- The paper presents a reverse engineered adapter (RE-Adapter) that isolates instruction tuning weights to preserve model performance while integrating new domain knowledge.
- It introduces partial adaptation and low-rank LoRE-Adapters to enable efficient, resource-friendly fine-tuning without overfitting.
- Experimental results show improved performance in closed-book and retrieval-augmented QA tasks, maintaining instruction-following capabilities.
Reverse Engineered Adaptation of LLMs
Introduction
The paper "RE-Adapt: Reverse Engineered Adaptation of LLMs" presents a novel approach, RE-Adapt, designed for efficient fine-tuning of LLMs on new domains. The technique aims to preserve the instruction-following capabilities of an LLM while allowing the integration of new knowledge. By isolating the weights added through instruction tuning, the work efficiently aligns the pretrained base model with adapted knowledge through a Reverse Engineered Adapter (RE-Adapter). This method offers a robust pathway to fine-tuning which avoids the degradation of instruction-tuning, often seen in traditional approaches.
RE-Adapt Methodology
RE-Adapt is predicated upon the differentiation between an instruction-tuned model and its non-instruct counterpart. The central hypothesis is that the difference in weights – acquired through instruction tuning – represents a viable adapter. This RE-Adapter can be reapplied to the base model after domain-specific fine-tuning, thereby preserving earlier instruction-following abilities.
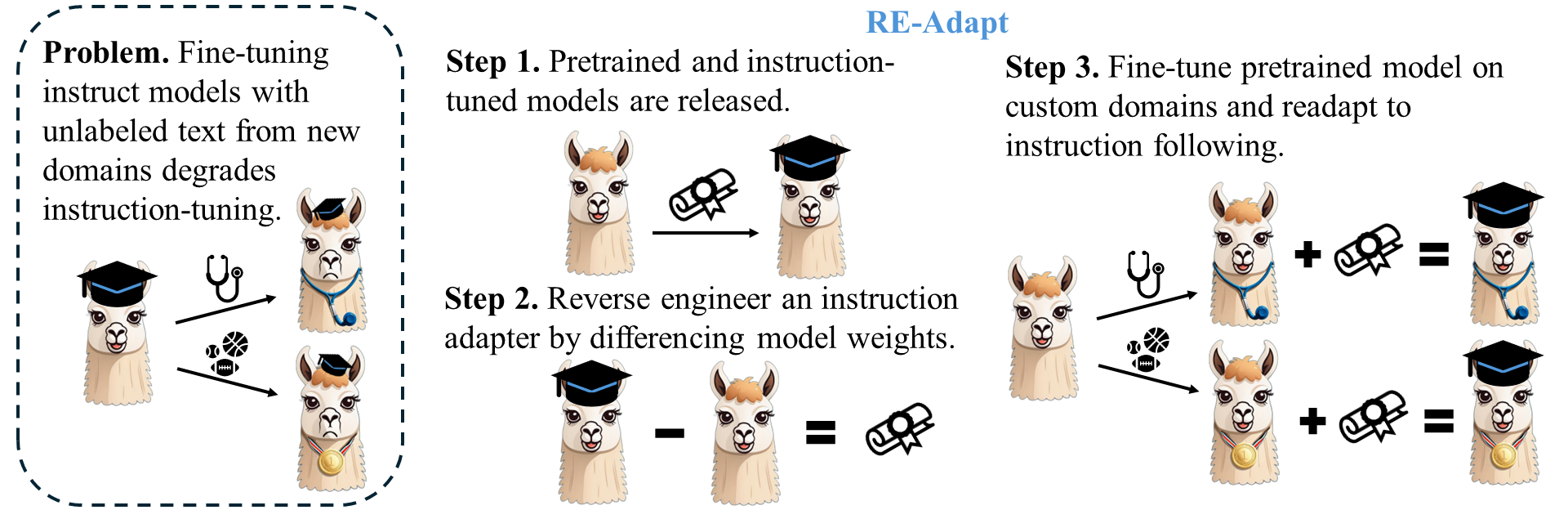
Figure 1: In RE-Adapt, an instruction adapter is isolated by differencing weights between instruct and pretrained versions of a model.
A key feature of this approach is the introduction of a scaling method termed partial adaptation, which modulates the strength of adapters applied during inference. This control over adaptation strength mitigates overfitting and preserves general performance.
Low-Rank Extension: LoRE-Adapters
The LoRE-Adapters are a low-rank variant of RE-Adapters, developed to further optimize parameter efficiency. By leveraging the low-rank approximation properties inherent to LLMs, LoRE-Adapters maintain or improve performance while significantly reducing memory usage. This is achieved using truncated SVD to capture essential variance elements across adapter parameters, indicating the applicability of LoRE-Adapt in resource-constrained environments.
Experimental Findings
In experiments, RE-Adapt demonstrated superior ability in knowledge incorporation for LLMs. This was evaluated using question-answering tasks both in closed-book and retrieval-augmented settings:
Discussion and Implications
RE-Adapt addresses critical challenges in maintaining both knowledge acquisition and instruction-following abilities within LLMs. This underscores its potential utility in scenarios requiring continuous learning and adaptation without compromising pre-existing model aptitudes. Moreover, the approach suggests possible advancements in parameter efficiency and memory usage through its low-rank adaptations.
The broader implications of this work lie in its potential to enable more flexible, resource-efficient model tuning strategies that cater to dynamic task demands while sustaining foundational capabilities. This lays groundwork for future explorations into balancing competing adaptation priorities in LLMs, potentially influencing frameworks beyond the immediate scope discussed.
Conclusion
RE-Adapt emerges as an authoritative method for fine-tuning LLMs, championing both preservation of instruction-following performance and integration of novel domain knowledge. It represents a meaningful enhancement over existing fine-tuning paradigms, particularly for its ability to utilize unlabeled data without the common pitfalls of traditional tuning methods. Future research directions may explore further scaling of adaptation strengths and more diverse empirical validations across tasks beyond question answering.
