- The paper introduces a hypernetwork-based approach for zero-shot tokenizer transfer that maintains performance close to original models.
- It employs a two-stage training process with a MIMICK-style warmup and a combined loss function to prevent embedding drift.
- Experiments on models like Mistral-7B and XLM-R show efficiency gains with reduced sequence lengths and accuracy retention within one to three percent.
Zero-Shot Tokenizer Transfer
Introduction
"Zero-Shot Tokenizer Transfer" introduces the problem of detaching LMs from the tokenizer they were initially trained with, a process referred to as Zero-Shot Tokenizer Transfer (ZeTT). This work addresses the challenge of maintaining model performance when swapping the original tokenizer with a new one without any additional data for training the new tokenizer embeddings. The paper proposes a new method using a hypernetwork to predict embeddings for any given tokenizer on-the-fly, thus enabling flexibility and efficiency across languages and domains by reducing tokenization costs.
Methodology
The core of the ZeTT problem lies in predicting suitable embeddings for an alternate tokenizer, for which the authors design a hypernetwork. This hypernetwork takes as input the tokenizer and outputs the corresponding embeddings. Notably, the hypernetwork is trained across a diverse distribution of tokenizers, enabling it to generalize and predict embeddings for unseen tokenizers.
Hypernetwork Architecture
The hypernetwork employs a transformer-based architecture to predict the embeddings for tokens in the new tokenizer's vocabulary. The hypernetwork operates by decomposing new tokens using the original tokenizer's function and embedding them using original embeddings. It consists of multiple transformer layers tasked with learning how to compose these sequences into suitable embeddings (Figure 1).
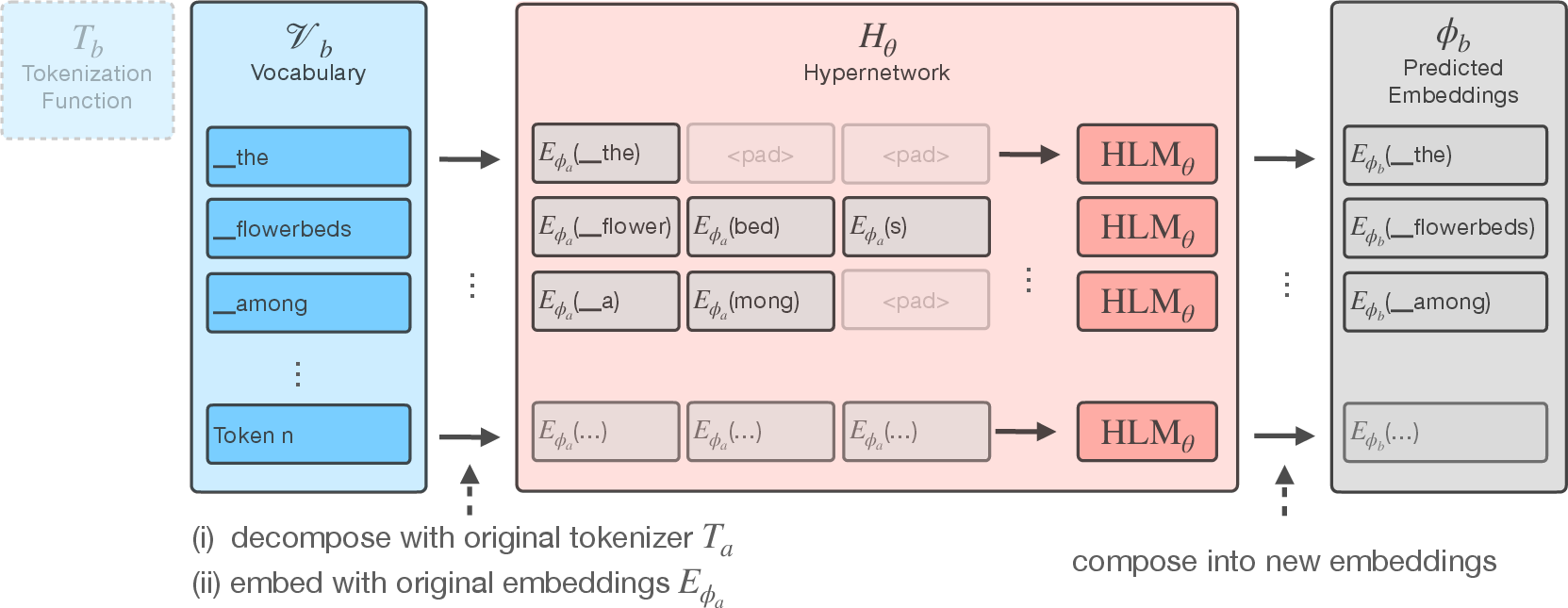
Figure 1: The hypernetwork consists of a LLM HLMθ that learns to compose embeddings for new tokenizers.
Training and Loss Functions
To effectively train the hypernetwork, the authors introduce a two-stage process. The initial stage involves a MIMICK-style warmup, where the hypernetwork learns to mimic the embedding parameters of the original model. This stage sets a foundational understanding, preventing divergence during subsequent training. The primary training minimizes a combined loss function comprising the main LLM loss and an auxiliary loss penalizing drift from the original embeddings:
Lθfinal=Lθ(Tb(x),Hθ(Vb,Tb),ψ)+α⋅Lθaux
Experiments
The authors validate their approach using Mistral-7B and XLM-R models across several benchmarks in natural languages and coding tasks. The hypernetwork is shown to maintain cross-lingual and domain-specific task performance close to original models while markedly shortening the tokenized sequences. For instance, the deployment of monolingual tokenizers results in a significant reduction in sequence length, contributing to faster inference times and improved efficiency.
The empirical results demonstrate the hypernetwork's capability to approximate original performance within just a few percentage points across various languages and tasks. Validated metrics include accuracy retention within one to three percent for language-specific tasks and exceeding baseline techniques like FOCUS (Tables 1 and 2).
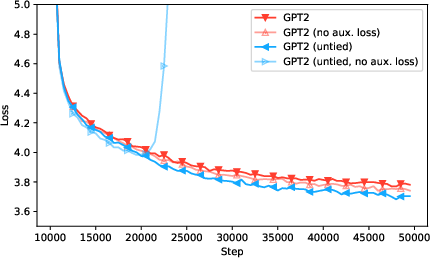
Figure 2: Language modeling loss of GPT2, and GPT2 with untied weight embeddings with and without the auxiliary loss across the first 50k training steps.
Discussion and Future Work
The authors find that the hypernetwork generalizes well to unseen tokenizers mainly due to its design of amortizing over tokenization functions, preserving performance regardless of specific tokenizer parameters. The method is sensitive to vocabulary overlap but demonstrates adaptability across different tokenizer sizes (Figure 3).
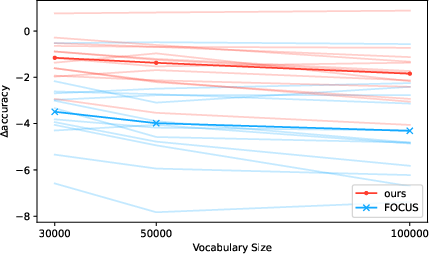
Figure 3: Difference in accuracy to the original XLM-R model on XNLI with our method across various vocabulary sizes.
One promising avenue for future research indicated by the authors is extending the method to scenarios with different pretokenization strategies and integrating features of other approaches that regularly adapt the embedding parameters.
Conclusion
This research marks a substantial progression toward making LLMs agnostic to the tokenizers they were trained with. By employing a hypernetwork capable of zero-shot embedding prediction, it addresses inefficiencies associated with tokenizer dependence, paving the way for more adaptable and reusable LLMs. The approach allows for quick adaptation with minimal additional training, enhancing model architectures without tokenization constraints.

