An Introduction to Vision-Language Modeling
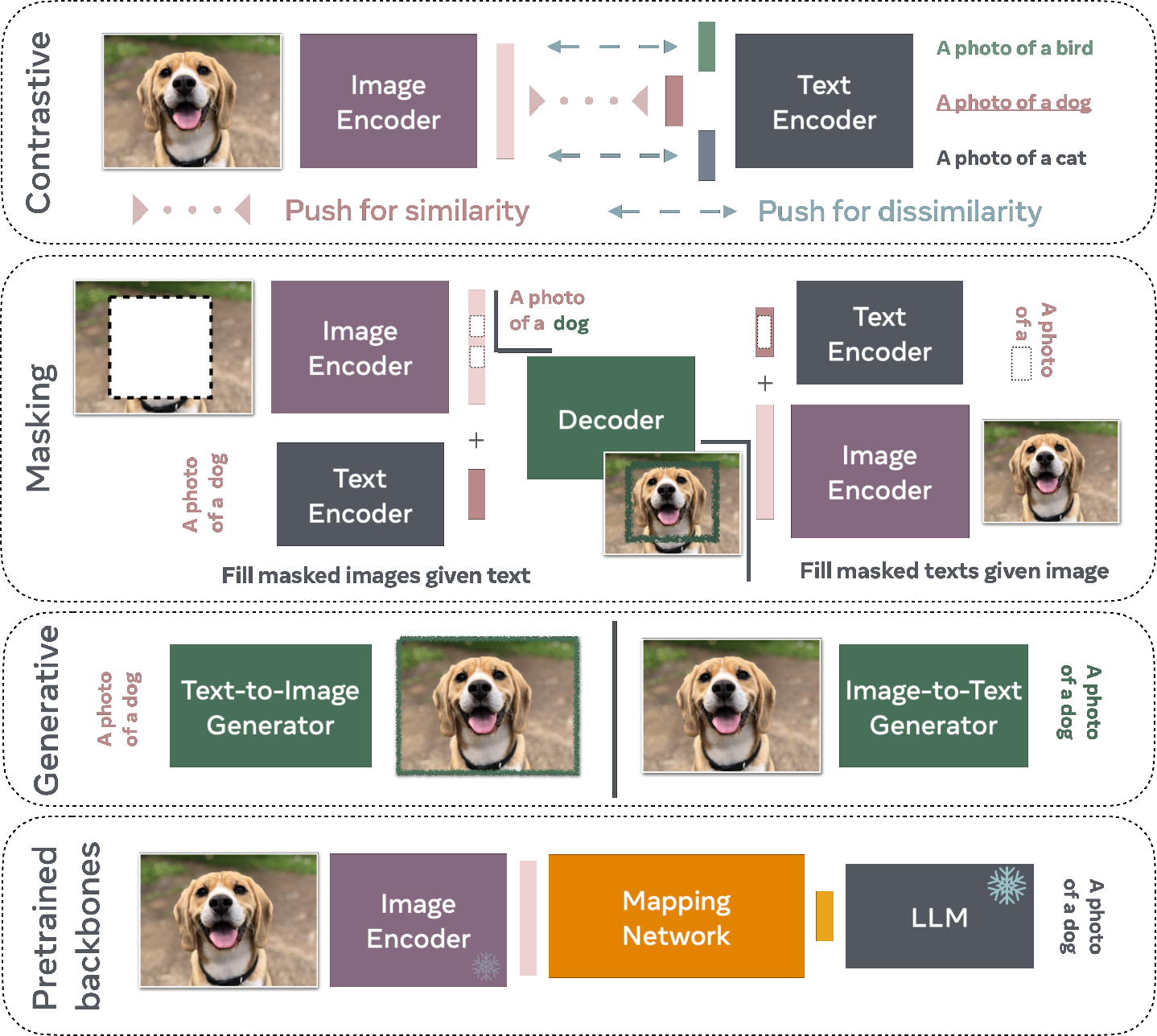
Abstract: Following the recent popularity of LLMs, several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-LLM (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
- GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Evaluating CLIP: towards characterization of broader capabilities and downstream implications. arXiv preprint arXiv:2108.02818, 2021.
- Reassessing evaluation practices in visual question answering: A case study on out-of-distribution generalization. In Findings of the Association for Computational Linguistics: EACL 2023, pages 1171–1196, 2023.
- Yi: Open foundation models by 01.ai, 2024.
- Unsupervised learning from narrated instruction videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4575–4583, 2016.
- Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- VQA: Visual Question Answering. In International Conference on Computer Vision (ICCV), 2015.
- Self-supervised learning from images with a joint-embedding predictive architecture. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15619–15629, 2023. doi: 10.1109/CVPR52729.2023.01499.
- MiniGPT4-Video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens. arXiv preprint arXiv:2404.03413, 2024.
- OpenFlamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390, 2023.
- Investigating prompting techniques for zero-and few-shot visual question answering. arXiv preprint arXiv:2306.09996, 2023.
- Synthetic data from diffusion models improves imagenet classification. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=DlRsoxjyPm.
- Qwen technical report. arXiv preprint arXiv:2309.16609, 2023a.
- Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023b.
- Learning by reconstruction produces uninformative features for perception. arXiv preprint arXiv:2402.11337, 2024.
- Leaving reality to imagination: Robust classification via generated datasets. arXiv preprint arXiv:2302.02503, 2023.
- A prompt array keeps the bias away: Debiasing vision-language models with adversarial learning. In Yulan He, Heng Ji, Sujian Li, Yang Liu, and Chua-Hui Chang, editors, Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 806–822, Online only, November 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.aacl-main.61.
- Safety-tuned LLaMAs: Lessons from improving the safety of large language models that follow instructions. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=gT5hALch9z.
- Renaissance: A survey into ai text-to-image generation in the era of large model. arXiv preprint arXiv:2309.00810, 2023.
- ICDAR 2019 competition on scene text visual question answering. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1563–1570. IEEE, 2019.
- Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. Advances in Neural Information Processing Systems, 29, 2016.
- High fidelity visualization of what your self-supervised representation knows about. Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=urfWb7VjmL.
- Pug: Photorealistic and semantically controllable synthetic data for representation learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 45020–45054. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/8d352fd0f07fde4a74f9476603b3773b-Paper-Datasets_and_Benchmarks.pdf.
- Food-101 – mining discriminative components with random forests. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors, Computer Vision – European Conference on Computer Vision 2014, pages 446–461, Cham, 2014. Springer International Publishing. ISBN 978-3-319-10599-4.
- High-performance large-scale image recognition without normalization. In International Conference on Machine Learning, pages 1059–1071. PMLR, 2021.
- Video generation models as world simulators, 2024. URL https://openai.com/research/video-generation-models-as-world-simulators.
- Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
- Gender shades: Intersectional accuracy disparities in commercial gender classification. In Sorelle A. Friedler and Christo Wilson, editors, Proceedings of the 1st Conference on Fairness, Accountability and Transparency, volume 81 of Proceedings of Machine Learning Research, pages 77–91. PMLR, 23–24 Feb 2018. URL https://proceedings.mlr.press/v81/buolamwini18a.html.
- Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650, 2021.
- Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23), pages 5253–5270, 2023.
- Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems, 33:9912–9924, 2020.
- Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660, 2021.
- Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3558–3568, 2021.
- Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL-2011), Portland, OR, June 2011.
- Vlp: A survey on vision-language pre-training. Machine Intelligence Research, 20(1):38–56, January 2023a. ISSN 2731-5398. doi: 10.1007/s11633-022-1369-5. URL http://dx.doi.org/10.1007/s11633-022-1369-5.
- MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478, 2023b.
- Pixart-α𝛼\alphaitalic_α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=eAKmQPe3m1.
- A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning, pages 1597–1607. PMLR, 2020.
- VideoOFA: Two-stage pre-training for video-to-text generation. arXiv preprint arXiv:2305.03204, 2023c. URL https://arxiv.org/abs/2305.03204.
- Microsoft COCO captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Visual programming for text-to-image generation and evaluation. arXiv preprint arXiv:2305.15328, 2023.
- Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ITq4ZRUT4a.
- Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024. URL http://jmlr.org/papers/v25/23-0870.html.
- Text-to-image diffusion models are zero shot classifiers. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=fxNQJVMwK2.
- Algorithmic decision making and the cost of fairness. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, page 797–806, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450348874. doi: 10.1145/3097983.3098095. URL https://doi.org/10.1145/3097983.3098095.
- Emu: Enhancing image generation models using photogenic needles in a haystack. arXiv preprint arXiv:2309.15807, 2023.
- Improving selective visual question answering by learning from your peers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24049–24059, 2023.
- Visual dialog. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 326–335, 2017.
- Does object recognition work for everyone? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2019.
- Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848.
- Assessing language model deployment with risk cards. arXiv preprint arXiv:2303.18190, 2023.
- QLoRA: Efficient finetuning of quantized LLMs. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=OUIFPHEgJU.
- BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https://aclanthology.org/N19-1423.
- Why is winoground hard? investigating failures in visuolinguistic compositionality. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2236–2250, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.143. URL https://aclanthology.org/2022.emnlp-main.143.
- An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=YicbFdNTTy.
- A survey of vision-language pre-trained models, 2022.
- Lossy compression for lossless prediction. Advances in Neural Information Processing Systems, 34:14014–14028, 2021.
- Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021.
- The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88(2):303–338, June 2010.
- Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6824–6835, 2021.
- Learning robust representations via multi-view information bottleneck. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=B1xwcyHFDr.
- Masked autoencoders as spatiotemporal learners. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=UaXD4Al3mdb.
- Improved baselines for vision-language pre-training. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=a7nvXxNmdV. Featured Certification.
- Ronald A Fisher. The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2):179–188, 1936.
- Datacomp: In search of the next generation of multimodal datasets. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=dVaWCDMBof.
- Make-a-scene: Scene-based text-to-image generation with human priors. In European Conference on Computer Vision, pages 89–106. Springer, 2022.
- Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- Clip-adapter: Better vision-language models with feature adapters. International Journal of Computer Vision, 132(2):581–595, 2024.
- Uncurated image-text datasets: Shedding light on demographic bias. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6957–6966, 2023.
- Exploring the frontier of vision-language models: A survey of current methodologies and future directions, 2024.
- Cyclip: Cyclic contrastive language-image pretraining. Advances in Neural Information Processing Systems, 35:6704–6719, 2022.
- Fairness indicators for systematic assessments of visual feature extractors. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 70–88, 2022.
- Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2017.
- Bootstrap your own latent-a new approach to self-supervised learning. Advances in Neural Information Processing Systems, 33:21271–21284, 2020.
- Detecting and preventing hallucinations in large vision language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18135–18143, 2024.
- Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3608–3617, 2018.
- Facet: Fairness in computer vision evaluation benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20370–20382, October 2023.
- Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pages 297–304. JMLR Workshop and Conference Proceedings, March 2010.
- Towards reliable assessments of demographic disparities in multi-label image classifiers, 2023a.
- Vision-language models performing zero-shot tasks exhibit disparities between gender groups. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 2778–2785, October 2023b.
- Identifying implicit social biases in vision-language models, 2023.
- Synthclip: Are we ready for a fully synthetic clip training? arXiv preprint arXiv:2402.01832, 2024.
- The bias of harmful label associations in vision-language models. arXiv preprint arXiv: 2402.07329, 2024.
- Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015.
- Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
- Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022.
- Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019.
- Feedback-guided data synthesis for imbalanced classification. arXiv preprint arXiv:2310.00158, 2023.
- Scaling laws for autoregressive generative modeling. ArXiv, abs/2010.14701, 2020a. URL https://api.semanticscholar.org/CorpusID:225094178.
- Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701, 2020b.
- CLIPScore: A reference-free evaluation metric for image captioning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7514–7528, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.595. URL https://aclanthology.org/2021.emnlp-main.595.
- Cogagent: A visual language model for gui agents, 2023.
- spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing, 2017.
- Parameter-efficient transfer learning for NLP. In International Conference on Machine Learning, pages 2790–2799. PMLR, 2019.
- Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=Jsc7WSCZd4.
- LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023.
- A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232, 2023.
- ICDAR 2019 competition on scanned receipt ocr and information extraction. In 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, September 2019. doi: 10.1109/icdar.2019.00244. URL http://dx.doi.org/10.1109/ICDAR.2019.00244.
- GQA: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6700–6709, 2019.
- Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(Apr):695–709, 2005.
- Openclip, July 2021. URL https://doi.org/10.5281/zenodo.5143773. If you use this software, please cite it as below.
- Intriguing properties of generative classifiers. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=rmg0qMKYRQ.
- Grasp: A novel benchmark for evaluating language grounding and situated physics understanding in multimodal language models. arXiv preprint arXiv:2311.09048, 2023.
- Funsd: A dataset for form understanding in noisy scanned documents. In 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), volume 2, pages 1–6. IEEE, 2019.
- Déjà vu memorization in vision-language models. arXiv preprint arXiv:2402.02103, 2024.
- Visual prompt tuning. In European Conference on Computer Vision, pages 709–727. Springer, 2022.
- Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- Bag of tricks for efficient text classification. In Mirella Lapata, Phil Blunsom, and Alexander Koller, editors, Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 427–431, Valencia, Spain, April 2017. Association for Computational Linguistics. URL https://aclanthology.org/E17-2068.
- ICDAR 2013 robust reading competition. In 2013 12th International Conference on Document Analysis and Recognition, pages 1484–1493, 2013.
- Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1548–1558, 2021.
- VILA: Learning image aesthetics from user comments with vision-language pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10041–10051, 2023.
- Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, October 2023.
- VeRA: Vector-based random matrix adaptation. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=NjNfLdxr3A.
- 3d object representations for fine-grained categorization. In Proceedings - 2013 IEEE International Conference on Computer Vision Workshops, ICCVW 2013, Proceedings of the IEEE International Conference on Computer Vision, pages 554–561, United States, 2013. Institute of Electrical and Electronics Engineers Inc. ISBN 9781479930227. doi: 10.1109/ICCVW.2013.77. 2013 14th IEEE International Conference on Computer Vision Workshops, ICCVW 2013 ; Conference date: 01-12-2013 Through 08-12-2013.
- A hierarchical approach for generating descriptive image paragraphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 317–325, 2017.
- Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123:32–73, 2017.
- Alex Krizhevsky. Learning multiple layers of features from tiny images, 2009. URL https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf.
- Visual information extraction in the wild: Practical dataset and end-to-end solution. In Gernot A. Fink, Rajiv Jain, Koichi Kise, and Richard Zanibbi, editors, Document Analysis and Recognition – ICDAR 2023, pages 36–53, Cham, 2023. Springer Nature Switzerland. ISBN 978-3-031-41731-3.
- MMOCR: a comprehensive toolbox for text detection, recognition and understanding. In Proceedings of the 29th ACM International Conference on Multimedia, pages 3791–3794, 2021.
- Masked vision and language modeling for multi-modal representation learning. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=ZhuXksSJYWn.
- OBELICS: An open web-scale filtered dataset of interleaved image-text documents. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=SKN2hflBIZ.
- Modeling caption diversity in contrastive vision-language pretraining. arXiv preprint arXiv:2405.00740, 2024.
- FFCV: Accelerating training by removing data bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12011–12020, 2023.
- Convolutional Networks for Images, Speech, and Time Series, page 255–258. MIT Press, Cambridge, MA, USA, 1998. ISBN 0262511029.
- A tutorial on energy-based learning, 2006.
- Holistic evaluation of text-to-image models. Advances in Neural Information Processing Systems, 36, 2024.
- xformers: A modular and hackable transformer modelling library. https://github.com/facebookresearch/xformers, 2022.
- Tvqa: Localized, compositional video question answering. In EMNLP, 2018.
- Your diffusion model is secretly a zero-shot classifier. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2206–2217, October 2023a.
- Evaluating and improving compositional text-to-visual generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024a.
- MIMIC-IT: Multi-modal in-context instruction tuning. arXiv preprint arXiv:2306.05425, 2023b.
- Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726, 2023c.
- Vision-language instruction tuning: A review and analysis. arXiv preprint arXiv: 2311.08172, 2023d.
- Caltech 101, avr 2022a.
- BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022b.
- BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 19730–19742. PMLR, 23–29 Jul 2023e. URL https://proceedings.mlr.press/v202/li23q.html.
- VisualBERT: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557, 2019.
- Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10965–10975, 2022c.
- Red teaming visual language models. arXiv preprint arXiv:2401.12915, 2024b.
- Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208, 2021.
- Scaling language-image pre-training via masking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23390–23400, 2023f.
- Yi Li and Nuno Vasconcelos. Debias your VLM with counterfactuals: A unified approach, 2024. URL https://openreview.net/forum?id=xx05gm7oQw.
- Evaluating object hallucination in large vision-language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305, Singapore, December 2023g. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.20. URL https://aclanthology.org/2023.emnlp-main.20.
- TGIF: A New Dataset and Benchmark on Animated GIF Description. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- Monkey: Image resolution and text label are important things for large multi-modal models. arXiv preprint arXiv:2311.06607, 2023h.
- Foundations & trends in multimodal machine learning: Principles, challenges, and open questions. ACM Comput. Surv., apr 2024. ISSN 0360-0300. doi: 10.1145/3656580. URL https://doi.org/10.1145/3656580. Just Accepted.
- Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022.
- Video-LLaVA: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122, 2023.
- Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Microsoft COCO: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Revisiting the role of language priors in vision-language models. arXiv preprint arXiv:2306.01879, 2024a.
- Evaluating text-to-visual generation with image-to-text generation. arXiv preprint arXiv:2404.01291, 2024b.
- Visual spatial reasoning. Transactions of the Association for Computational Linguistics, 11:635–651, 2023a. doi: 10.1162/tacl_a_00566. URL https://aclanthology.org/2023.tacl-1.37.
- Aligning large multi-modal model with robust instruction tuning. arXiv preprint arXiv:2306.14565, 2023b.
- Improved baselines with visual instruction tuning. arXiv preprint arXiv: 2310.03744, 2023c.
- Visual instruction tuning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 34892–34916. Curran Associates, Inc., 2023d. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/6dcf277ea32ce3288914faf369fe6de0-Paper-Conference.pdf.
- Llava-next: Improved reasoning, ocr, and world knowledge, January 2024a. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/.
- DoRA: Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353, 2024b.
- On the hidden mystery of OCR in large multimodal models. arXiv preprint arXiv:2305.07895, 2023e.
- Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/c74d97b01eae257e44aa9d5bade97baf-Paper.pdf.
- Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35:2507–2521, 2022.
- CREPE: Can vision-language foundation models reason compositionally? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10910–10921, 2023.
- Sieve: Multimodal dataset pruning using image captioning models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024.
- T-MARS: Improving visual representations by circumventing text feature learning. arXiv preprint arXiv:2307.03132, 2023.
- Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151, 2013.
- MAPL: Parameter-efficient adaptation of unimodal pre-trained models for vision-language few-shot prompting. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2523–2548, 2023.
- Improving automatic VQA evaluation using large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4171–4179, 2024.
- Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems, 36, 2024.
- OK-VQA: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3195–3204, 2019.
- ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Findings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-acl.177. URL https://aclanthology.org/2022.findings-acl.177.
- DocVQA: A dataset for vqa on document images. In 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 2199–2208, 2021. doi: 10.1109/WACV48630.2021.00225.
- InfographicVQA. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1697–1706, 2022.
- Tangled up in BLEU: Reevaluating the evaluation of automatic machine translation evaluation metrics. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4984–4997, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.448. URL https://aclanthology.org/2020.acl-main.448.
- MM1: Methods, analysis & insights from multimodal llm pre-training. arXiv preprint arXiv:2403.09611, 2024.
- Visual classification via description from large language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=jlAjNL8z5cs.
- Linearly mapping from image to text space. In The Eleventh International Conference on Learning Representations, 2022.
- Top-down and bottom-up cues for scene text recognition. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 2687–2694, 2012. doi: 10.1109/CVPR.2012.6247990.
- OCR-VQA: Visual question answering by reading text in images. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 947–952. IEEE, 2019.
- Verbs in action: Improving verb understanding in video-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15579–15591, 2023.
- SLIP: Self-supervision meets language-image pre-training. In European Conference on Computer Vision, pages 529–544. Springer, 2022.
- On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. Advances in Neural Information Processing Systems, 14, 2001.
- Improving multimodal datasets with image captioning. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=VIRKdeFJIg.
- Automated flower classification over a large number of classes. 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, pages 722–729, 2008. URL https://api.semanticscholar.org/CorpusID:15193013.
- Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Im2text: Describing images using 1 million captioned photographs. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011. URL https://proceedings.neurips.cc/paper_files/paper/2011/file/5dd9db5e033da9c6fb5ba83c7a7ebea9-Paper.pdf.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics, pages 311–318. Association for Computational Linguistics, 2002.
- Prompting scientific names for zero-shot species recognition. arXiv preprint arXiv:2310.09929, 2023.
- The neglected tails of vision-language models. arXiv preprint arXiv:2401.12425, 2024.
- Cats and dogs. In IEEE Conference on Computer Vision and Pattern Recognition, 2012.
- Context encoders: Feature learning by inpainting. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2536–2544, 2016. doi: 10.1109/CVPR.2016.278.
- Grounding multimodal large language models to the world. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=lLmqxkfSIw.
- Red teaming language models with language models. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.225. URL https://aclanthology.org/2022.emnlp-main.225.
- Test-time adaptation of discriminative models via diffusion generative feedback. arXiv preprint arXiv:2311.16102, 2023.
- What does a platypus look like? generating customized prompts for zero-shot image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15691–15701, 2023.
- Filtering, distillation, and hard negatives for vision-language pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6967–6977, 2023a.
- Filtering, distillation, and hard negatives for vision-language pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6967–6977, 2023b.
- Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8748–8763. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/radford21a.html.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Object hallucination in image captioning. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1437. URL https://aclanthology.org/D18-1437.
- High-resolution image synthesis with latent diffusion models, 2021.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- Measuring social biases in grounded vision and language embeddings. arXiv preprint arXiv:2002.08911, 2020.
- Discriminative vs informative learning. In KDD, volume 5, pages 49–53, 1997.
- Safetyprompts: a systematic review of open datasets for evaluating and improving large language model safety, 2024.
- How to train data-efficient LLMs. arXiv preprint arXiv:2402.09668, 2024.
- Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022.
- Align your prompts: Test-time prompting with distribution alignment for zero-shot generalization. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=CusNOTRkQw.
- Is a caption worth a thousand images? A controlled study for representation learning. arXiv preprint arXiv:2207.07635, 2022.
- From human to data to dataset: Mapping the traceability of human subjects in computer vision datasets. Proceedings of the ACM on Human-Computer Interaction, 7(CSCW1):1–33, 2023.
- Christoph Schuhmann. Laion-aesthetics. https://laion.ai/blog/laion-aesthetics/, 2023.
- Laion-400m: Open dataset of CLIP-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Laion-5b: An open large-scale dataset for training next generation image-text models, 2022.
- A-okvqa: A benchmark for visual question answering using world knowledge. In European Conference on Computer Vision, pages 146–162. Springer, 2022.
- Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia, July 2018a. Association for Computational Linguistics. doi: 10.18653/v1/P18-1238. URL https://aclanthology.org/P18-1238.
- Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018b.
- Text quality-based pruning for efficient training of language models. arXiv preprint arXiv:2405.01582, 2024.
- Lumos: Empowering multimodal llms with scene text recognition. arXiv preprint arXiv:2402.08017, 2024.
- End-to-end scene text recognition using tree-structured models. Pattern Recognition, 47:2853–2866, 2014.
- To compress or not to compress—self-supervised learning and information theory: A review. Entropy, 26(3):252, 2024.
- Getting MoRE out of Mixture of language model Reasoning Experts. Findings of Empirical Methods in Natural Language Processing, 2023.
- Towards VQA models that can read. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8317–8326, 2019.
- Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15638–15650, 2022.
- Balancing the picture: Debiasing vision-language datasets with synthetic contrast sets. arXiv preprint arXiv:2305.15407, 2023.
- Diffusion art or digital forgery? Investigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6048–6058, 2023.
- Beyond neural scaling laws: beating power law scaling via data pruning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=UmvSlP-PyV.
- Worst of both worlds: Biases compound in pre-trained vision-and-language models. arXiv preprint arXiv:2104.08666, 2021.
- Pandagpt: One model to instruction-follow them all. arXiv preprint arXiv:2305.16355, 2023.
- Videobert: A joint model for video and language representation learning. In ICCV, 2019.
- TrustLLM: Trustworthiness in large language models. arXiv preprint arXiv:2401.05561, 2024.
- Aligning large multimodal models with factually augmented rlhf. arXiv preprint arXiv:2309.14525, 2023.
- Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5227–5237, 2022.
- MovieQA: Understanding stories in movies through question-answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4631–4640, 2016.
- Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818, 2024.
- Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022.
- Learning vision from models rivals learning vision from data. arXiv preprint arXiv:2312.17742, 2023a.
- Stablerep: Synthetic images from text-to-image models make strong visual representation learners. In Thirty-seventh Conference on Neural Information Processing Systems, 2023b. URL https://openreview.net/forum?id=xpjsOQtKqx.
- Llama: Open and efficient foundation language models, 2023.
- Multimodal few-shot learning with frozen language models. Advances in Neural Information Processing Systems, 34:200–212, 2021.
- No “zero-shot” without exponential data: Pretraining concept frequency determines multimodal model performance. arXiv preprint arXiv:2404.04125, 2024.
- Multimodal research in vision and language: A review of current and emerging trends. Information Fusion, 77:149–171, 2022.
- A picture is worth more than 77 text tokens: Evaluating clip-style models on dense captions. arXiv preprint arXiv:2312.08578, 2023.
- Improved baselines for data-efficient perceptual augmentation of LLMs. arXiv preprint arXiv:2403.13499, 2024.
- Neural discrete representation learning. Advances in Neural Information Processing Systems, 30, 2017.
- Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- COCO-Text: Dataset and benchmark for text detection and recognition in natural images. arXiv preprint arXiv:1601.07140, 2016.
- Simplesafetytests: a test suite for identifying critical safety risks in large language models. arXiv preprint arXiv:2311.08370, 2023.
- Pascal Vincent. A connection between score matching and denoising autoencoders. Neural Computation, 23(7):1661–1674, 2011.
- Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, ICML ’08, page 1096–1103, New York, NY, USA, 2008. Association for Computing Machinery. ISBN 9781605582054. doi: 10.1145/1390156.1390294. URL https://doi.org/10.1145/1390156.1390294.
- Caltech-ucsd birds-200-2011. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011.
- OFA: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors, Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 23318–23340. PMLR, 17–23 Jul 2022. URL https://proceedings.mlr.press/v162/wang22al.html.
- Equivariant similarity for vision-language foundation models. arXiv preprint arXiv:2303.14465, 2023a.
- Cogvlm: Visual expert for pretrained language models, 2023b.
- On the general value of evidence, and bilingual scene-text visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10126–10135, 2020.
- Taxonomy of risks posed by language models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 214–229, 2022.
- Qurating: Selecting high-quality data for training language models. arXiv preprint arXiv:2402.09739, 2024.
- Reliable visual question answering: Abstain rather than answer incorrectly. In European Conference on Computer Vision, pages 148–166. Springer, 2022.
- Discovering bugs in vision models using off-the-shelf image generation and captioning. arXiv preprint arXiv:2208.08831, 2022.
- American == white in multimodal language-and-image ai. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, pages 800–812, 2022.
- Contrastive language-vision ai models pretrained on web-scraped multimodal data exhibit sexual objectification bias. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pages 1174–1185, 2023.
- Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3733–3742, 2018.
- Video question answering via gradually refined attention over appearance and motion. In Proceedings of the 25th ACM International Conference on Multimedia, pages 1645–1653, 2017.
- Demystifying clip data. In International Conference on Learning Representations, 2024. URL https://openreview.net/pdf?id=5BCFlnfE1g.
- MSR-VTT: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016.
- Jointly modeling deep video and compositional text to bridge vision and language in a unified framework. In Proceedings of the AAAI conference on artificial intelligence, volume 29, 2015.
- Panoptic video scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18675–18685, 2023.
- Vector-quantized image modeling with improved VQGAN. In International Conference on Learning Representations, 2022a. URL https://openreview.net/forum?id=pfNyExj7z2.
- Coca: Contrastive captioners are image-text foundation models. Transactions on Machine Learning Research, 2022b. ISSN 2835-8856. URL https://openreview.net/forum?id=Ee277P3AYC.
- Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789, 2(3):5, 2022c.
- Scaling autoregressive multi-modal models: Pretraining and instruction tuning. arXiv preprint arXiv:2309.02591, 2023.
- Activitynet-qa: A dataset for understanding complex web videos via question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 9127–9134, 2019.
- Syntax-aware network for handwritten mathematical expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4553–4562, June 2022.
- MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI. arXiv preprint arXiv:2311.16502, 2023.
- Vision as bayesian inference: analysis by synthesis? Trends in Cognitive Sciences, 10(7):301–308, 2006.
- When and why vision-language models behave like bags-of-words, and what to do about it? In International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=KRLUvxh8uaX.
- Barlow twins: Self-supervised learning via redundancy reduction. In International Conference on Machine Learning, pages 12310–12320. PMLR, 2021.
- Merlot: Multimodal neural script knowledge models. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 23634–23651. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/file/c6d4eb15f1e84a36eff58eca3627c82e-Paper.pdf.
- Multi-grained vision language pre-training: Aligning texts with visual concepts. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors, International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 25994–26009. PMLR, 2022. URL https://proceedings.mlr.press/v162/zeng22c.html.
- Halle-switch: Rethinking and controlling object existence hallucinations in large vision language models for detailed caption. arXiv preprint arXiv:2310.01779, 2023a.
- Sigmoid loss for language image pre-training. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 11941–11952, Los Alamitos, CA, USA, oct 2023b. IEEE Computer Society. doi: 10.1109/ICCV51070.2023.01100. URL https://doi.ieeecomputersociety.org/10.1109/ICCV51070.2023.01100.
- Text-to-image diffusion model in generative AI: A survey. arXiv preprint arXiv:2303.07909, 2023a.
- Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. In Yansong Feng and Els Lefever, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, Singapore, December 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-demo.49. URL https://aclanthology.org/2023.emnlp-demo.49.
- Vision-language models for vision tasks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024a.
- MagicBrush: A manually annotated dataset for instruction-guided image editing. Advances in Neural Information Processing Systems, 36, 2024b.
- D-VAE: A variational autoencoder for directed acyclic graphs. In Advances in Neural Information Processing Systems, pages 1586–1598, 2019.
- OPT: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- LLaVAR: Enhanced visual instruction tuning for text-rich image understanding. arXiv preprint arXiv:2306.17107, 2023c.
- Recognize anything: A strong image tagging model. arXiv preprint arXiv:2306.03514, 2023d.
- Videoprism: A foundational visual encoder for video understanding. arXiv preprint arXiv:2402.13217, 2024.
- Vl-checklist: Evaluating pre-trained vision-language models with objects, attributes and relations. arXiv preprint arXiv:2207.00221, 2022.
- MiniGPT-5: Interleaved vision-and-language generation via generative vokens. arXiv preprint arXiv:2310.02239, 2023.
- Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9):2337–2348, 2022.
- Vision + language applications: A survey. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 826–842, June 2023.
- MiniGPT-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023a.
- Multimodal c4: An open, billion-scale corpus of images interleaved with text. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 8958–8974. Curran Associates, Inc., 2023b. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/1c6bed78d3813886d3d72595dbecb80b-Paper-Datasets_and_Benchmarks.pdf.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

