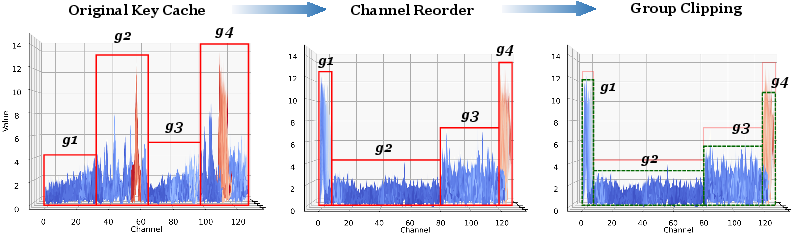
- The paper presents SKVQ, a method that uses sliding-window and channel reordering to enable low-bitwidth quantization of KV caches for LLMs.
- It employs clipped dynamic quantization with channel reordering to minimize errors and maintain full precision for critical, recent tokens.
- Experiments on LongBench benchmark show SKVQ outperforms existing methods like KIVI, achieving effective 2-bit key and 1.5-bit value compression.
SKVQ: Sliding-window Key and Value Cache Quantization for LLMs
Introduction
The ability of LLMs to process longer token sequences introduces challenges related to the efficient management of Key-Value (KV) caches, which are essential to LLM inference operations. Traditional KV cache handling methods prove inadequate as they consume significant memory, especially with extended context lengths. This paper introduces SKVQ, a method designed to achieve low-bitwidth KV cache quantization to mitigate memory bottlenecks while maintaining model accuracy and efficiency.
Method
Clipped Dynamic Quantization with Channel Reorder
SKVQ leverages a novel approach to mitigate quantization errors by grouping similar channels through channel reordering, thereby enhancing quantization accuracy:
Sliding Window Quantization Strategy
To address the cumulative quantization errors typical in long-context tasks, the sliding window strategy preserves a small, recent segment of the KV cache in full precision:
- Locality Exploitation: By maintaining a sliding window of the most recent tokens in full precision, this strategy capitalizes on the locality of attention within transformer architectures.
- Important KV Cache Filter: Involves identifying and maintaining tokens critical to model inference accuracy, including recent tokens and certain important tokens that are sensitive to quantization.
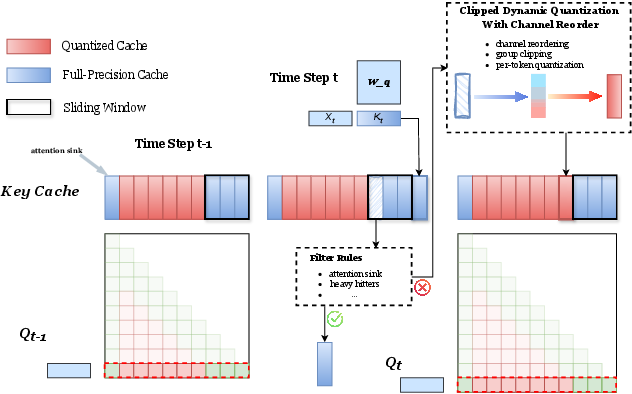
Figure 2: Overview of sliding window quantization Strategy. In each time step, we ensure the latest w KV cache is full precision. For a token cache that slides out of the window, we make a decision based on the filter rules and choose whether to retain it to high precision.
Results
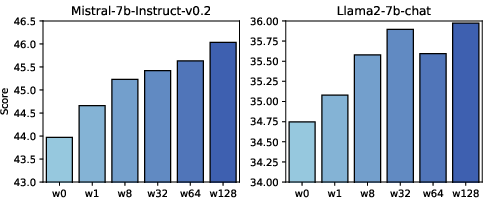
SKVQ was evaluated across multiple tasks on the LongBench benchmark using models such as LLaMA and Mistral families. It consistently outperformed existing quantization methods like KIVI and SmoothQuant, particularly in scenarios involving long-context processing where traditional quantization methods suffer from significant accuracy losses.
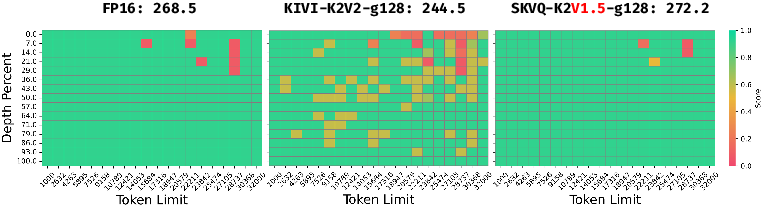
Figure 3: Comparison of SKVQ with KIVI on needle in haystack test. SKVQ achieved higher scores while using lower bitwidth.
Conclusion
SKVQ presents a advancements in the quantization of KV caches for large context tasks addressed by LLMs. By implementing a sliding window combined with channel-specific handling through dynamic quantization and reordering, SKVQ significantly improves memory usage and processing efficiency without sacrificing accuracy. Future work could explore optimizing filter rules further and enhancing integration into existing inference systems, advancing the potential of LLMs to process even longer contexts efficiently.
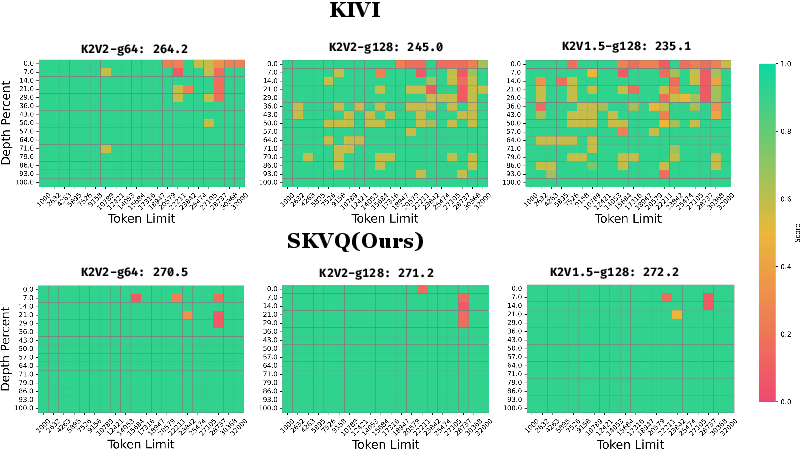
Figure 5: Comparison of SKVQ with KIVI on 32k context length needle in haystack test. The baseline score is 268.5. We vary the group size from 64 to 128, and vary the quantization bits from (key 2bits, value 2bits) to (key 2bits, value 1.5bits).