Increasing the LLM Accuracy for Question Answering: Ontologies to the Rescue!
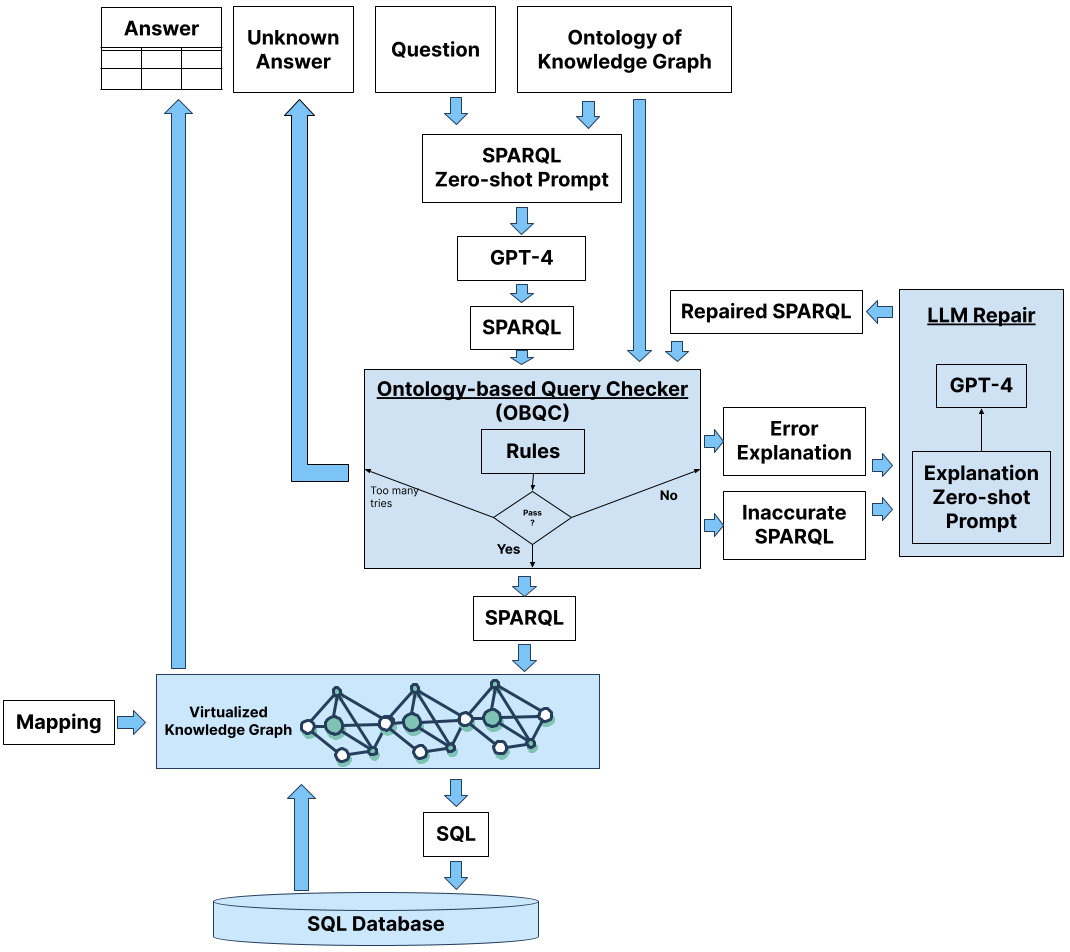
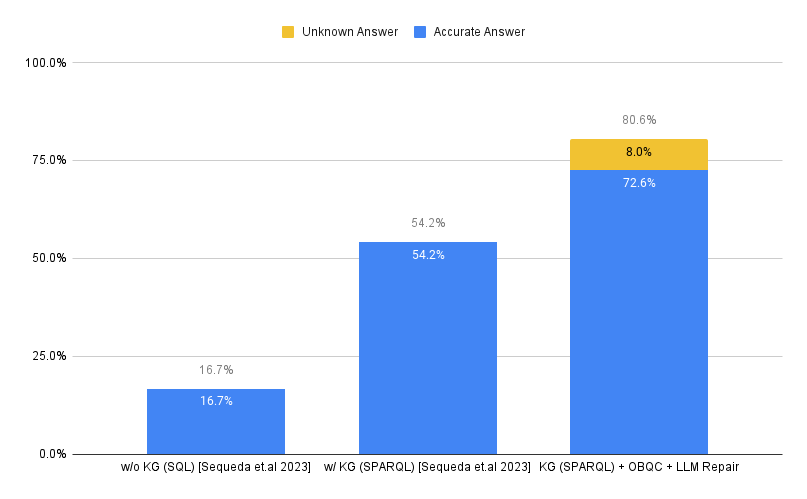
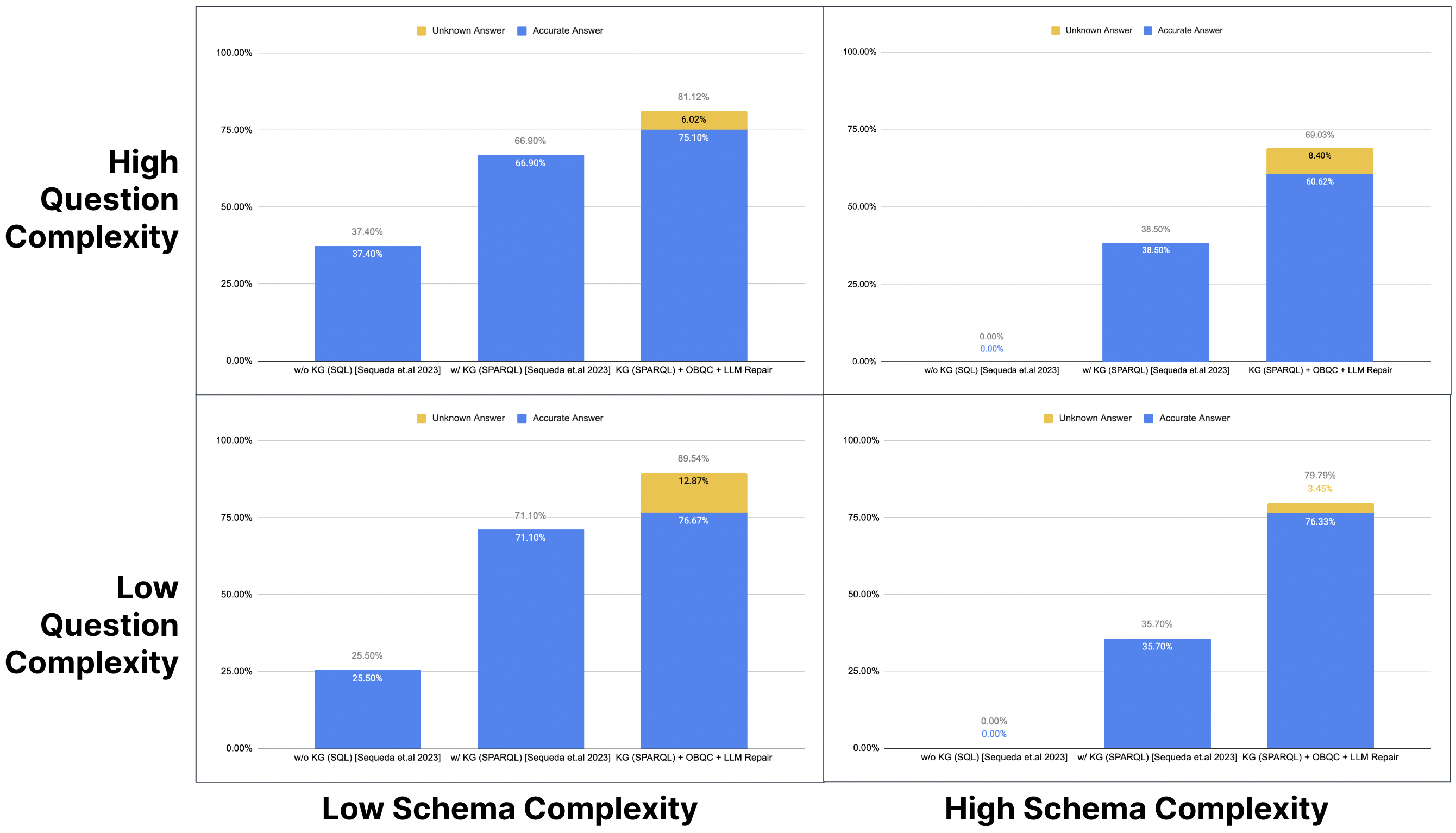
Abstract: There is increasing evidence that question-answering (QA) systems with LLMs, which employ a knowledge graph/semantic representation of an enterprise SQL database (i.e. Text-to-SPARQL), achieve higher accuracy compared to systems that answer questions directly on SQL databases (i.e. Text-to-SQL). Our previous benchmark research showed that by using a knowledge graph, the accuracy improved from 16% to 54%. The question remains: how can we further improve the accuracy and reduce the error rate? Building on the observations of our previous research where the inaccurate LLM-generated SPARQL queries followed incorrect paths, we present an approach that consists of 1) Ontology-based Query Check (OBQC): detects errors by leveraging the ontology of the knowledge graph to check if the LLM-generated SPARQL query matches the semantic of ontology and 2) LLM Repair: use the error explanations with an LLM to repair the SPARQL query. Using the chat with the data benchmark, our primary finding is that our approach increases the overall accuracy to 72% including an additional 8% of "I don't know" unknown results. Thus, the overall error rate is 20%. These results provide further evidence that investing knowledge graphs, namely the ontology, provides higher accuracy for LLM powered question answering systems.
- Repair checking in inconsistent databases: algorithms and complexity. In Proceedings of the 12th International Conference on Database Theory (New York, NY, USA, 2009), ICDT ’09, Association for Computing Machinery, p. 31–41.
- Semantic Web for the Working Ontologist: Effective Modeling for Linked Data, RDFS, and OWL, 3 ed., vol. 33. Association for Computing Machinery, New York, NY, USA, 2020.
- Repairagent: An autonomous, llm-based agent for program repair, 2024.
- Expanding the scope of the ATIS task: The ATIS-3 corpus. Proceedings of the workshop on Human Language Technology (1994), 43–48.
- Automated program repair. Commun. ACM 62, 12 (nov 2019), 56–65.
- Baseball: An automatic question-answerer. In Papers Presented at the May 9-11, 1961, Western Joint IRE-AIEE-ACM Computer Conference (New York, NY, USA, 1961), IRE-AIEE-ACM ’61 (Western), Association for Computing Machinery, p. 219–224.
- The use of theorem-proving techniques in question-answering systems. In Proceedings of the 1968 23rd ACM National Conference (New York, NY, USA, 1968), ACM ’68, Association for Computing Machinery, p. 169–181.
- Developing a natural language interface to complex data. ACM Trans. Database Syst. 3, 2 (jun 1978), 105–147.
- Knowledge Graphs. Synthesis Lectures on Data, Semantics, and Knowledge. Morgan & Claypool Publishers, 2021.
- Knowledge graphs. ACM Comput. Surv. 54, 4 (2022), 71:1–71:37.
- Inferfix: End-to-end program repair with llms. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (New York, NY, USA, 2023), ESEC/FSE 2023, Association for Computing Machinery, p. 1646–1656.
- A benchmark to understand the role of knowledge graphs on large language model’s accuracy for question answering on enterprise sql databases, 2023.
- Automated construction of database interfaces: Intergrating statistical and relational learning for semantic parsing. In 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora (2000), pp. 133–141.
- Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (2018), pp. 3911–3921.
- Woods, W. A. Transition network grammars for natural language analysis. Commun. ACM 13, 10 (oct 1970), 591–606.
- Corrective retrieval augmented generation, 2024.
- Learning to parse database queries using inductive logic programming. In Proceedings of the Thirteenth National Conference on Artificial Intelligence - Volume 2 (1996), pp. 1050–1055.
- A survey of learning-based automated program repair. ACM Trans. Softw. Eng. Methodol. 33, 2 (dec 2023).
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.