- The paper proposes a Reinforced Advantage feedback mechanism to refine LLM-planned actions using critic-evaluated advantage scores.
- The method employs joint and local advantage functions along with ReAd-S and ReAd-J prompting schemes to enhance planning efficiency.
- Experimental results on DV-RoCoBench and Overcooked-AI demonstrate improved success rates and fewer environment interactions compared to state-of-the-art methods.
Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration
The paper "Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration" introduces a novel framework for multi-agent collaboration using Reinforced Advantage feedback (ReAd) to enhance the reasoning abilities of LLMs for embodied tasks. This framework improves the efficiency of LLM-grounded planning by employing advantage functions from reinforcement learning as feedback mechanisms for plan refinement, significantly reducing interaction rounds with the environment.
Introduction
The integration of LLMs in multi-agent collaboration poses challenges due to the complexity of the physical world and the necessity for effective agent communication. Existing approaches that rely heavily on physical verification or self-reflection result in inefficient querying and interaction cycles with LLMs. The paper addresses these inefficiencies by proposing a system where the LLM uses advantage feedback to refine action plans based on the critic-evaluated scores, effectively reducing the number of necessary interactions with the environment.
The framework utilizes a critic network to evaluate the advantage of actions proposed by the LLM planner. By focusing on plans that maximize advantage scores, the LLM is guided towards actions that are likely to achieve the task objectives efficiently. This is in contrast to methods like RoCo, which require extensive physical feedback loops, as depicted in Figure 1.
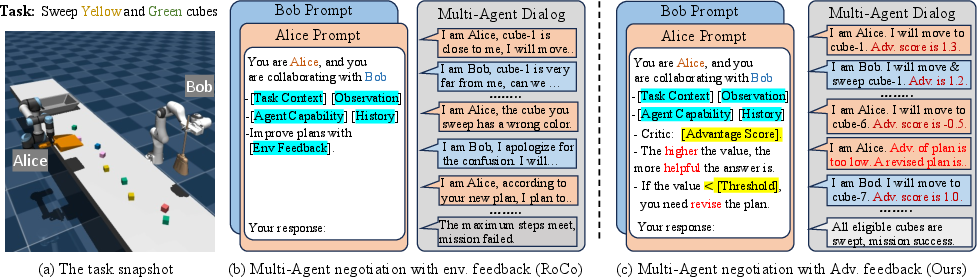
Figure 1: An illustration of the negotiation process of RoCo and our method. RoCo interacts with the environment for each plan and takes the environment's feedback as prompts. In contrast, our method takes the advantage function (Adv.) evaluated by a critic as feedback, and revises the plan if the advantage value is lower than the threshold, which significantly reduces the interaction rounds to the environment.
Methodology
Learning of Advantage Functions
The framework proposes two forms of advantage function learning: joint advantage function and local advantage function. The joint advantage function evaluates the entire action set's contribution to the task, while the local advantage function considers the contribution of individual actions. The critic regresses sequences of LLM-planned data to estimate these advantage functions.
The joint advantage function can be efficiently derived using value functions, simplifying the need for direct environmental interaction:
Aπ(s,a)=Qπ(s,a)−γ1Qπ(s,w)
Prompting by Reinforced Advantage Feedback
The framework implements two prompting schemes: ReAd-S and ReAd-J. ReAd-S offers sequential individual plan refinement with local advantages, while ReAd-J provides joint plan refinement with joint advantages. During each timestep, the LLM planner is prompted to maximize advantage scores, ensuring higher success rates and fewer environmental interactions.
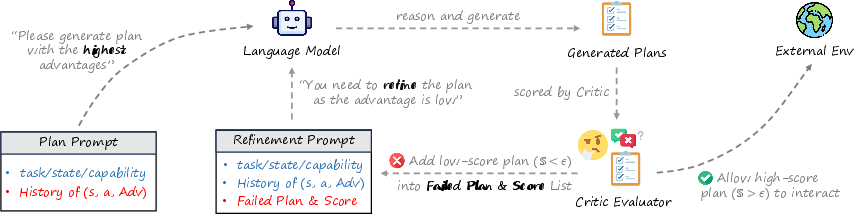
Figure 2: An overview of prompting and refinement. For each timestep t, the LLM planner is given the history, which contains states, actions, and advantages, and is prompted to generate a plan with the highest advantage. The pre-trained critic is used to evaluate the score of the generated action SReAd(ati).
Experiments
The experiments conducted on DV-RoCoBench and Overcooked-AI showcase the effectiveness of ReAd compared to other state-of-the-art methods like RoCo and traditional self-reflective approaches. The results demonstrate superior success rates and lower interaction steps, affirming ReAd's efficiency in grounding LLMs.
Notably, ReAd maintains robustness in scenarios with environmental disturbances, successfully adapting plans without full historical information, as illustrated in:

Figure 3: Screenshots of ReAd-S completing the recipe3 task in robustness test. After the environment is reset, our method will be affected by the historical dialogue information in a short period. After being prompted by the advantage function re-evaluated in the new state, our method can make a rapid re-plan based on the new state.
Conclusion
The introduction of Reinforced Advantage as a feedback mechanism for LLM-grounded planning in multi-agent collaboration presents a significant advancement in reducing inefficiencies associated with traditional methods reliant on physical feedback. This framework showcases potential for enhanced real-world application in complex embodied tasks, with future considerations for extending its methodologies to support multi-objective and safe planning scenarios.