From Neurons to Neutrons: A Case Study in Interpretability
Abstract: Mechanistic Interpretability (MI) promises a path toward fully understanding how neural networks make their predictions. Prior work demonstrates that even when trained to perform simple arithmetic, models can implement a variety of algorithms (sometimes concurrently) depending on initialization and hyperparameters. Does this mean neuron-level interpretability techniques have limited applicability? We argue that high-dimensional neural networks can learn low-dimensional representations of their training data that are useful beyond simply making good predictions. Such representations can be understood through the mechanistic interpretability lens and provide insights that are surprisingly faithful to human-derived domain knowledge. This indicates that such approaches to interpretability can be useful for deriving a new understanding of a problem from models trained to solve it. As a case study, we extract nuclear physics concepts by studying models trained to reproduce nuclear data.
- Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 7319–7328, 2021.
- Table of experimental nuclear ground state charge radii: An update. Atomic Data and Nuclear Data Tables, 99(1):69–95, January 2013. doi: 10.1016/j.adt.2011.12.006.
- Pca of high dimensional random walks with comparison to neural network training. Advances in Neural Information Processing Systems, 31, 2018.
- Slicegpt: Compress large language models by deleting rows and columns, 2024.
- WorldSense: A Synthetic Benchmark for Grounded Reasoning in Large Language Models. arXiv e-prints, art. arXiv:2311.15930, November 2023. doi: 10.48550/arXiv.2311.15930.
- Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013.
- Nuclear Physics A. Stationary States of Nuclei. Rev. Mod. Phys., 8:82–229, 1936. doi: 10.1103/RevModPhys.8.82.
- Bowman, S. R. Eight Things to Know about Large Language Models. arXiv e-prints, art. arXiv:2304.00612, April 2023. doi: 10.48550/arXiv.2304.00612.
- Understanding disentangling in β𝛽\betaitalic_β-vae. In NeurIPS Workshop on Learning Disentangled Representations, 2018.
- Isolating sources of disentanglement in variational autoencoders. In Advances in Neural Information Processing Systems, pp. 2610–2620, 2018.
- Cranmer, M. Interpretable machine learning for science with pysr and symbolicregression. jl. arXiv preprint arXiv:2305.01582, 2023.
- Discovery of a planar black hole mass scaling relation for spiral galaxies. The Astrophysical Journal Letters, 956(1):L22, 2023.
- QLoRA: Efficient Finetuning of Quantized LLMs. arXiv e-prints, art. arXiv:2305.14314, May 2023. doi: 10.48550/arXiv.2305.14314.
- A mathematical framework for transformer circuits. Transformer Circuits Thread, 2021. https://transformer-circuits.pub/2021/framework/index.html.
- Language Models Represent Space and Time. arXiv e-prints, art. arXiv:2310.02207, October 2023. doi: 10.48550/arXiv.2310.02207.
- How much does attention actually attend? questioning the importance of attention in pretrained transformers. arXiv preprint arXiv:2211.03495, 2022.
- Towards a definition of disentangled representations. arXiv preprint arXiv:1812.02230, 2018.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Saliency, scale and image description. International Journal of Computer Vision, 45(2):83–105, 2001.
- Disentangling by factorising. In International Conference on Machine Learning, pp. 2649–2658. PMLR, 2018.
- Kirson, M. W. Mutual influence of terms in a semi-empirical mass formula. Nucl. Phys. A, 798:29–60, 2008. doi: 10.1016/j.nuclphysa.2007.10.011.
- Analysis of neuronal ensemble activity reveals the pitfalls and shortcomings of rotation dynamics. Scientific Reports, 9(1):18978, 2019.
- Rediscovering orbital mechanics with machine learning. Machine Learning: Science and Technology, 4(4):045002, 2023.
- Measuring the intrinsic dimension of objective landscapes. In International Conference on Learning Representations, 2018.
- Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task. arXiv e-prints, art. arXiv:2210.13382, October 2022. doi: 10.48550/arXiv.2210.13382.
- Towards understanding grokking: An effective theory of representation learning. Advances in Neural Information Processing Systems, 35:34651–34663, 2022.
- Challenging common assumptions in the unsupervised learning of disentangled representations. In International Conference on Machine Learning, pp. 4114–4124. PMLR, 2019.
- Interpretable machine learning methods applied to jet background subtraction in heavy ion collisions. arXiv preprint arXiv:2303.08275, 2023.
- Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
- Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217, 2023.
- Interpreting principal component analyses of spatial population genetic variation. Nature genetics, 40(5):646–649, 2008.
- Olah, C. Mechanistic interpretability, variables, and the importance of interpretable bases. Transformer Circuits Thread, 2022. https://transformer-circuits.pub/2022/mech-interp-essay/index.html.
- Feature visualization. Distill, 2017. URL https://distill.pub/2017/feature-visualization/.
- Pauli, W. Über den zusammenhang des abschlusses der elektronengruppen im atom mit der komplexstruktur der spektren. Zeitschrift für Physik, 31(1):765–783, Feb 1925. ISSN 0044-3328. doi: 10.1007/BF02980631. URL https://doi.org/10.1007/BF02980631.
- Interpreting dynamics of neural activity after dimensionality reduction. bioRxiv, pp. 2022–03, 2022.
- GPT4GEO: How a Language Model Sees the World’s Geography. arXiv e-prints, art. arXiv:2306.00020, May 2023. doi: 10.48550/arXiv.2306.00020.
- Shinn, M. Phantom oscillations in principal component analysis. bioRxiv, pp. 2023–06, 2023.
- Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
- The AME 2020 atomic mass evaluation (II). Tables, graphs and references. Chin. Phys. C, 45(3):030003, 2021. doi: 10.1088/1674-1137/abddaf.
- Weizsäcker, C. F. v. Zur theorie der kernmassen. Zeitschrift für Physik, 96(7):431–458, Jul 1935. ISSN 0044-3328. doi: 10.1007/BF01337700. URL https://doi.org/10.1007/BF01337700.
- Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13, pp. 818–833. Springer, 2014.
- AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning. arXiv e-prints, art. arXiv:2303.10512, March 2023. doi: 10.48550/arXiv.2303.10512.
- A survey on neural network interpretability. IEEE Transactions on Emerging Topics in Computational Intelligence, 5(5):726–742, 2021. doi: 10.1109/TETCI.2021.3100641.
- The clock and the pizza: Two stories in mechanistic explanation of neural networks. arXiv preprint arXiv:2306.17844, 2023.
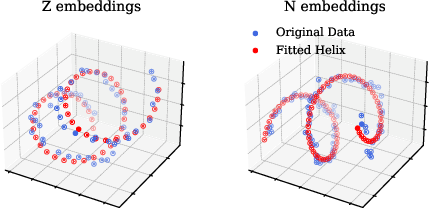
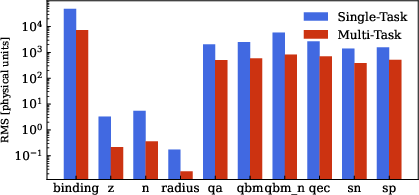
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

