Prompting-based Synthetic Data Generation for Few-Shot Question Answering
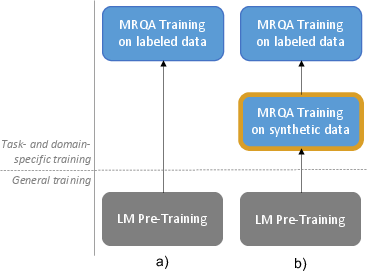
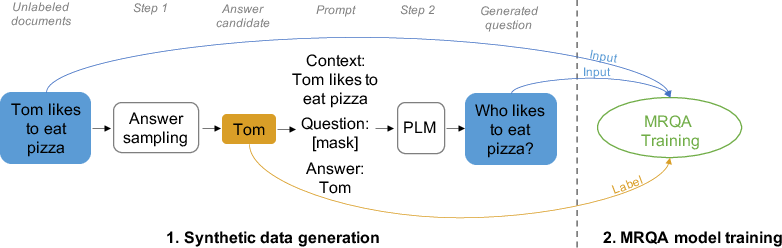
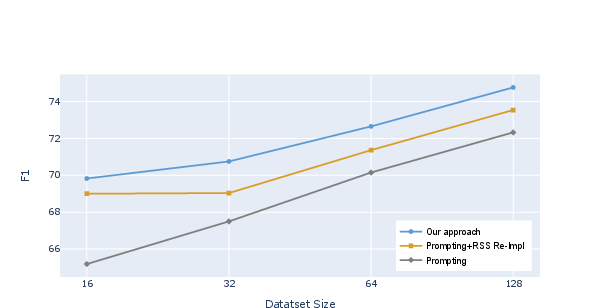
Abstract: Although LMs have boosted the performance of Question Answering, they still need plenty of data. Data annotation, in contrast, is a time-consuming process. This especially applies to Question Answering, where possibly large documents have to be parsed and annotated with questions and their corresponding answers. Furthermore, Question Answering models often only work well for the domain they were trained on. Since annotation is costly, we argue that domain-agnostic knowledge from LMs, such as linguistic understanding, is sufficient to create a well-curated dataset. With this motivation, we show that using LLMs can improve Question Answering performance on various datasets in the few-shot setting compared to state-of-the-art approaches. For this, we perform data generation leveraging the Prompting framework, suggesting that LLMs contain valuable task-agnostic knowledge that can be used beyond the common pre-training/fine-tuning scheme. As a result, we consistently outperform previous approaches on few-shot Question Answering.
- Synthetic QA Corpora Generation with Roundtrip Consistency.
- Do Not Have Enough Data? Deep Learning to the Rescue! Proceedings of the AAAI Conference on Artificial Intelligence, 34(05):7383–7390.
- Jatin Arora and Youngja Park. 2023. Split-NER: Named Entity Recognition via Two Question-Answering-based Classifications. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 416–426, Toronto, Canada. Association for Computational Linguistics.
- Language Models are Few-Shot Learners.
- How Optimal is Greedy Decoding for Extractive Question Answering?
- Rakesh Chada and Pradeep Natarajan. 2021. FewshotQA: A simple framework for few-shot learning of question answering tasks using pre-trained text-to-text models.
- Gotta: Generative Few-shot Question Answering by Prompt-based Cloze Data Augmentation.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- MRQA 2019 Shared Task: Evaluating Generalization in Reading Comprehension.
- Dialog State Tracking: A Neural Reading Comprehension Approach.
- Making Pre-trained Language Models Better Few-shot Learners.
- A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios.
- The Curious Case of Neural Text Degeneration.
- TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.
- Are You Smarter Than a Sixth Grader? Textbook Question Answering for Multimodal Machine Comprehension. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5376–5384.
- Natural Questions: a Benchmark for Question Answering Research. Transactions of the Association of Computational Linguistics.
- Zero-Shot Relation Extraction via Reading Comprehension.
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension.
- Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation.
- A Unified MRC Framework for Named Entity Recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5849–5859, Online. Association for Computational Linguistics.
- Entity-Relation Extraction as Multi-Turn Question Answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1340–1350, Florence, Italy. Association for Computational Linguistics.
- Named Entity Recognition without Labelled Data: A Weak Supervision Approach.
- Low-Resource NER by Data Augmentation With Prompting. volume 5, pages 4252–4258.
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.
- RoBERTa: A Robustly Optimized BERT Pretraining Approach.
- Template-free Prompt Tuning for Few-shot NER. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5721–5732, Seattle, United States. Association for Computational Linguistics.
- Unsupervised Domain Adaptation of Language Models for Reading Comprehension.
- Conversational Question Answering in Low Resource Scenarios: A Dataset and Case Study for Basque. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 436–442, Marseille, France. European Language Resources Association.
- Boosting Low-Resource Biomedical QA via Entity-Aware Masking Strategies.
- Training Question Answering Models From Synthetic Data.
- Language Models are Unsupervised Multitask Learners. undefined.
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- SQuAD: 100,000+ Questions for Machine Comprehension of Text.
- Few-Shot Question Answering by Pretraining Span Selection.
- Timo Schick and Hinrich Schütze. 2021. Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference.
- Improving Low-Resource Question Answering using Active Learning in Multiple Stages.
- B. Settles. 2012. Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning Series. Morgan & Claypool.
- Towards Zero-Shot Multilingual Synthetic Question and Answer Generation for Cross-Lingual Reading Comprehension.
- End-to-End Synthetic Data Generation for Domain Adaptation of Question Answering Systems.
- Noam Shazeer and Mitchell Stern. 2018. Adafactor: Adaptive Learning Rates with Sublinear Memory Cost.
- NewsQA: A Machine Comprehension Dataset.
- An overview of the BIOASQ large-scale biomedical semantic indexing and question answering competition. BMC Bioinformatics, 16(1):138.
- Attention Is All You Need.
- KECP: Knowledge Enhanced Contrastive Prompting for Few-shot Extractive Question Answering.
- PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks.
- From Clozing to Comprehending: Retrofitting Pre-trained Language Model to Pre-trained Machine Reader.
- HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering.
- Multi-Stage Pre-training for Low-Resource Domain Adaptation.
- EntQA: Entity Linking as Question Answering.
- Factual Probing Is [MASK]: Learning vs. Learning to Recall.
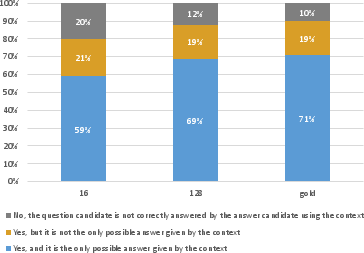
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

