Chameleon: Mixed-Modal Early-Fusion Foundation Models
Abstract: We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training approach from inception, an alignment recipe, and an architectural parameterization tailored for the early-fusion, token-based, mixed-modal setting. The models are evaluated on a comprehensive range of tasks, including visual question answering, image captioning, text generation, image generation, and long-form mixed modal generation. Chameleon demonstrates broad and general capabilities, including state-of-the-art performance in image captioning tasks, outperforms Llama-2 in text-only tasks while being competitive with models such as Mixtral 8x7B and Gemini-Pro, and performs non-trivial image generation, all in a single model. It also matches or exceeds the performance of much larger models, including Gemini Pro and GPT-4V, according to human judgments on a new long-form mixed-modal generation evaluation, where either the prompt or outputs contain mixed sequences of both images and text. Chameleon marks a significant step forward in a unified modeling of full multimodal documents.
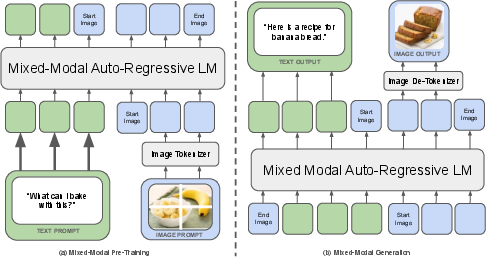
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Image tokenizer limitations: the tokenizer struggles with text-heavy images (OCR), but the paper does not quantify how this degrades downstream tasks (e.g., chart QA, document VQA) or explore higher-resolution/token-count tokenizers to mitigate it.
- Fixed image resolution/token budget: using 512×512 images with 1024 tokens constrains fidelity and document length (given a 4k token context). The trade-offs and methods to extend context or compress image tokens for more images per document are not evaluated.
- Tokenizer design space: effects of codebook size, token count per image, multi-scale tokenization, or latent diffusion tokenizers on mixed-modal generation/reasoning are not ablated.
- Lack of OCR/vision-text benchmarks: evaluations omit OCR/document understanding tasks, making the model’s limits on text-in-image handling unmeasured.
- Early-fusion vs. late-fusion baselines: there is no controlled, head-to-head comparison with strong late-fusion/adapter-based models to isolate the gains of early fusion on the same data and compute.
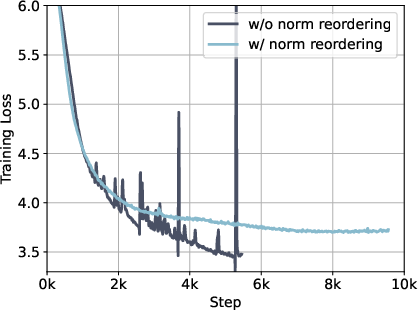
- Contribution disentanglement: performance gains are not decomposed across factors (QK-Norm, z-loss, norm re-ordering, data mixture, curriculum, SFT balancing), limiting causal insight.
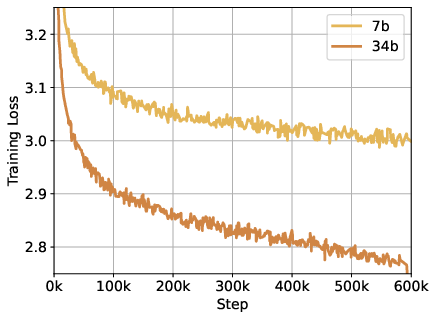
- Scaling laws for mixed-modal training: no systematic study of how performance scales with parameters, tokens, or modality proportions; optimal image:text:code ratios and curriculum scheduling remain unknown.
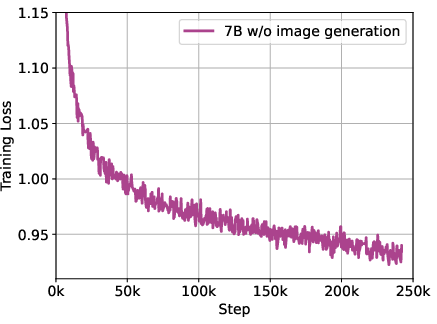
- Data mixture sensitivity: the two-stage curriculum and 50% image-before-text rotation are not ablated; “higher quality” additions are not precisely defined or analyzed for impact.
- Data transparency and contamination: dataset composition, deduplication, and test-set leakage defenses are insufficiently documented; potential benchmark contamination is unquantified.
- Multilingual capability: tokenizer and training mixture likely include multiple languages, but cross-lingual multimodal performance and trade-offs are not evaluated.
- Code modality evaluation: code is included in pretraining/SFT, but there is no systematic evaluation on code benchmarks or analysis of interactions between code and vision/text.
- Inference performance: the paper describes an inference pipeline but provides no quantitative latency/throughput/memory measurements, especially for interleaved image–text streaming at scale.
- CPU–GPU control-flow overhead: per-step token inspection for modality switching is identified as a bottleneck, but alternatives (e.g., on-GPU token gating, speculative decoding, blockwise generation policies) are not explored.
- Long-context mixed-modal modeling: with 4k tokens and 1024 tokens per image, the model’s ability to handle long multimodal documents is constrained; scaling context length or image-token compression strategies remain untested.
- Controllability of interleaving: mechanisms to precisely place, reference, or update images within long documents (layout control, cross-referencing, figure captions) are not studied.
- Compositional image generation: there is no evaluation of fine-grained controllability (object counts, spatial relations, text rendering) versus SOTA image generators; automatic metrics (e.g., CLIP-based alignment) are absent.
- Safety for image generation: beyond refusal tuning, there is no analysis of output filtering (e.g., NSFW/graphic content), watermarking/provenance, or prevention of generating realistic faces of real people.
- Adversarial multimodal robustness: resistance to image-based jailbreaks (e.g., adversarial patches, steganographic instructions), perturbations, or prompt-order sensitivity is not evaluated.
- Alignment methodology: only SFT is used; the impact of RLHF/RLAIF (and potential alignment tax) on mixed-modal helpfulness, hallucination, and over-refusal behavior remains unexplored.
- Bias and fairness: the paper does not assess demographic/representational bias in generated images or text (e.g., stereotyping, geographic skew) or propose mitigation strategies.
- Human evaluation limitations: prompts are vendor-sourced (not real user logs), moderately sized (1,048), and not publicly released; annotator demographics/instructions and reproducibility are limited; inter-annotator reliability is only moderate.
- Baseline fairness and images: augmenting GPT-4V/Gemini responses with DALL·E images may introduce mismatched priors; the fairness and limitations of these composite baselines are not analyzed.
- Stability theory vs. practice: stabilization techniques (QK-Norm, z-loss, norm reordering) are empirically motivated, but theoretical understanding of modality-induced norm growth/logit drift and their effect on generalization is not provided.
- Releasing artifacts: clarity on releasing model weights, training data, SFT data, and human-eval prompts is lacking, limiting reproducibility and community benchmarking.
Collections
Sign up for free to add this paper to one or more collections.