- The paper introduces LETTER, a novel learnable tokenizer that integrates hierarchical semantics, collaborative signals, and diversity regularization to enhance generative recommendation.
- It employs a Residual Quantized Variational Autoencoder and contrastive alignment loss to effectively capture hierarchical semantics and incorporate collaborative filtering signals.
- Empirical results show that LETTER improves ranking metrics such as recall and NDCG by mitigating biases present in traditional tokenization methods.
Learnable Item Tokenization for Generative Recommendation
The paper "Learnable Item Tokenization for Generative Recommendation" (2405.07314) addresses the critical challenge of effective item tokenization to leverage LLMs in generative recommendation systems. It proposes a novel approach, LETTER (LEarnable Tokenizer for generaTivE Recommendation), which enhances item tokenization by integrating hierarchical semantics, collaborative signals, and code assignment diversity. This essay provides a detailed and technical summary of the approaches and methodologies presented in the paper, along with insights into their implications and potential future developments.
Objectives and Challenges in Item Tokenization
Existing item tokenization methods fall short in effectively bridging recommendation data with the language space of LLMs. They generally use ID identifiers, textual identifiers, or codebook-based identifiers, each with limitations:
- ID Identifiers often fail to encode semantic information effectively, limiting their generalizability to new items.
- Textual Identifiers can lead to biases due to varying lengths and lack hierarchical semantic distribution, making them less efficient in aligning with user preferences.
- Codebook-based Identifiers tend to miss incorporating collaborative signals and suffer from code assignment biases, which lead to generation biases.
An ideal tokenizer should address these challenges by enabling hierarchical semantic encoding, integrating collaborative signals, and ensuring diversity in token assignments.
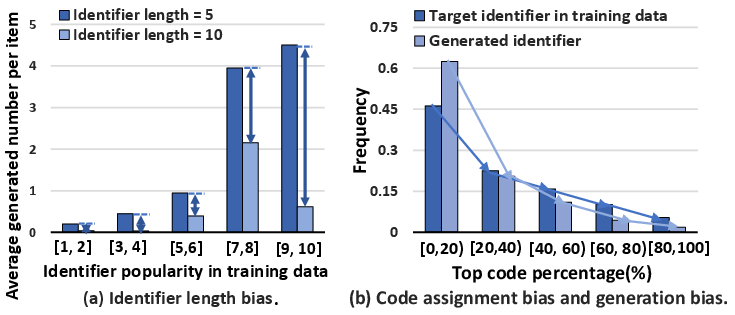
Figure 1: Illustration of identifiers' length bias, code assignment bias, and generation bias in existing systems.
LETTER: An Innovative Approach
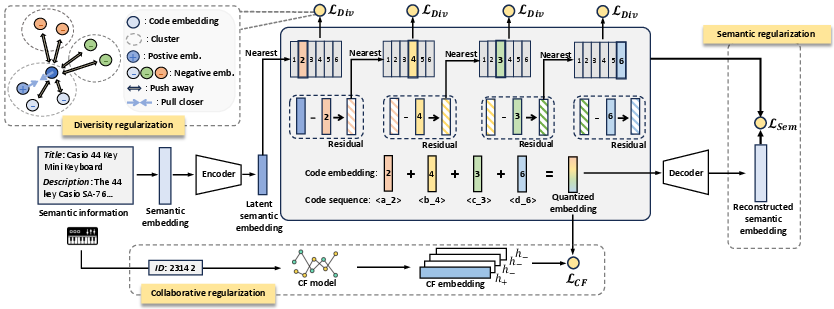
LETTER introduces a learnable tokenizer that employs multiple regularizations to generate identifiers that meet the outlined ideal criteria.
Semantic Regularization
LETTER uses a Residual Quantized Variational Autoencoder (RQ-VAE) to capture and encode hierarchical item semantics into fixed-length identifiers. This process allows the encoding to progress from coarse to fine-grained semantics, thus aligning with autoregressive characteristics of generative models.
- Quantization Process: The RQ-VAE recursively quantizes semantic residuals, ensuring the preservation of essential information while minimizing reconstruction loss.
Collaborative Regularization
To incorporate collaborative signals directly into the token assignment, LETTER employs contrastive alignment loss that aligns semantic embeddings with embeddings derived from collaborative filtering models like LightGCN.
- Contrastive Alignment: This enhancement causes similar items in terms of user interactions to have similar identifier sequences, improving the alignment between semantics and collaborative signals.
Diversity Regularization
LETTER addresses code assignment biases with diversity regularization by ensuring a more uniform distribution of code embeddings.
Implementation in Generative Models
LETTER was instantiated in models like TIGER and LC-Rec, showcasing improved performance in generative recommendation tasks.
Ranking-Guided Generation Loss
A novel ranking-guided generation loss is introduced, adjusting the traditional generation loss to focus on penalizing hard negatives, thereby enhancing the model's ranking capability.
- Temperature Adjustment: The adjustable parameter τ alters the penalty intensity on hard negatives, optimizing the ranking metrics like recall and NDCG.
Empirical Evaluation
LETTER's performance was evaluated across several datasets, demonstrating significant improvements over existing methods. Notably, its approach mitigated commonly observed biases, validated through experimental results showing smoother code assignment distributions and enhanced diversity.
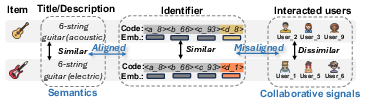
Figure 3: Misalignment issue between identifiers and collaborative signals addressed by LETTER.
Conclusion
The paper proposes LETTER, a sophisticated item tokenization framework optimized for LLM-based generative recommendation. By addressing the limitations of prior tokenization methods, LETTER enhances identifiers with hierarchical semantics, collaborative signals, and diverse code assignments, ultimately advancing the state-of-the-art in generative recommender systems. Future directions include exploring tokenization integrated with user behaviors and cross-domain recommendations, further bridging the gap between traditional recommendation methods and contemporary LLM capabilities.