Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
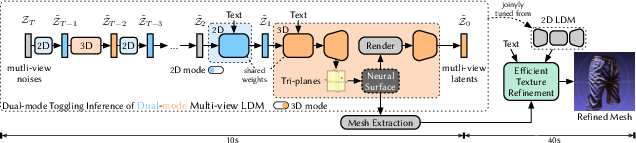
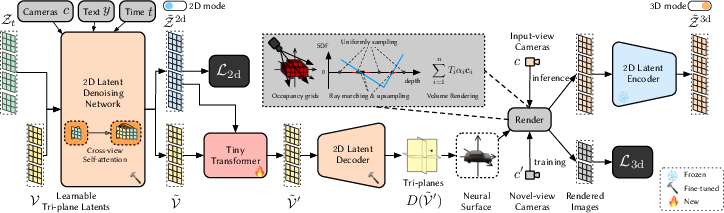
Abstract: We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io
- Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- 4d-fy: Text-to-4d generation using hybrid score distillation sampling. arXiv preprint arXiv:2311.17984, 2023.
- pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5799–5809, 2021.
- Efficient geometry-aware 3d generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16123–16133, 2022.
- Tensorf: Tensorial radiance fields. In European Conference on Computer Vision, pp. 333–350. Springer, 2022.
- Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13142–13153, 2023.
- Gram: Generative radiance manifolds for 3d-aware image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10673–10683, 2022.
- Generative adversarial networks. COMMUNICATIONS OF THE ACM, 63(11), 2020.
- Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- Stylenerf: A style-based 3d-aware generator for high-resolution image synthesis. arXiv preprint arXiv:2110.08985, 2021.
- Streetsurf: Extending multi-view implicit surface reconstruction to street views. arXiv preprint arXiv:2306.04988, 2023.
- 3dgen: Triplane latent diffusion for textured mesh generation. arXiv preprint arXiv:2303.05371, 2023.
- Towards a unified view of parameter-efficient transfer learning. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=0RDcd5Axok.
- Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400, 2023.
- LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Zero-shot text-guided object generation with dream fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 867–876, 2022.
- Shap-e: Generating conditional 3d implicit functions. arXiv preprint arXiv:2305.02463, 2023.
- Progressive growing of GANs for improved quality, stability, and variation. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=Hk99zCeAb.
- A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4401–4410, 2019.
- Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8110–8119, 2020.
- Alias-free generative adversarial networks. In Proc. NeurIPS, 2021.
- Noise-free score distillation. arXiv preprint arXiv:2310.17590, 2023.
- 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), July 2023.
- Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), San Diega, CA, USA, 2015.
- Auto-encoding variational bayes. In 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 2014.
- Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics, 39(6), 2020.
- Magic3d: High-resolution text-to-3d content creation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 300–309, 2023.
- Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. arXiv preprint arXiv:2312.16256, 2023.
- Neural sparse voxel fields. Advances in Neural Information Processing Systems, 33:15651–15663, 2020.
- Zero-1-to-3: Zero-shot one image to 3d object. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9298–9309, 2023a.
- P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 61–68, Dublin, Ireland, May 2022. URL https://aclanthology.org/2022.acl-short.8.
- Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453, 2023b.
- Unidream: Unifying diffusion priors for relightable text-to-3d generation, 2023c.
- Wonder3d: Single image to 3d using cross-domain diffusion. arXiv preprint arXiv:2310.15008, 2023.
- Scalable 3d captioning with pretrained models. arXiv preprint arXiv:2306.07279, 2023.
- Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
- Point-e: A system for generating 3d point clouds from complex prompts. arXiv preprint arXiv:2212.08751, 2022.
- Stylesdf: High-resolution 3d-consistent image and geometry generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13503–13513, 2022.
- Benchmark for compositional text-to-image synthesis. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 2021.
- Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4195–4205, 2023.
- Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10901–10911, 2021.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022.
- U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. 234–241. Springer, 2015.
- Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022.
- Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Graf: Generative radiance fields for 3d-aware image synthesis. Advances in Neural Information Processing Systems, 33:20154–20166, 2020.
- Mvdream: Multi-view diffusion for 3d generation. arXiv:2308.16512, 2023.
- 3d neural field generation using triplane diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20875–20886, 2023.
- Light field networks: Neural scene representations with single-evaluation rendering. Advances in Neural Information Processing Systems, 34:19313–19325, 2021.
- Denoising diffusion implicit models. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021.
- Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. arXiv preprint arXiv:2309.16653, 2023a.
- Volumediffusion: Flexible text-to-3d generation with efficient volumetric encoder, 2023b.
- Textmesh: Generation of realistic 3d meshes from text prompts. arXiv preprint arXiv:2304.12439, 2023.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12619–12629, 2023a.
- Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In 35th Conference on Neural Information Processing Systems, pp. 27171–27183. Curran Assoicates, Inc., 2021.
- Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. arXiv preprint arXiv:2305.16213, 2023b.
- Hd-fusion: Detailed text-to-3d generation leveraging multiple noise estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 3202–3211, 2024.
- Group normalization. In Proceedings of the European conference on computer vision (ECCV), pp. 3–19, 2018.
- Gram-hd: 3d-consistent image generation at high resolution with generative radiance manifolds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2195–2205, 2023.
- Dmv3d: Denoising multi-view diffusion using 3d large reconstruction model. arXiv preprint arXiv:2311.09217, 2023.
- Volume rendering of neural implicit surfaces. Advances in Neural Information Processing Systems, 34:4805–4815, 2021.
- Mvimgnet: A large-scale dataset of multi-view images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9150–9161, 2023.
- The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 586–595, 2018.
- Sparse3d: Distilling multiview-consistent diffusion for object reconstruction from sparse views. arXiv preprint arXiv:2308.14078, 2023.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

