- The paper introduces SIMA, a self-improvement framework that leverages self-generated responses and an in-context self-critic mechanism to enhance visual-language alignment.
- It details a three-stage methodology—Response Self-Generation, In-Context Self-Critic, and Preference Tuning—to systematically refine model performance.
- Empirical results show a 7.5% performance boost across 14 benchmarks, significantly mitigating hallucinations in LVLMs.
Enhancing Visual-Language Modality Alignment in LVLMs via Self-Improvement
Introduction
Large Vision-LLMs (LVLMs) have emerged as pivotal tools in visual question answering and reasoning tasks, showing remarkable performance through vision instruction tuning. Despite these advancements, the alignment between visual and language modalities in LVLMs remains suboptimal. Traditional methods for improving this alignment often depend on external models and data, inherently limiting performance due to constraints on external capabilities. This study introduces the Self-Improvement Modality Alignment (SIMA) framework, which enhances modality alignment by leveraging self-generated responses and an in-context self-critic mechanism, thus negating the need for external resources.
Methodology
The SIMA framework comprises three principal stages: Response Self-Generation, In-Context Self-Critic, and Preference Tuning.
Response Self-Generation: The initial stage involves creating response candidates from visual instruction tuning datasets using the model's intrinsic capabilities, thereby ensuring the generated responses reflect the model's current understanding and potential shortcomings.
In-Context Self-Critic: This stage employs a mechanism where the model evaluates the self-generated responses. A critic prompt, informed by three visual metrics—Accuracy in Object Description, Accuracy in Depicting Relationships, and Accuracy in Describing Attributes—guides the LVLM in ranking responses based on visual comprehension accuracy. This process involves forming preference pairs that distinguish between more and less accurate responses.
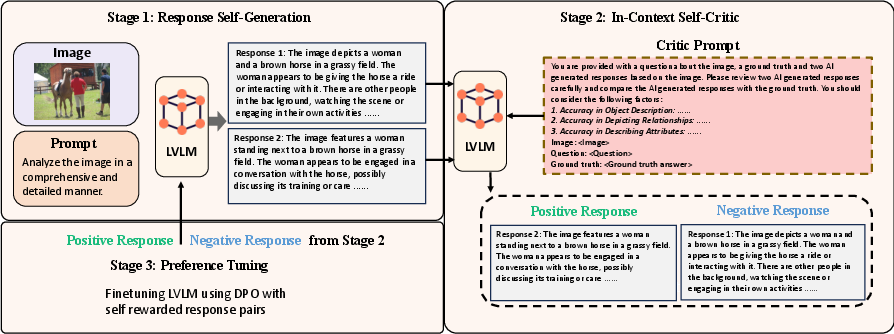
Figure 1: Flowchart of the SIMA framework. SIMA consists of three parts: Response Self-Generation, In-Context Self-Critic, and Preference Tuning.
Preference Tuning: The model is subsequently updated using Direct Preference Optimization (DPO), aligning the model more closely with the high-preference responses. This approach enhances the LVLM's performance without the distribution shift issues that arise from external data reliance.
Experimental Results
Empirical evaluations across 14 hallucination and comprehensive benchmarks demonstrate SIMA's efficacy. Notably, SIMA enhances the performance of LLAVA-1.5-7B with an average improvement of 7.5% over baseline models, demonstrating particularly strong results in reducing hallucinations and improving comprehension capabilities.
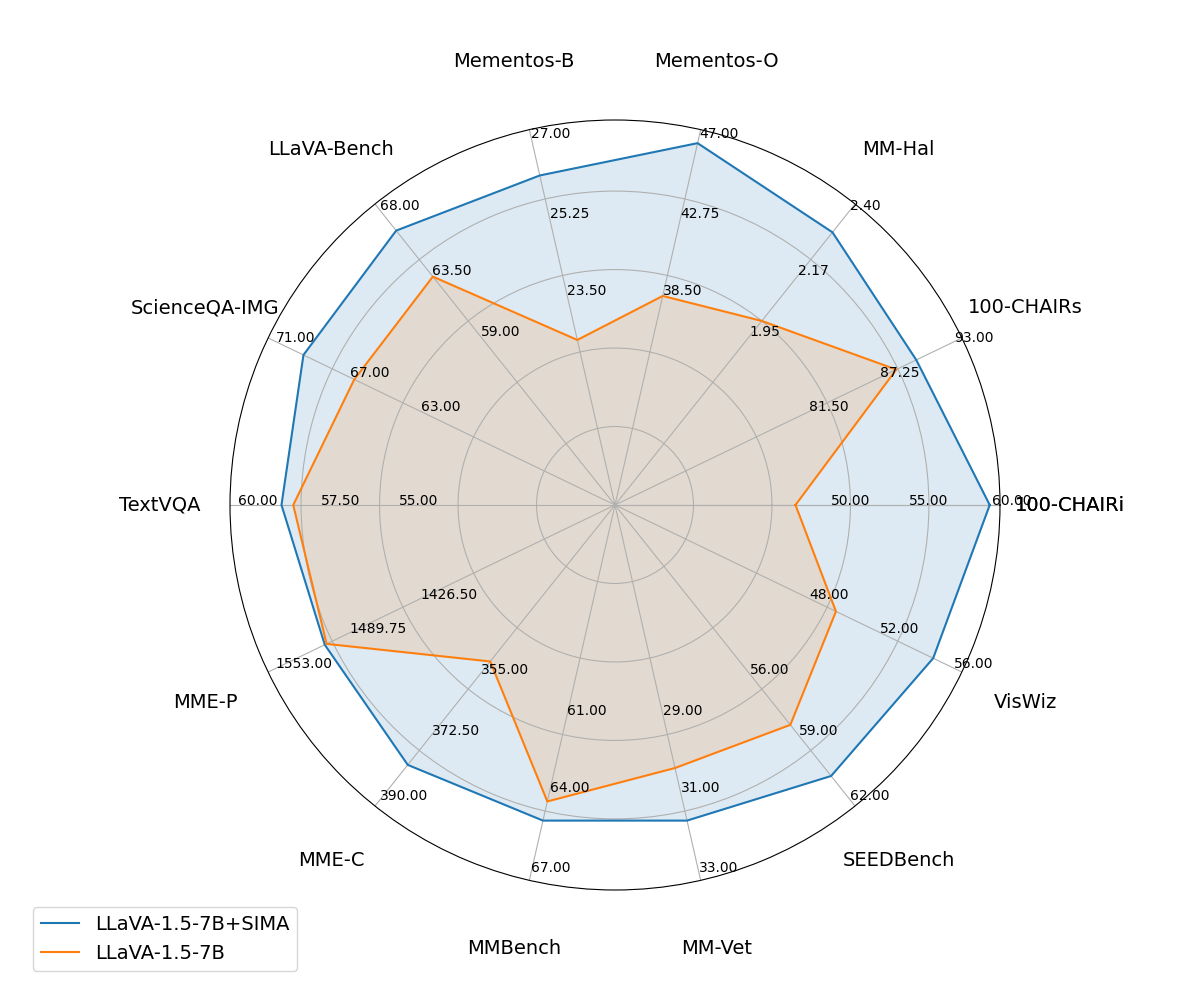
Figure 2: Performance comparison between our propose framework SIMA and LLaVA-1.5-7B on 14 hallucination and comprehensive benchmarks. After applying SIMA, LLAVA's performance is improved significantly across all benchmarks, with an average performance increase of 7.5\%.
Discussion
SIMA significantly mitigates hallucinations in LVLMs and enhances their ability to accurately interpret and respond to visual prompts. This improvement is largely attributed to the model's self-reliant mechanism for generating, evaluating, and refining responses, thus overcoming the inherent limitations of external dependency.

Figure 3: Examples to illustrate the effect of SIMA on LVLM. SIMA is presented to be less hallucinated compared with LLaVA.
Conclusion
The introduction of SIMA represents a substantial advancement in visual-language modality alignment within LVLMs. By circumventing the need for external models or data through self-improvement strategies, SIMA not only enhances alignment but also expands scalability and deployment feasibility. Future work could explore further refinement of the critic metrics and additional scalable self-assessment techniques to continue improving the robustness and accuracy of LVLMs. The approach opens avenues for developing more autonomous and adaptable AI systems capable of nuanced visual and linguistic comprehension.