Reindex-Then-Adapt: Improving Large Language Models for Conversational Recommendation
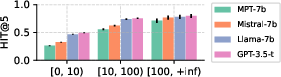
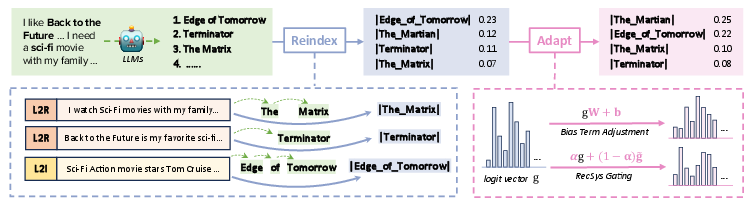
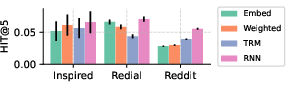
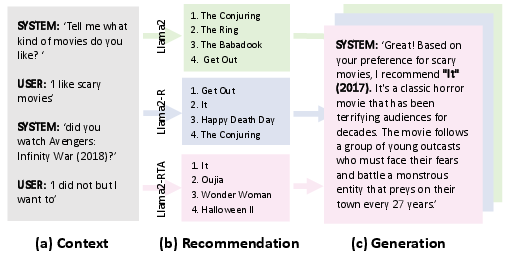
Abstract: LLMs are revolutionizing conversational recommender systems by adeptly indexing item content, understanding complex conversational contexts, and generating relevant item titles. However, controlling the distribution of recommended items remains a challenge. This leads to suboptimal performance due to the failure to capture rapidly changing data distributions, such as item popularity, on targeted conversational recommendation platforms. In conversational recommendation, LLMs recommend items by generating the titles (as multiple tokens) autoregressively, making it difficult to obtain and control the recommendations over all items. Thus, we propose a Reindex-Then-Adapt (RTA) framework, which converts multi-token item titles into single tokens within LLMs, and then adjusts the probability distributions over these single-token item titles accordingly. The RTA framework marries the benefits of both LLMs and traditional recommender systems (RecSys): understanding complex queries as LLMs do; while efficiently controlling the recommended item distributions in conversational recommendations as traditional RecSys do. Our framework demonstrates improved accuracy metrics across three different conversational recommendation datasets and two adaptation settings
- LLM Based Generation of Item-Description for Recommendation System. In Proceedings of the 17th ACM Conference on Recommender Systems. 1204–1207.
- Beyond Labels: Leveraging Deep Learning and LLMs for Content Metadata. In Proceedings of the 17th ACM Conference on Recommender Systems. 1–1.
- Dbpedia: A nucleus for a web of open data. In The Semantic Web: 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007+ ASWC 2007, Busan, Korea, November 11-15, 2007. Proceedings. Springer, 722–735.
- Tallrec: An effective and efficient tuning framework to align large language model with recommendation. arXiv preprint arXiv:2305.00447 (2023).
- Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 1877–1901.
- Li Chen and Pearl Pu. 2012. Critiquing-based recommenders: survey and emerging trends. User Modeling and User-Adapted Interaction 22 (2012), 125–150.
- Towards Knowledge-Based Recommender Dialog System. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 1803–1813.
- Understanding Differential Search Index for Text Retrieval. arXiv preprint arXiv:2305.02073 (2023).
- On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. 103–111.
- Evaluation of bert and albert sentence embedding performance on downstream nlp tasks. In 2020 25th International conference on pattern recognition (ICPR). IEEE, 5482–5487.
- PaLM: Scaling Language Modeling with Pathways. ArXiv abs/2204.02311 (2022).
- Towards conversational recommender systems. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 815–824.
- Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014).
- M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems. arXiv:2205.08084 [cs.IR]
- Uncovering ChatGPT’s Capabilities in Recommender Systems. arXiv preprint arXiv:2305.02182 (2023).
- A Large Language Model Enhanced Conversational Recommender System. arXiv preprint arXiv:2308.06212 (2023).
- Leveraging Large Language Models in Conversational Recommender Systems. arXiv preprint arXiv:2305.07961 (2023).
- Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). In RecSys ’22: Sixteenth ACM Conference on Recommender Systems, Seattle, WA, USA, September 18 - 23, 2022, Jennifer Golbeck, F. Maxwell Harper, Vanessa Murdock, Michael D. Ekstrand, Bracha Shapira, Justin Basilico, Keld T. Lundgaard, and Even Oldridge (Eds.). ACM, 299–315.
- Improving the gating mechanism of recurrent neural networks. In International Conference on Machine Learning. PMLR, 3800–3809.
- Leveraging Large Language Models for Sequential Recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems. 1096–1102.
- INSPIRED: Toward Sociable Recommendation Dialog Systems. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 8142–8152.
- Large language models as zero-shot conversational recommenders. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 720–730.
- Bundle MCR: Towards Conversational Bundle Recommendation. In Proceedings of the 16th ACM Conference on Recommender Systems. 288–298.
- Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation 9, 8 (1997), 1735–1780.
- Large language models are zero-shot rankers for recommender systems. arXiv preprint arXiv:2305.08845 (2023).
- Mistral 7B. arXiv preprint arXiv:2310.06825 (2023).
- Fism: factored item similarity models for top-n recommender systems. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 659–667.
- Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
- Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. arXiv preprint arXiv:2305.06474 (2023).
- Scaling Laws for Neural Language Models. ArXiv abs/2001.08361 (2020).
- Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, Vol. 1. 2.
- Estimation-action-reflection: Towards deep interaction between conversational and recommender systems. In Proceedings of the 13th International Conference on Web Search and Data Mining. 304–312.
- Interactive path reasoning on graph for conversational recommendation. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2073–2083.
- GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation. arXiv:2304.03879 [cs.IR]
- Towards deep conversational recommendations. Advances in neural information processing systems 31 (2018).
- Self-Supervised Bot Play for Conversational Recommendation with Justifications. arXiv preprint arXiv:2112.05197 (2021).
- User-centric conversational recommendation with multi-aspect user modeling. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 223–233.
- Competition-level code generation with AlphaCode. Science 378 (2022), 1092 – 1097.
- Hugo Liu and Push Singh. 2004. ConceptNet—a practical commonsense reasoning tool-kit. BT technology journal 22, 4 (2004), 211–226.
- Is ChatGPT a Good Recommender? A Preliminary Study. arXiv:2304.10149 [cs.IR]
- RevCore: Review-Augmented Conversational Recommendation. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 1161–1173.
- Large Language Model Augmented Narrative Driven Recommendations. arXiv preprint arXiv:2306.02250 (2023).
- Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018).
- Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992.
- Large Language Models are Competitive Near Cold-start Recommenders for Language-and Item-based Preferences. In Proceedings of the 17th ACM Conference on Recommender Systems. 890–896.
- Chatgpt: Optimizing language models for dialogue. OpenAI (2022).
- Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th international conference on World Wide Web. 111–112.
- One embedder, any task: Instruction-finetuned text embeddings. arXiv preprint arXiv:2212.09741 (2022).
- Transformer memory as a differentiable search index. Advances in Neural Information Processing Systems 35 (2022), 21831–21843.
- MosaicML NLP Team. 2023. Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs. www.mosaicml.com/blog/mpt-7b Accessed: 2023-05-05.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Attention is all you need. In Advances in neural information processing systems. 5998–6008.
- Generative Recommendation: Towards Next-generation Recommender Paradigm. arXiv:2304.03516 [cs.IR]
- Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models. arXiv preprint arXiv:2305.13112 (2023).
- Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1929–1937.
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 24824–24837.
- Deep language-based critiquing for recommender systems. In Proceedings of the 13th ACM Conference on Recommender Systems. 137–145.
- LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking. arXiv preprint arXiv:2311.02089 (2023).
- DIALOGPT: Large-Scale Generative Pre-training for Conversational Response Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 270–278.
- Multiple Choice Questions based Multi-Interest Policy Learning for Conversational Recommendation. In Proceedings of the ACM Web Conference 2022. 2153–2162.
- Calibrate before use: Improving few-shot performance of language models. In International Conference on Machine Learning. PMLR, 12697–12706.
- CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X. arXiv:2303.17568 [cs.LG]
- Improving conversational recommender systems via knowledge graph based semantic fusion. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 1006–1014.
- Improving conversational recommender systems via transformer-based sequential modelling. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2319–2324.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

