. Advances in Neural Information Processing Systems, 36, 2024.
- Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models. arXiv preprint arXiv:2310.16755, 2023.
- Fritz Heider. Attitudes and cognitive organization. The Journal of psychology, 21(1):107–112, 1946.
- Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701, 2020.
- Mentalizing about emotion and its relationship to empathy. Social cognitive and affective neuroscience, 3(3):204–217, 2008.
- Nicholas K Humphrey. The social function of intellect. 1976.
- Gender differences in verbal ability: A meta-analysis. Psychological bulletin, 104(1):53, 1988.
- IBM Corp. Released 2021. IBM SPSS Statistics for Windows, Version 28.0.1.0. Armonk, NY: IBM Corp.
- Limits on theory of mind use in adults. Cognition, 89(1):25–41, 2003.
- Theory-of-mind deficits and causal attributions. British journal of Psychology, 89(2):191–204, 1998.
- Michal Kosinski. Theory of mind may have spontaneously emerged in large language models. arXiv preprint arXiv:2302.02083, 2023.
- Theory of mind and emotion understanding predict moral development in early childhood. British Journal of Developmental Psychology, 28(4):871–889, 2010.
- Ventromedial prefrontal volume predicts understanding of others and social network size. Neuroimage, 57(4):1624–1629, 2011.
- Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. arXiv preprint arXiv:2104.08786, 2021.
- Bertram F Malle. How the mind explains behavior. Folk explanation, Meaning and social interaction. Massachusetts: MIT-Press, 2004.
- Patrick McGuiness. Gpt-4 details revealed. 12 July 2023. URL https://patmcguinness.substack.com/p/gpt-4-details-revealed.
- The debate over understanding in ai’s large language models. Proceedings of the National Academy of Sciences, 120(13):e2215907120, 2023.
- Steven Mithen. The prehistory of the mind: The cognitive origins of art and science. Thames & Hudson Ltd., 1996.
- The emergence of recursion in human language: Mentalising predicts recursive syntax task performance. Journal of Neurolinguistics, 43:95–106, 2017.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.