Vision-based 3D occupancy prediction in autonomous driving: a review and outlook
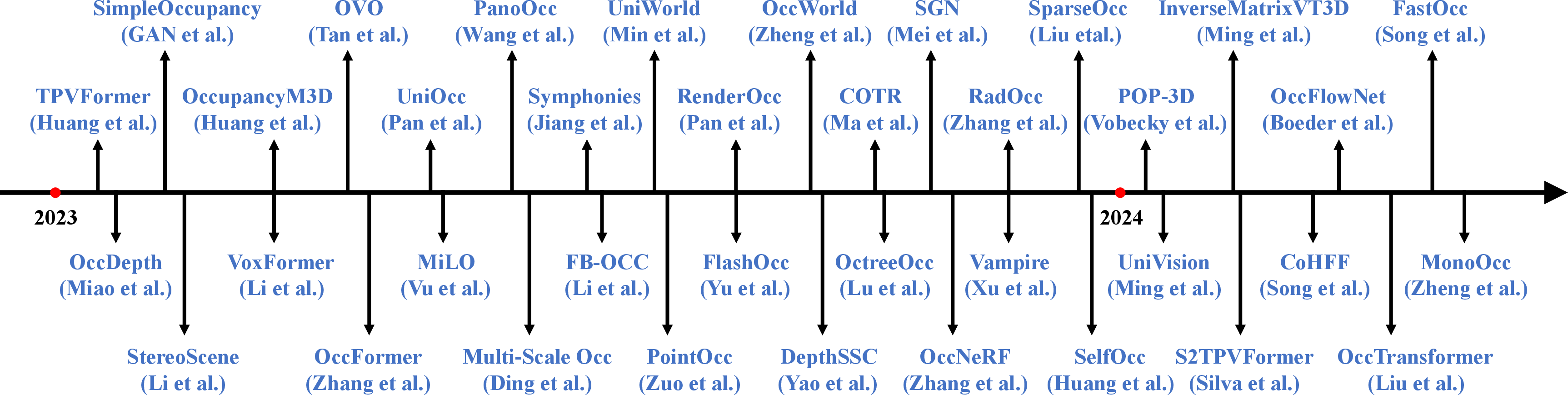
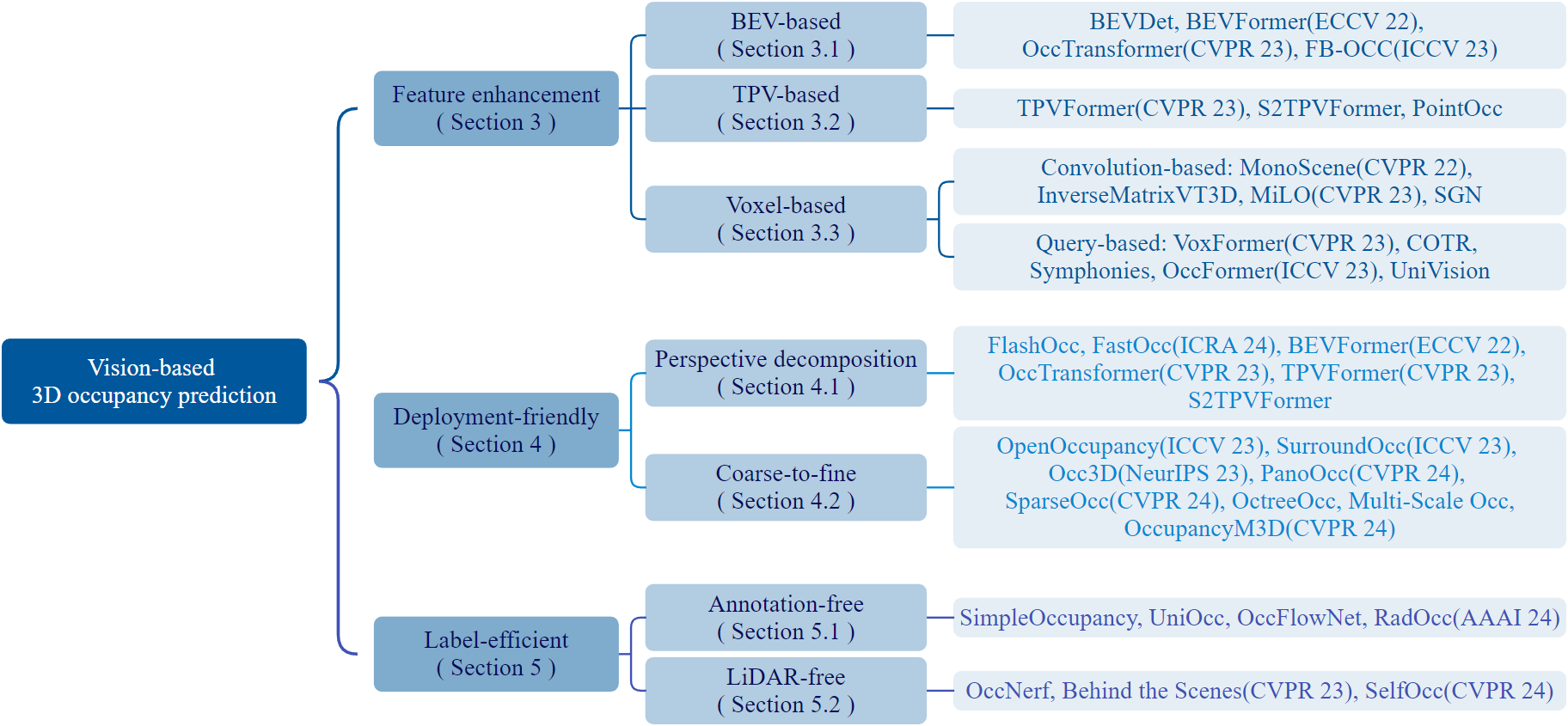
Abstract: In recent years, autonomous driving has garnered escalating attention for its potential to relieve drivers' burdens and improve driving safety. Vision-based 3D occupancy prediction, which predicts the spatial occupancy status and semantics of 3D voxel grids around the autonomous vehicle from image inputs, is an emerging perception task suitable for cost-effective perception system of autonomous driving. Although numerous studies have demonstrated the greater advantages of 3D occupancy prediction over object-centric perception tasks, there is still a lack of a dedicated review focusing on this rapidly developing field. In this paper, we first introduce the background of vision-based 3D occupancy prediction and discuss the challenges in this task. Secondly, we conduct a comprehensive survey of the progress in vision-based 3D occupancy prediction from three aspects: feature enhancement, deployment friendliness and label efficiency, and provide an in-depth analysis of the potentials and challenges of each category of methods. Finally, we present a summary of prevailing research trends and propose some inspiring future outlooks. To provide a valuable reference for researchers, a regularly updated collection of related papers, datasets, and codes is organized at https://github.com/zya3d/Awesome-3D-Occupancy-Prediction.
- Monocular 3d object detection for autonomous driving. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016, 2147–2156
- Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, 2040–2049
- Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019, 8445–8453
- Stereo r-cnn based 3d object detection for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019, 7644–7652
- Dsgn: Deep stereo geometry network for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020, 12536–12545
- 3d object detection from images for autonomous driving: a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
- Second: Sparsely embedded convolutional detection. Sensors, 2018, 18(10): 3337
- Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021, 11784–11793
- Voxel r-cnn: Towards high performance voxel-based 3d object detection. In: Proceedings of the AAAI conference on artificial intelligence. 2021, 1201–1209
- Pointrcnn: 3d object proposal generation and detection from point cloud. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019, 770–779
- Pc-rgnn: Point cloud completion and graph neural network for 3d object detection. In: Proceedings of the AAAI conference on artificial intelligence. 2021, 3430–3437
- Octr: Octree-based transformer for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023, 5166–5175
- Pointpainting: Sequential fusion for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020, 4604–4612
- Clocs: Camera-lidar object candidates fusion for 3d object detection. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2020, 10386–10393
- Multi-view 3d object detection network for autonomous driving. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017, 1907–1915
- Epnet: Enhancing point features with image semantics for 3d object detection. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XV 16. 2020, 35–52
- Cat-det: Contrastively augmented transformer for multi-modal 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, 908–917
- Multi-modal 3d object detection in autonomous driving: A survey and taxonomy. IEEE Transactions on Intelligent Vehicles, 2023
- Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790, 2021
- Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2023, 1477–1485
- Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In: European conference on computer vision. 2022, 1–18
- Sa-bev: Generating semantic-aware bird’s-eye-view feature for multi-view 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, 3348–3357
- Vision-centric bev perception: A survey. arXiv preprint arXiv:2208.02797, 2022
- Occupancy networks: Learning 3d reconstruction in function space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019, 4460–4470
- Convolutional occupancy networks. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. 2020, 523–540
- nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020, 11621–11631
- Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020, 2446–2454
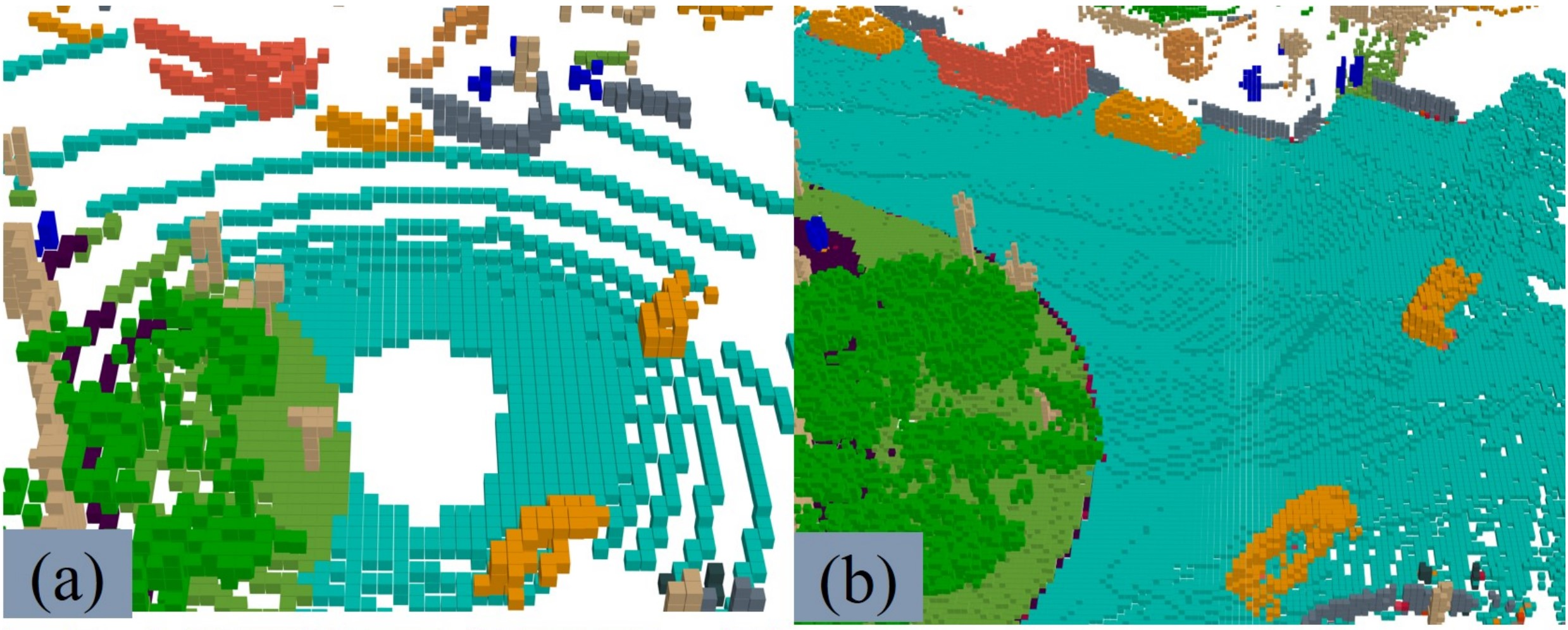
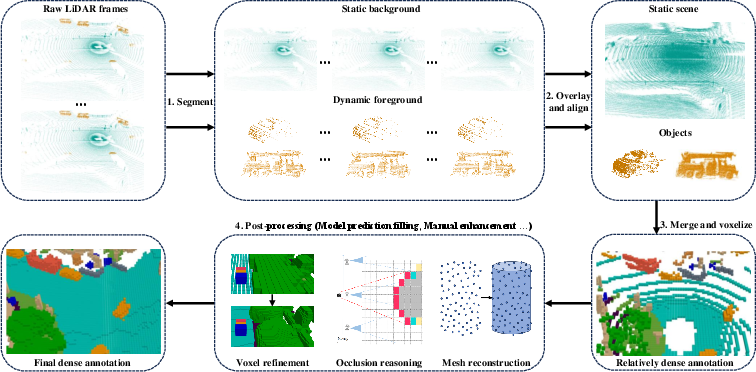
- Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, 21729–21740
- Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception. arXiv preprint arXiv:2303.03991, 2023
- Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving. arXiv preprint arXiv:2304.14365, 2023
- Scene as occupancy. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, 8406–8415
- Vdbfusion: Flexible and efficient tsdf integration of range sensor data. Sensors, 2022, 22(3): 1296
- Indoor segmentation and support inference from rgbd images. In: Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part V 12. 2012, 746–760
- Semantickitti: A dataset for semantic scene understanding of lidar sequences. In: Proceedings of the IEEE/CVF international conference on computer vision. 2019, 9297–9307
- Are we ready for autonomous driving? the kitti vision benchmark suite. In: 2012 IEEE conference on computer vision and pattern recognition. 2012, 3354–3361
- Voxformer: Sparse voxel transformer for camera-based 3d semantic scene completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, 9087–9098
- Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 3101–3109
- Cao A Q, Charette d R. Monoscene: Monocular 3d semantic scene completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, 3991–4001
- Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2023, 1486–1494
- Tri-perspective view for vision-based 3d semantic occupancy prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, 9223–9232
- Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction. arXiv preprint arXiv:2304.05316, 2023
- Symphonize 3d semantic scene completion with contextual instance queries. arXiv preprint arXiv:2306.15670, 2023
- Camera-based 3d semantic scene completion with sparse guidance network. arXiv preprint arXiv:2312.05752, 2023
- Myeongjin T V J H K, Jeong K S J S G. Milo: Multi-task learning with localization ambiguity suppression for occupancy prediction cvpr 2023 occupancy challenge report. arXiv preprint arXiv:2306.11414, 2023
- Fb-bev: Bev representation from forward-backward view transformations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, 6919–6928
- Stereoscene: Bev-assisted stereo matching empowers 3d semantic scene completion. arXiv preprint arXiv:2303.13959, 2023
- Occtransformer: Improving bevformer for 3d camera-only occupancy prediction. arXiv preprint arXiv:2402.18140, 2024
- 3d sketch-aware semantic scene completion via semi-supervised structure prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, 4193–4202
- Anisotropic convolutional networks for 3d semantic scene completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, 3351–3359
- Lmscnet: Lightweight multiscale 3d semantic completion. In: 2020 International Conference on 3D Vision (3DV). 2020, 111–119
- Fully sparse 3d panoptic occupancy prediction. arXiv preprint arXiv:2312.17118, 2023
- Octreeocc: Efficient and multi-granularity occupancy prediction using octree queries. arXiv preprint arXiv:2312.03774, 2023
- Flashocc: Fast and memory-efficient occupancy prediction via channel-to-height plugin. arXiv preprint arXiv:2311.12058, 2023
- Yao J, Zhang J. Depthssc: Depth-spatial alignment and dynamic voxel resolution for monocular 3d semantic scene completion. arXiv preprint arXiv:2311.17084, 2023
- Multi-scale occ: 4th place solution for cvpr 2023 3d occupancy prediction challenge. arXiv preprint arXiv:2306.11414, 2023
- Fastocc: Accelerating 3d occupancy prediction by fusing the 2d bird’s-eye view and perspective view. arXiv preprint arXiv:2403.02710, 2024
- Monoocc: Digging into monocular semantic occupancy prediction. arXiv preprint arXiv:2403.08766, 2024
- Panoocc: Unified occupancy representation for camera-based 3d panoptic segmentation. arXiv preprint arXiv:2306.10013, 2023
- Ovo: Open-vocabulary occupancy. arXiv preprint arXiv:2305.16133, 2023
- Selfocc: Self-supervised vision-based 3d occupancy prediction. arXiv preprint arXiv:2311.12754, 2023
- Occnerf: Self-supervised multi-camera occupancy prediction with neural radiance fields. arXiv preprint arXiv:2312.09243, 2023
- Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision. arXiv preprint arXiv:2309.09502, 2023
- Uniocc: Unifying vision-centric 3d occupancy prediction with geometric and semantic rendering. arXiv preprint arXiv:2306.09117, 2023
- Radocc: Learning cross-modality occupancy knowledge through rendering assisted distillation. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 7060–7068
- Occflownet: Towards self-supervised occupancy estimation via differentiable rendering and occupancy flow. arXiv preprint arXiv:2402.12792, 2024
- Philion J, Fidler S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. 2020, 194–210
- Fb-occ: 3d occupancy prediction based on forward-backward view transformation. arXiv preprint arXiv:2307.01492, 2023
- S2tpvformer: Spatio-temporal tri-perspective view for temporally coherent 3d semantic occupancy prediction. arXiv preprint arXiv:2401.13785, 2024
- Pointocc: Cylindrical tri-perspective view for point-based 3d semantic occupancy prediction. arXiv preprint arXiv:2308.16896, 2023
- U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. 2015, 234–241
- Inversematrixvt3d: An efficient projection matrix-based approach for 3d occupancy prediction. arXiv preprint arXiv:2401.12422, 2024
- Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016, 770–778
- Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, 2117–2125
- Occdepth: A depth-aware method for 3d semantic scene completion. arXiv preprint arXiv:2302.13540, 2023
- Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020
- Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, 16000–16009
- Masked-attention mask transformer for universal image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, 1290–1299
- Cotr: Compact occupancy transformer for vision-based 3d occupancy prediction. arXiv preprint arXiv:2312.01919, 2023
- Univision: A unified framework for vision-centric 3d perception. arXiv preprint arXiv:2401.06994, 2024
- Learning occupancy for monocular 3d object detection. arXiv preprint arXiv:2305.15694, 2023
- Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 2021, 65(1): 99–106
- A simple attempt for 3d occupancy estimation in autonomous driving. arXiv preprint arXiv:2303.10076, 2023
- Regulating intermediate 3d features for vision-centric autonomous driving. arXiv preprint arXiv:2312.11837, 2023
- Behind the scenes: Density fields for single view reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, 9076–9086
- Panacea: Panoramic and controllable video generation for autonomous driving. arXiv preprint arXiv:2311.16813, 2023
- Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
- Wovogen: World volume-aware diffusion for controllable multi-camera driving scene generation. arXiv preprint arXiv:2312.02934, 2023
- Occworld: Learning a 3d occupancy world model for autonomous driving. arXiv preprint arXiv:2311.16038, 2023
- Uniworld: Autonomous driving pre-training via world models. arXiv preprint arXiv:2308.07234, 2023
- Collaborative semantic occupancy prediction with hybrid feature fusion in connected automated vehicles. arXiv preprint arXiv:2402.07635, 2024
- Pop-3d: Open-vocabulary 3d occupancy prediction from images. Advances in Neural Information Processing Systems, 2024, 36
- Cam4docc: Benchmark for camera-only 4d occupancy forecasting in autonomous driving applications. arXiv preprint arXiv:2311.17663, 2023
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.