- The paper introduces PromptWizard, which iteratively refines prompt instructions and examples to maximize LLM performance.
- It employs a two-phase framework combining preprocessing via mutation and in-context example synthesis to adapt to diverse datasets.
- Evaluation across 35 tasks shows an average improvement of +5% and minimal performance loss with smaller models like Llama-2.
"PromptWizard: Task-Aware Prompt Optimization Framework" (2405.18369)
Introduction
The paper introduces PromptWizard, a framework designed to optimize the generation of prompts for LLMs across various tasks, enhancing model performance by automating prompt engineering. PromptWizard iteratively refines both prompt instructions and in-context learning examples to maximize efficacy. The framework employs a structured, gradient-free method suitable for scenarios where closed-source LLMs are accessed via APIs, setting it apart from prior automatic prompt optimization approaches.
Framework Overview
PromptWizard operates in two primary phases:
- Preprocessing Phase: Utilize LLMs as agents to perform tasks including prompt mutation, evaluation, synthesis of prompts and examples, and validation. This phase ensures computational efficiency and adaptability to datasets varying in size and data availability.
- Inference Phase: Application of the refined prompt and examples to dataset test samples, leveraging the optimized structure to guide LLM output.
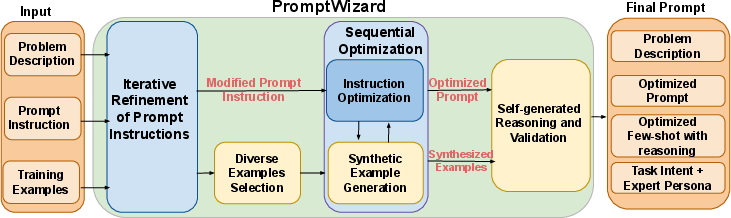
Figure 1: Overview of the framework.
The framework's core methodology involves several key processes:
- Iterative Refinement of Prompt Instructions: This involves generating diverse prompt variations through various cognitive heuristics and refining them based on performance evaluations.
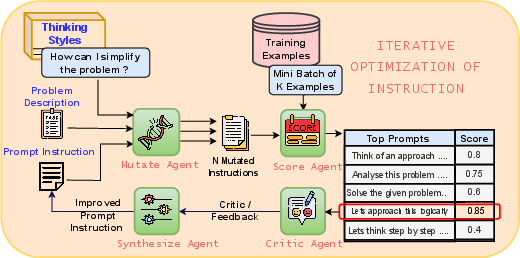
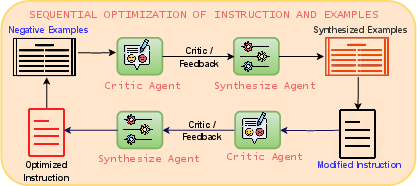
Figure 2: Iterative optimization of prompt instruction.
- Identification and Synthesis of Diverse Examples: Negative examples are strategically selected to ensure diversity and improved understanding, and new synthetic examples are generated to strengthen prompt accuracy.



Figure 3: Iterative Prompt Refinement.
Implementation Details
PromptWizard utilizes various LLM models, primarily employing GPT-4 and smaller variants like Llama-2 during different stages to maintain efficiency while ensuring effectiveness. The method systematically adjusts hyperparameters during pre-processing to balance exploration and optimization.
Evaluation and Results
The study evaluates PromptWizard across 35 tasks using 8 datasets, spanning domains including medical challenges and commonsense reasoning. It shows superior performance over existing methods like PromptBreeder, achieving an average improvement of +5% on benchmark test sets. Notably, on medical datasets like PubMedQA and MedQA, PromptWizard maintains competitive accuracy with significantly reduced computational overhead compared to methods like MedPrompt.
Efficacy with Limited Data and Smaller Models
PromptWizard demonstrates versatility across different data availabilities and model scales by maintaining high performance even with as few as 5 training examples. Tests with smaller models like Llama-2 suggest minimal degradation (<1%) in performance, highlighting the robustness and adaptability of the framework.
Ablation Studies
Ablation studies reveal the effectiveness of individual components of the framework, such as the mutation and scoring of prompts and the integration of self-generated reasoning with negative examples. These contribute significantly to the overall enhancement of LLM task performance.
Conclusion
PromptWizard exemplifies a significant advancement in prompt optimization by employing a comprehensive, agent-driven methodology that adjusts to varying task complexities and data constraints. Future work aims to improve validation processes for synthetic examples to further strengthen model robustness and reliability. This research highlights the potential for prompt engineering automation in enhancing LLM capabilities across a wide array of applications.


