- The paper introduces exponential gating and novel memory architectures (sLSTM and mLSTM) to enhance traditional LSTM performance for sequence modeling tasks.
- The xLSTM architecture achieves linear computation and improved memory capacity, outperforming standard LSTMs and approaching Transformer performance.
- Experimental results on formal language tasks and the Long Range Arena highlight xLSTM’s potential across language modeling and reinforcement learning applications.
"xLSTM: Extended Long Short-Term Memory" (2405.04517)
Introduction
The "xLSTM: Extended Long Short-Term Memory" paper addresses the limitations of traditional LSTM models when scaled to billions of parameters and compared to Transformers. Despite the proven effectiveness of LSTMs in sequence modelling, notably within the realms of LLMs and reinforcement learning tasks, the sequential processing requirement of LSTMs has hindered their scalability and parallelization. The authors propose new modifications to the LSTM memory cell structure, introducing two variants: sLSTM and mLSTM, both equipped with exponential gating mechanisms. These enhancements aim to address the known constraints of LSTMs by offering improvements in memory capacity, processing speed, and overall model performance.
Extended LSTM Architecture
The xLSTM introduces two primary modifications: exponential gating and novel memory structures. The first variant, sLSTM, uses scalar memory and incorporates exponential gates alongside normalization techniques for memory mixing. The second variant, mLSTM, expands the memory cell from a scalar to a matrix, utilizing matrix multiplications for memory retrieval, thus enabling parallelization by abandoning hidden-hidden recurrent connections. These novel memory structures integrate into residual block architectures called xLSTM blocks, which, when stacked residue-wise, form an xLSTM architecture capable of achieving competitive performance in language modeling tasks.
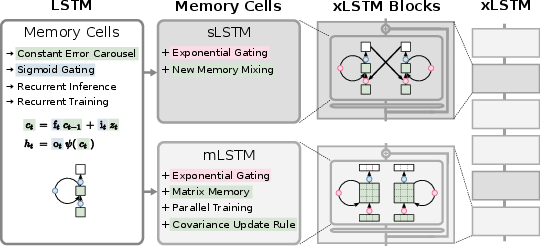
Figure 1: The extended LSTM (xLSTM) family exhibits its original form and enhancements in sLSTM and mLSTM memory cells, which introduce exponential gating and matrix memory integration.
Memory Capacity and Speed Considerations
The xLSTM model contrasts with Transformers by offering linear computation and constant memory complexity with respect to sequence length. Given its compressive nature, industrial applications benefit from the low computational demands, especially notable in edge-course implementations. mLSTM’s matrix memory, high in computation complexity, is optimized for parallel GPU execution, minimizing wall clock time overhead. Despite sLSTM’s slower performance compared to mLSTM, optimizations have led to efficient CUDA implementations, reducing speed disparities.
The research aligns with efforts in linearizing attention mechanisms through alternatives like Linformer, Performer, and other state-space models, which are linear in context length and exhibit desirable scaling properties. In terms of scalable recurrent networks, xLSTM resonates conceptually with approaches like RWKV and Retention, which aim at improving parallel processing and memory retention capabilities.
Experiments
The paper evaluates the xLSTM’s capability through synthetic tasks in formal language domains and its performance across the Long Range Arena benchmark. Experiments reveal xLSTM’s advantageous position in handling memory capacity challenges in Multi-Query Associative Recall (MQAR) tasks and extrapolation capabilities in sequence length, outperforming both traditional LSTMs and contemporary Transformer models.
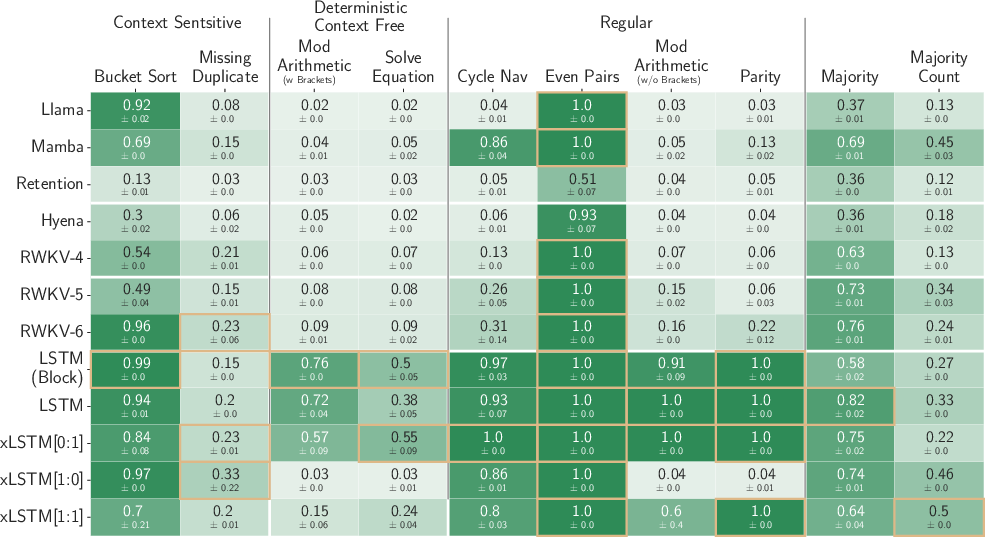
Figure 2: Demonstration of xLSTM's exponential gating impact on formal language tasks as evaluated under the Chomsky hierarchy.
Limitations
The xLSTM architecture, despite its enhanced performance, presents limitations in terms of the parallelization of sLSTM due to its memory mixing property. Moreover, the initialization of gating mechanisms requires careful tailoring to evade computational inefficiencies, while potential overloading concerns persist when extending sequence lengths beyond 16k.
Conclusion
The xLSTM extends the capabilities of LSTM architectures, presenting a viable alternative to state-of-the-art transformer models in large-scale sequence modeling. Its architecture offers promising results in language modeling, with indications that further scaling will remain competitive in the field of LLMs. Looking ahead, xLSTM’s impact may resonate across diverse fields within AI, including time-series prediction and reinforcing learning applications, given its innovative enhancements to memory management within neural architectures.