Cooperative Backdoor Attack in Decentralized Reinforcement Learning with Theoretical Guarantee
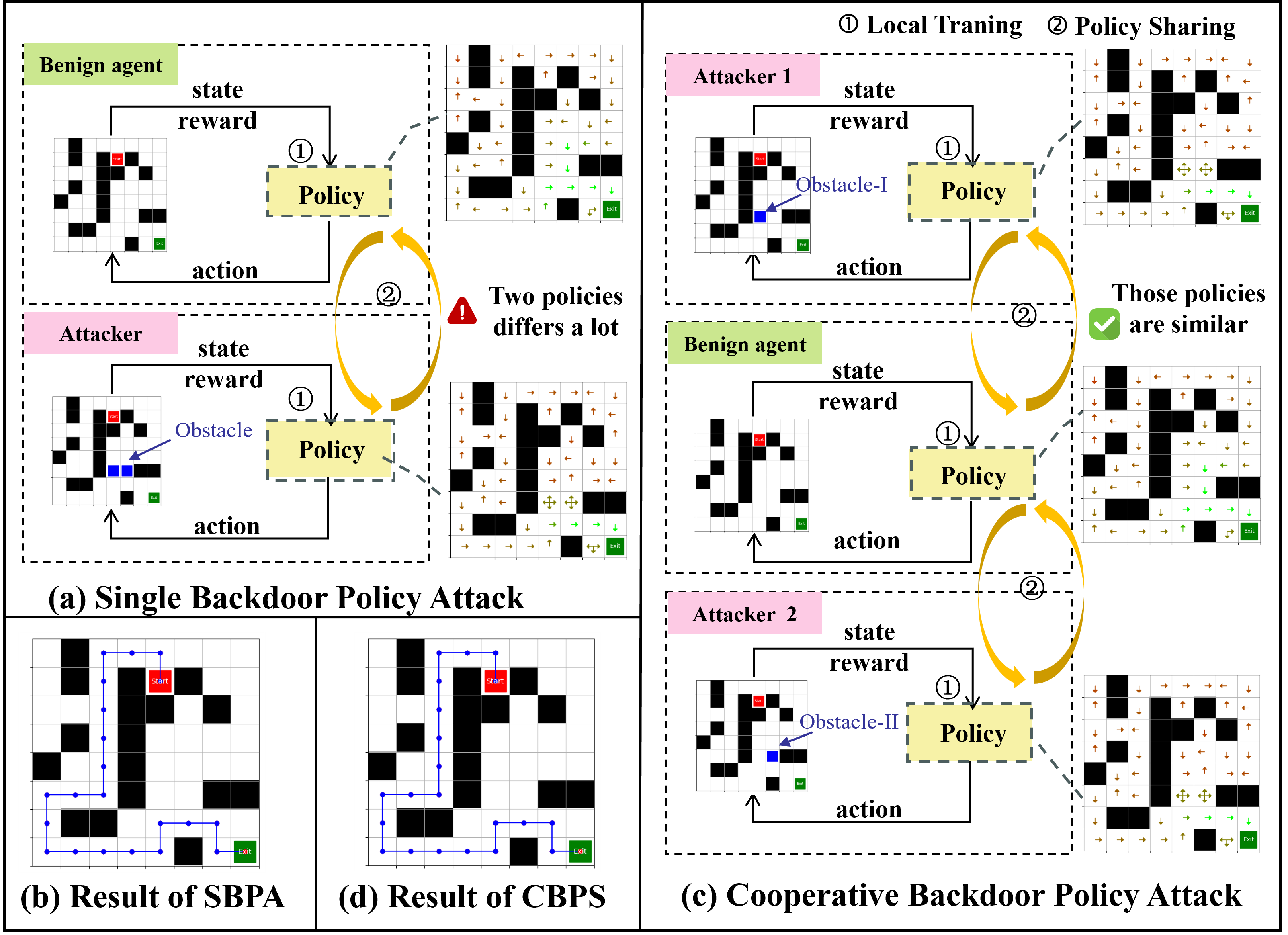
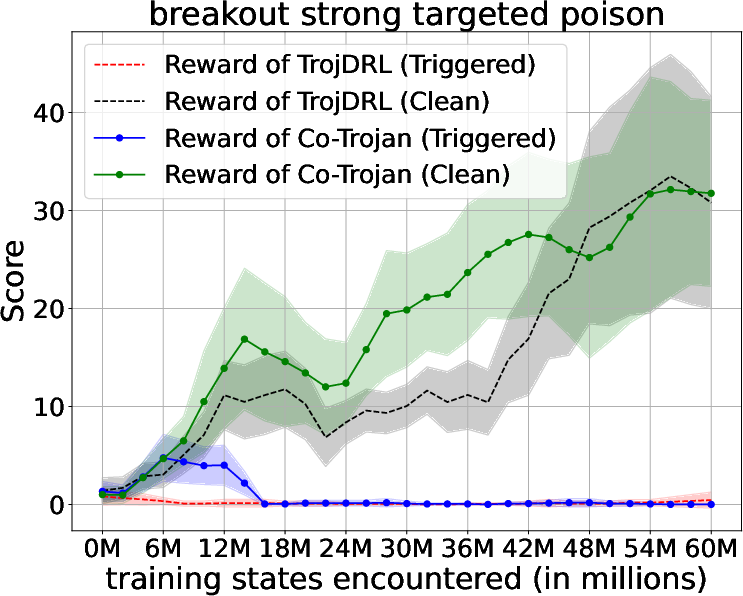
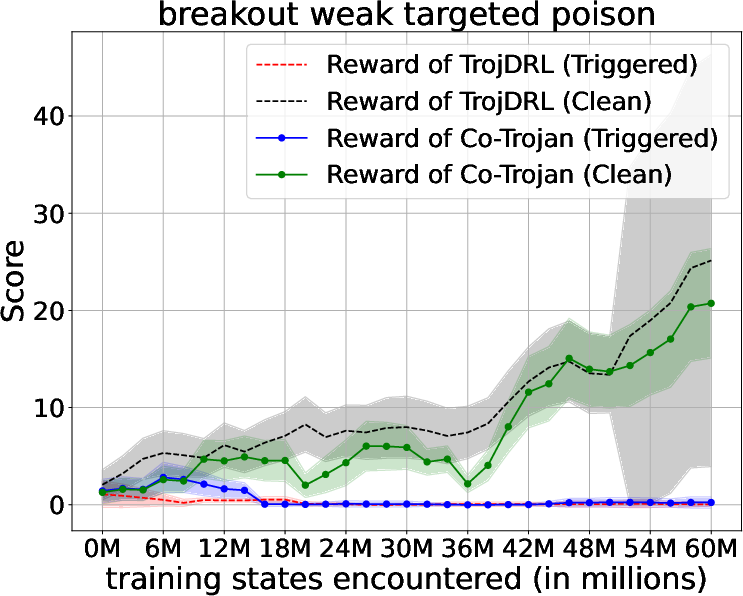
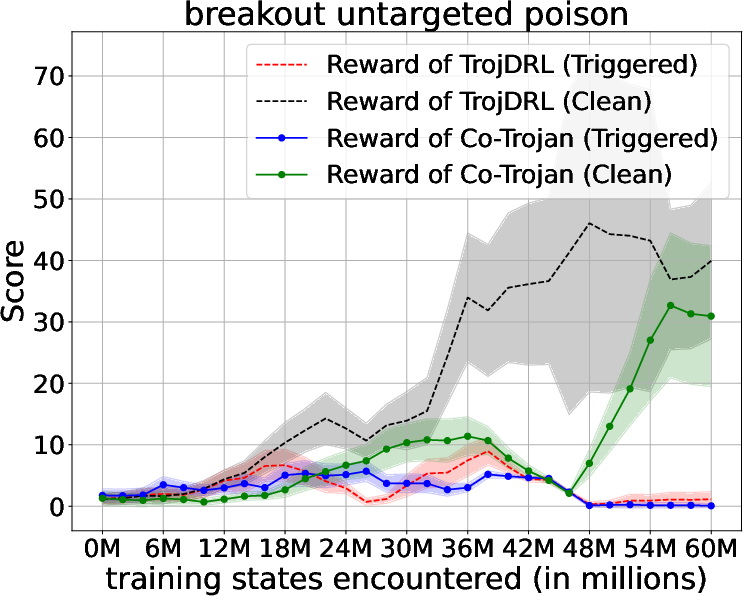
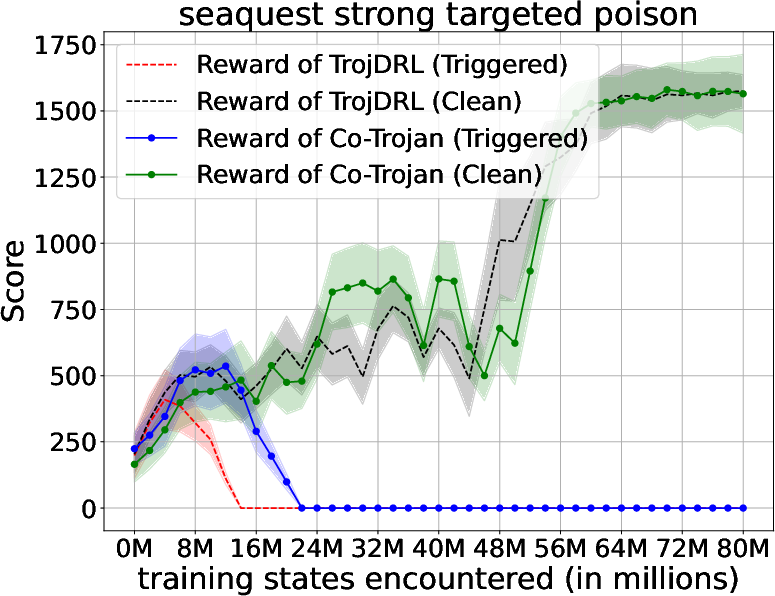
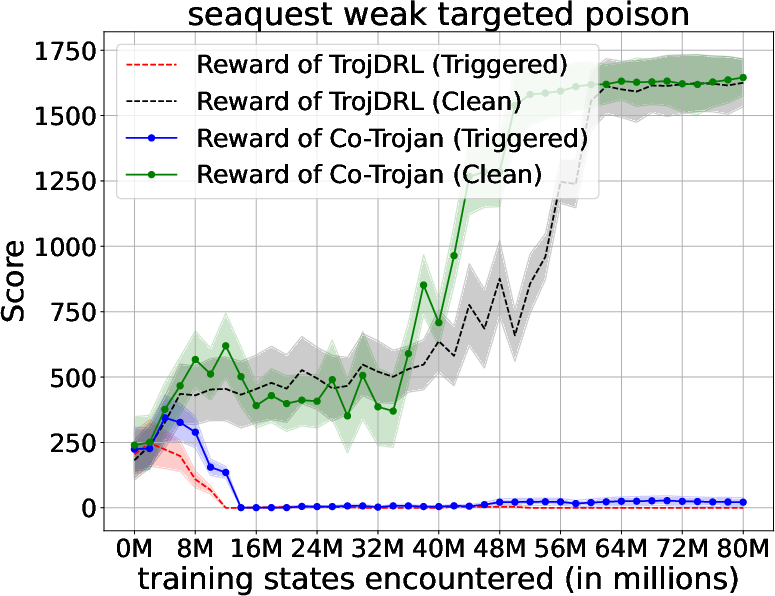
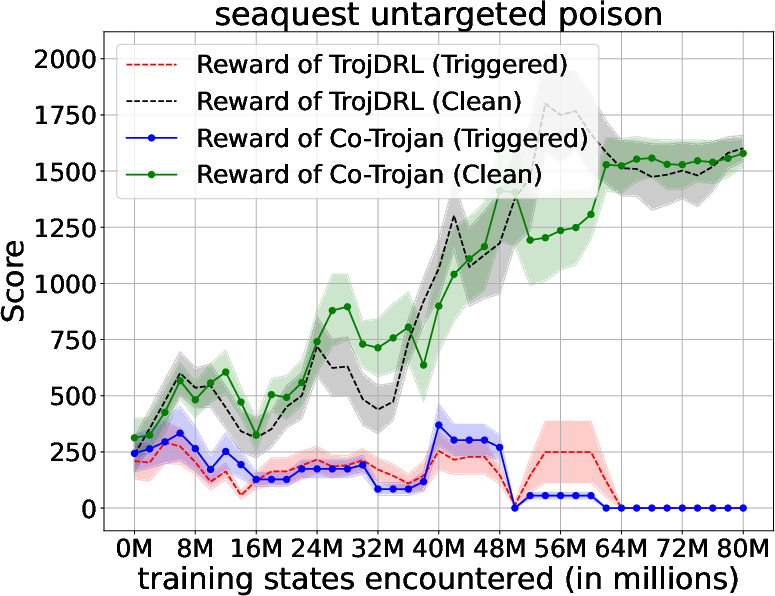
Abstract: The safety of decentralized reinforcement learning (RL) is a challenging problem since malicious agents can share their poisoned policies with benign agents. The paper investigates a cooperative backdoor attack in a decentralized reinforcement learning scenario. Differing from the existing methods that hide a whole backdoor attack behind their shared policies, our method decomposes the backdoor behavior into multiple components according to the state space of RL. Each malicious agent hides one component in its policy and shares its policy with the benign agents. When a benign agent learns all the poisoned policies, the backdoor attack is assembled in its policy. The theoretical proof is given to show that our cooperative method can successfully inject the backdoor into the RL policies of benign agents. Compared with the existing backdoor attacks, our cooperative method is more covert since the policy from each attacker only contains a component of the backdoor attack and is harder to detect. Extensive simulations are conducted based on Atari environments to demonstrate the efficiency and covertness of our method. To the best of our knowledge, this is the first paper presenting a provable cooperative backdoor attack in decentralized reinforcement learning.
- Deep reinforcement learning for cyber security. IEEE Transactions on Neural Networks and Learning Systems, 34(8):3779–3795, 2021.
- Reinforcement learning for iot security: A comprehensive survey. IEEE Internet of Things Journal, 8(11):8693–8706, 2020.
- Sample-efficient and safe deep reinforcement learning via reset deep ensemble agents. Advances in Neural Information Processing Systems, 36, 2024.
- Fedgame: A game-theoretic defense against backdoor attacks in federated learning. Advances in Neural Information Processing Systems, 36, 2024.
- Security analysis of safe and seldonian reinforcement learning algorithms. Advances in Neural Information Processing Systems, 33:8959–8970, 2020.
- Safe offline reinforcement learning with real-time budget constraints. In International Conference on Machine Learning, pages 21127–21152. PMLR, 2023.
- Safe reinforcement learning in constrained markov decision processes. In International Conference on Machine Learning, pages 9797–9806. PMLR, 2020.
- Trojdrl: Evaluation of backdoor attacks on deep reinforcement learning. 2020 57th ACM/IEEE Design Automation Conference (DAC), pages 1–6, 2020. URL https://api.semanticscholar.org/CorpusID:222297804.
- Backdoorl: Backdoor attack against competitive reinforcement learning. arXiv preprint arXiv:2105.00579, 2021.
- Baffle: Hiding backdoors in offline reinforcement learning datasets. In 2024 IEEE Symposium on Security and Privacy (SP), pages 218–218. IEEE Computer Society, 2024.
- Badrl: Sparse targeted backdoor attack against reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11687–11694, 2024.
- Yingqi Liu et al. Trojaning attack on neural networks. arXiv preprint arXiv:1702.05521, 2017.
- Blackbox attacks on reinforcement learning agents using approximated temporal information. In 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), pages 16–24. IEEE, 2020.
- Provable defense against backdoor policies in reinforcement learning. Advances in Neural Information Processing Systems, 35:14704–14714, 2022.
- Flame: Taming backdoors in federated learning. arXiv preprint arXiv:2102.05117, 2021.
- Auror: Defending against poisoning attacks in collaborative deep learning systems. Proceedings of the 32nd Annual Conference on Computer Security Applications, pages 508–519, 2016.
- Decentralized reinforcement learning of robot behaviors. Artificial Intelligence, 256:130–159, 2018.
- How to backdoor federated learning. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics, pages 2938–2948, 2020a.
- Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 37(3):50–60, 2020.
- Iba: Towards irreversible backdoor attacks in federated learning. Advances in Neural Information Processing Systems, 36, 2024.
- A3fl: Adversarially adaptive backdoor attacks to federated learning. Advances in Neural Information Processing Systems, 36, 2024a.
- Poisoning with cerberus: Stealthy and colluded backdoor attack against federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 9020–9028, 2023.
- Crfl: Certifiably robust federated learning against backdoor attacks. In International Conference on Machine Learning, pages 11372–11382. PMLR, 2021.
- Beyond traditional threats: A persistent backdoor attack on federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21359–21367, 2024.
- Attack of the tails: Yes, you really can backdoor federated learning. arXiv preprint arXiv:2007.05084, 2020.
- Dba: Distributed backdoor attacks against federated learning. arXiv preprint arXiv:1905.10447, 2019.
- Collaborative ai teaming in unknown environments via active goal deduction. arXiv preprint arXiv:2403.15341, 2024b.
- A distributed abstract mac layer for cooperative learning on internet of vehicles. IEEE Transactions on Intelligent Transportation Systems, 2024.
- Modeling other players with bayesian beliefs for games with incomplete information, 2024c.
- Pac: Assisted value factorization with counterfactual predictions in multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 35:15757–15769, 2022.
- How to backdoor federated learning. In International conference on artificial intelligence and statistics, pages 2938–2948. PMLR, 2020b.
- Value functions factorization with latent state information sharing in decentralized multi-agent policy gradients. IEEE Transactions on Emerging Topics in Computational Intelligence, 2023a.
- Mac-po: Multi-agent experience replay via collective priority optimization. arXiv preprint arXiv:2302.10418, 2023.
- Osteoporotic-like vertebral fracture with less than 20% height loss is associated with increased further vertebral fracture risk in older women: the mros and msos (hong kong) year-18 follow-up radiograph results. Quantitative Imaging in Medicine and Surgery, 13(2):1115, 2023.
- Coordinate-aligned multi-camera collaboration for active multi-object tracking. arXiv preprint arXiv:2202.10881, 2022.
- Implementing first-person shooter game ai in wild-scav with rule-enhanced deep reinforcement learning. In 2023 IEEE Conference on Games (CoG), pages 1–8. IEEE, 2023.
- A bayesian optimization framework for finding local optima in expensive multi-modal functions. arXiv preprint arXiv:2210.06635, 2022.
- Projection-optimal monotonic value function factorization in multi-agent reinforcement learning. In Proceedings of the 2024 International Conference on Autonomous Agents and Multiagent Systems, 2024.
- Real-time network intrusion detection via decision transformers. arXiv preprint arXiv:2312.07696, 2023.
- Double policy estimation for importance sampling in sequence modeling-based reinforcement learning. In NeurIPS 2023 Foundation Models for Decision Making Workshop, 2023b.
- Bringing fairness to actor-critic reinforcement learning for network utility optimization. In IEEE INFOCOM 2021-IEEE Conference on Computer Communications, pages 1–10. IEEE, 2021.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.