- The paper presents an online iterative RLHF pipeline that integrates human feedback via a Bradley-Terry based reward model for real-time LLM alignment.
- It introduces a preference modeling strategy that contrasts pairwise responses to capture nuanced human insights while mitigating verbosity bias.
- The approach employs iterative policy optimization and exploration techniques, achieving superior performance on both conversational and academic benchmarks.
RLHF Workflow: From Reward Modeling to Online RLHF
This essay delineates the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF), aimed at enhancing LLMs by integrating human preference signals. The paper delineates a practical recipe for implementing online iterative RLHF, addressing a significant gap in open-source RLHF projects, which are predominantly confined to offline learning settings.
Introduction to RLHF
Reinforcement Learning from Human Feedback (RLHF) constitutes a pivotal methodology for aligning LLMs with human values and preferences. Unlike supervised fine-tuning, RLHF incorporates human feedback, offering a more dynamic and iterative approach to training models. RLHF workflows generally involve a policy model π, a preference oracle, and reward maximization strategies using methods like the Bradley-Terry model (Figure 1).
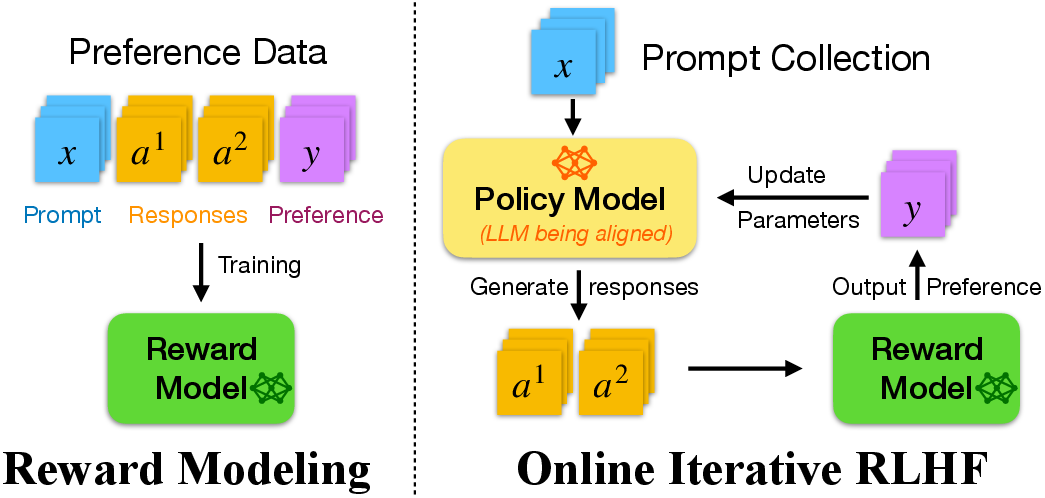
Figure 2: A simplified illustration of reward modeling and online iterative RLHF.
Reward Modeling Approach
Preference Datasets
A diverse set of open-source datasets serves as the foundation for reward and preference modeling, including HH-RLHF, SHP, HelpSteer, UltraFeedback, among others. These datasets provide varied contexts and human-annotated preferences essential for constructing robust models.
Bradley-Terry Reward Model
The reward model is implemented using the Maximum Likelihood Estimator (MLE) of the Bradley-Terry (BT) model. By training the model using preference data, the BT model approximates human feedback signals effectively, albeit exhibiting some limitations such as verbosity bias (Figure 3).
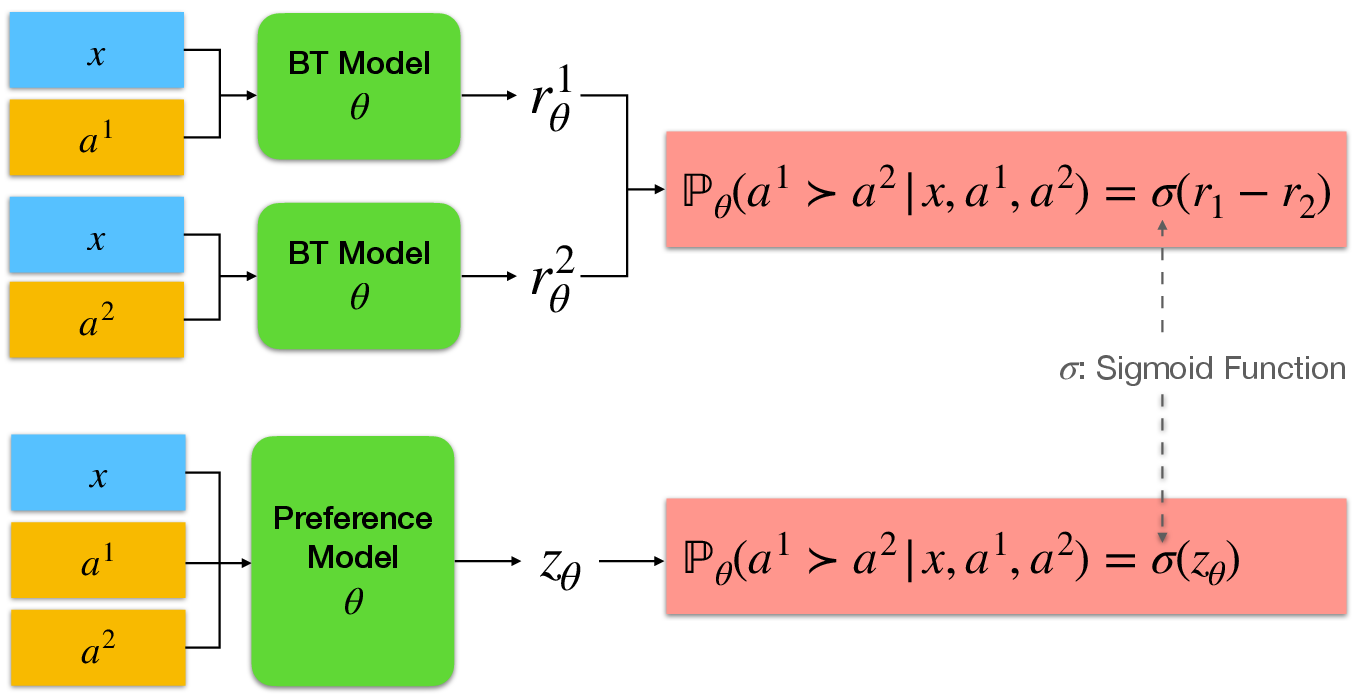
Figure 1: Illustration of the Bradley-Terry (BT) model and preference model.
Preference Model Construction
The preference model, unlike the scalar reward model, evaluates pairwise preferences between responses, providing nuanced insights into human feedback. The training of the preference model employs a strategy of optimizing for human-like responses by contrasting pairs of alternative outputs.
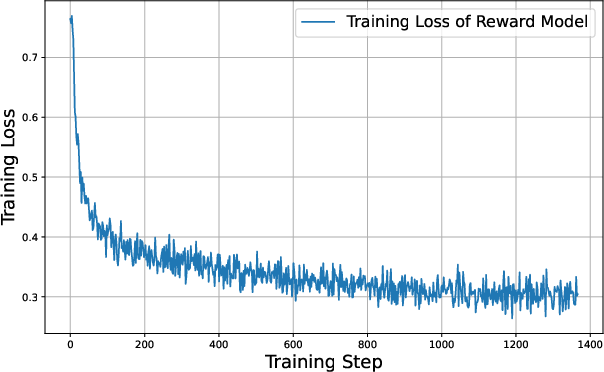
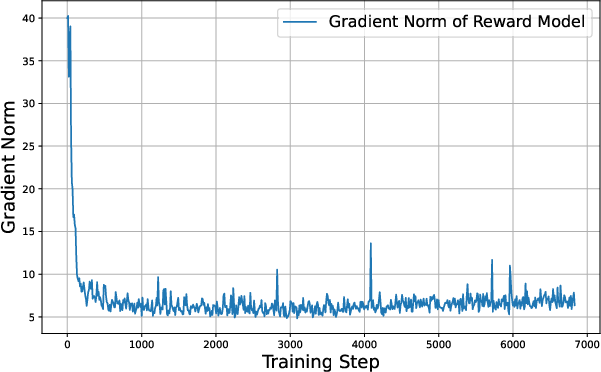
Figure 4: The training record of reward modeling. From the left to right, we present the records of training loss, gradient norm, and the learning rate, respectively.
Online Iterative RLHF Framework
Iterative Policy Optimization
Iterative policy optimization leverages data collected during training iterations to refine the model progressively (Figure 5). Unlike static datasets used in offline RLHF, this method dynamically integrates new data, improving out-of-distribution generalization and reducing over-optimization risks.
Exploration Strategies
The exploration strategy involves generating diverse model responses and leveraging techniques like rejection sampling and temperature adjustments to explore various potential outputs. This method, combined with strategic policy optimization, facilitates efficient navigation of the model's action space.
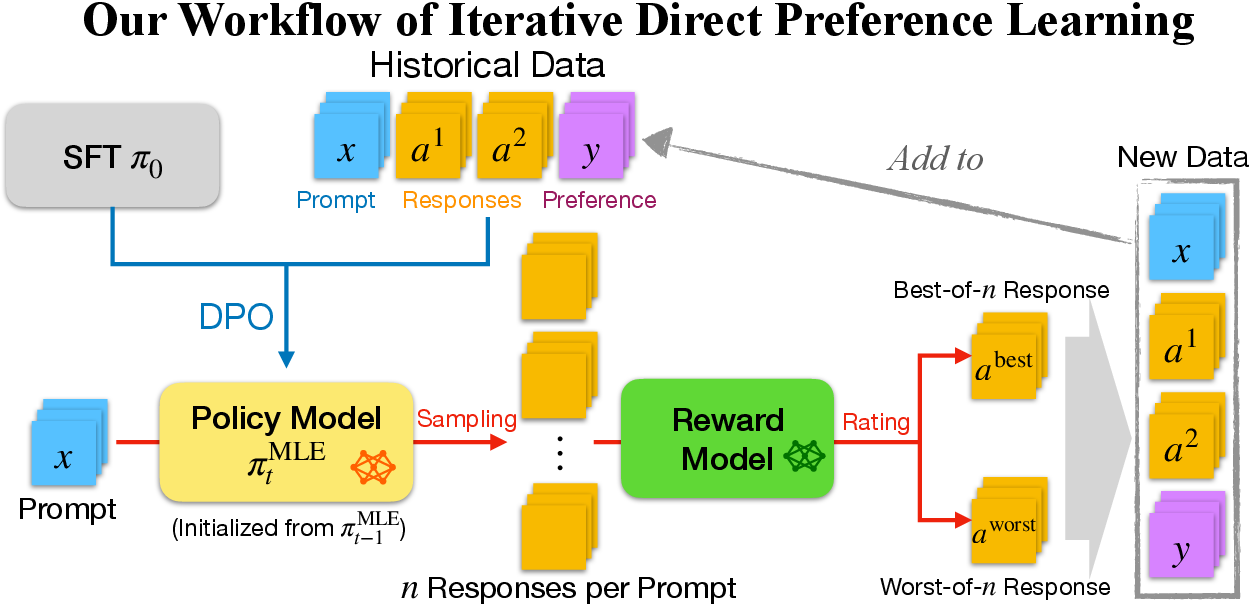
Figure 5: Illustration of our implementation of iterative direct preference learning. In iteration t=1, the historical dataset is empty, and the resulting policy model π1 is the same as its initialization.
Evaluation
Conversational and Academic Benchmarks
The resulting model demonstrates superior performance on conversational benchmarks like AlpacaEval-2, MT-Bench, and Chat-Arena-Hard. Additionally, academic benchmarks reveal no significant regression in reasoning capabilities, suggesting iterative RLHF does not adversely affect LLM performance in intellectual tasks (Figure 6).
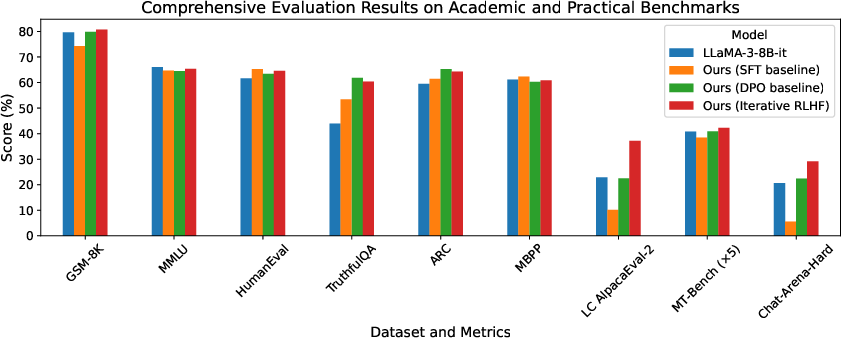
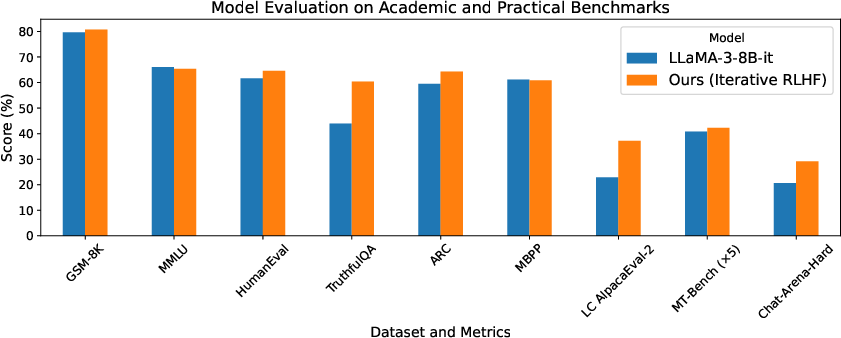
Figure 6: Evaluation of our models and LLaMA-3-8B-inst.
Length Bias Mitigation
A length penalty incorporated in reward modeling effectively mitigates verbosity bias, yielding concise responses without compromising alignment quality. This adjustment is validated through comparative analysis with other models.
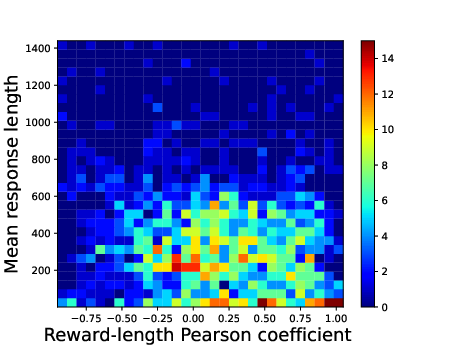
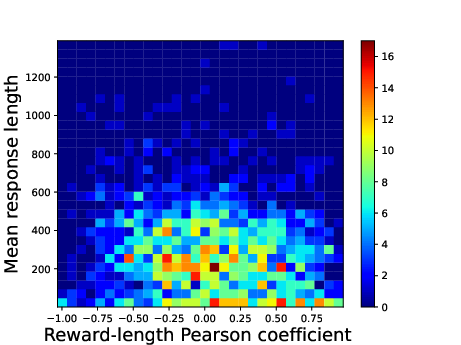
Figure 3: The heatmap of the Pearson correlation coefficients between reward and response length. For each prompt, we use the SFT model to generate 16 responses and compute the coefficient.
Conclusion
The workflow of Online Iterative RLHF provides a comprehensive methodology for LLM alignment, combining theoretical insights with practical implementation strategies. Further exploration of reward modeling nuances and exploration techniques can enhance model efficiency and performance, contributing to the development of more robust and human-aligned AI systems. Future directions include refining preference signal modeling and exploring more effective exploration strategies beyond rejection sampling.