Verification and Refinement of Natural Language Explanations through LLM-Symbolic Theorem Proving
Abstract: Natural language explanations represent a proxy for evaluating explanation-based and multi-step Natural Language Inference (NLI) models. However, assessing the validity of explanations for NLI is challenging as it typically involves the crowd-sourcing of apposite datasets, a process that is time-consuming and prone to logical errors. To address existing limitations, this paper investigates the verification and refinement of natural language explanations through the integration of LLMs and Theorem Provers (TPs). Specifically, we present a neuro-symbolic framework, named Explanation-Refiner, that integrates TPs with LLMs to generate and formalise explanatory sentences and suggest potential inference strategies for NLI. In turn, the TP is employed to provide formal guarantees on the logical validity of the explanations and to generate feedback for subsequent improvements. We demonstrate how Explanation-Refiner can be jointly used to evaluate explanatory reasoning, autoformalisation, and error correction mechanisms of state-of-the-art LLMs as well as to automatically enhance the quality of explanations of variable complexity in different domains.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy summary
This paper is about teaching AI systems to explain their answers in a way that is correct, step by step, and checkable. The authors built a system called Explanation-Refiner that combines two kinds of tools:
- LLMs, which are good at writing explanations in plain English.
- A “theorem prover,” a strict logic checker that can verify whether those explanations really prove what they claim.
By making these two work together in a loop—with the logic checker giving feedback and the LLM fixing mistakes—the system turns messy or partly wrong explanations into clear, logically correct ones.
What questions did the paper ask?
The researchers focused on three simple questions:
- Can we automatically check and improve (refine) the explanations written in natural language?
- Can we fix and improve explanations written by humans, not just by AI?
- How good are today’s LLMs at explaining their reasoning, turning sentences into logic, and fixing errors across different kinds of problems?
How did they do it?
To make this understandable, think of solving a puzzle in class:
- The LLM is like a student who writes down how they solved the puzzle.
- The theorem prover is like a very strict teacher who checks whether each step is logically valid.
- If the teacher finds a mistake, they point to the exact step that failed. The student then fixes that step and tries again.
Here’s the approach, step by step:
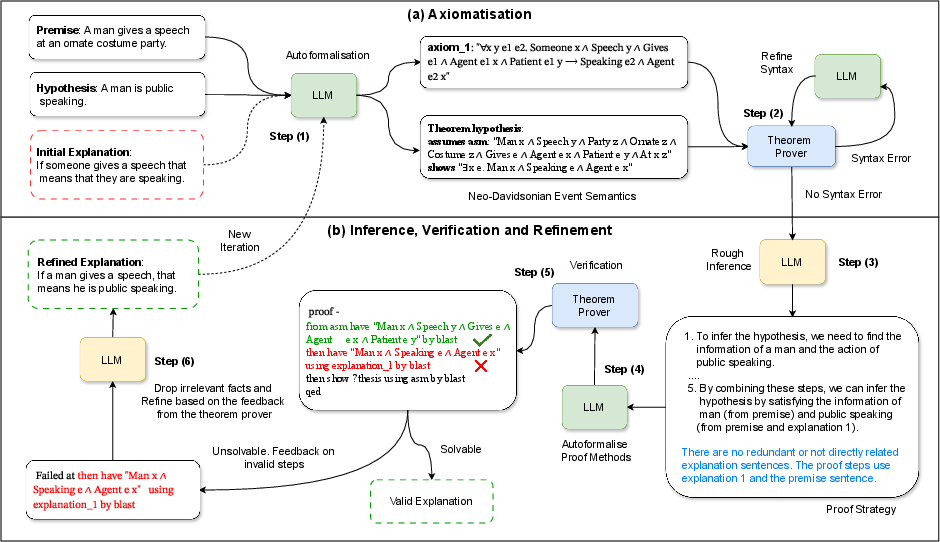
Step 1: Write and translate the explanation
- The LLM writes explanation sentences in plain English, like “If someone gives a speech, then they are speaking.”
- Those sentences are then translated into formal logic—a precise “math-like” language that computers can check. The paper uses a style called Neo-Davidsonian event semantics to keep track of actions and who did what.
- For example, “A man gives a speech” becomes something like: there is an event of giving, with the man as the agent (doer) and the speech as the patient (thing acted on).
- This helps keep all the important details (who, what, action) when turning sentences into logic.
Step 2: Check with a logic tool (theorem prover)
- The team uses a tool called Isabelle/HOL, a proof assistant. It tries to prove that:
- Premise + Explanation ⇒ Hypothesis
- If something doesn’t make sense, Isabelle tells you where the logic breaks. It also catches “syntax errors” (like missing brackets or mismatched types—similar to a programming typo).
Step 3: Fix it in a loop (feedback and refinement)
- Using the exact error from the theorem prover, the LLM:
- Removes irrelevant or repeated explanation steps.
- Repairs the broken step.
- Improves the logic translation and proof steps.
- This loop repeats a few times until the explanation works or the system gives up after a set number of tries.
What problems did they test on?
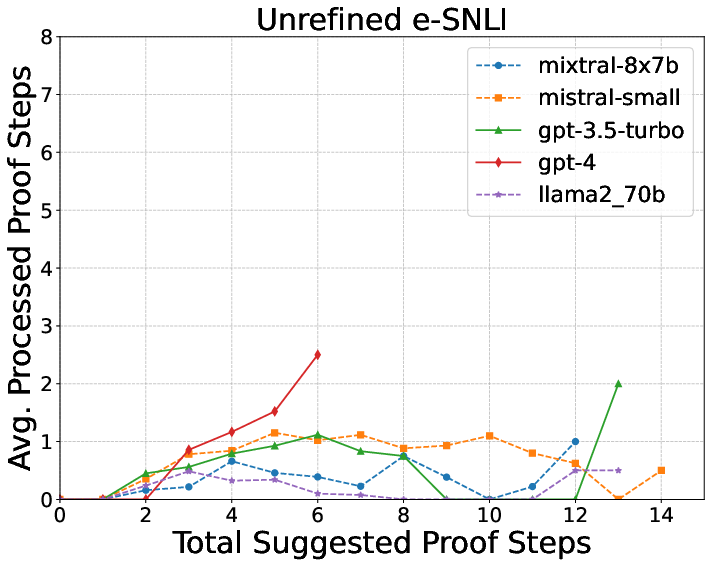
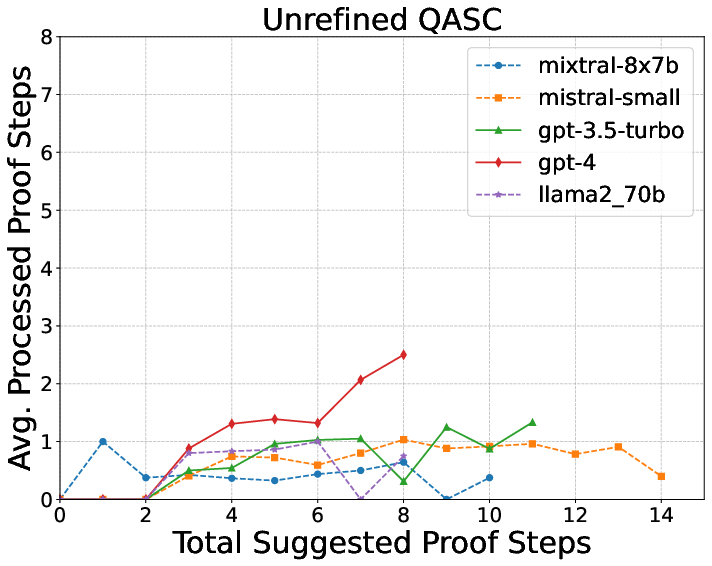
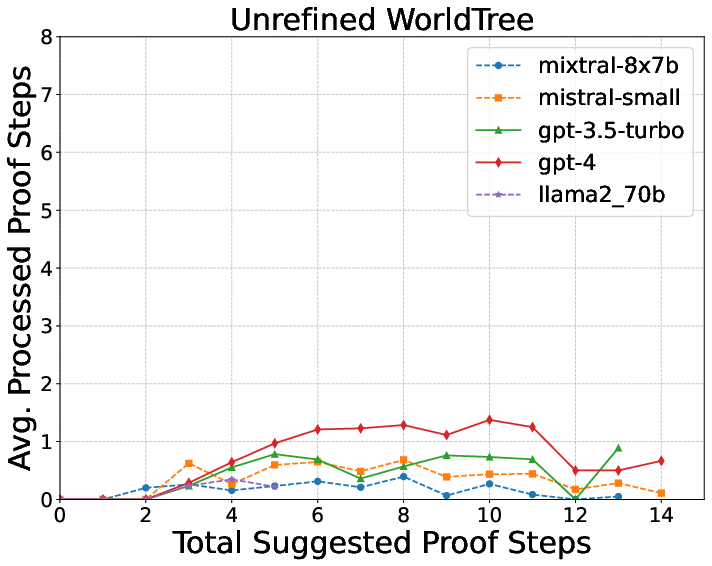
They tested on three datasets with growing difficulty:
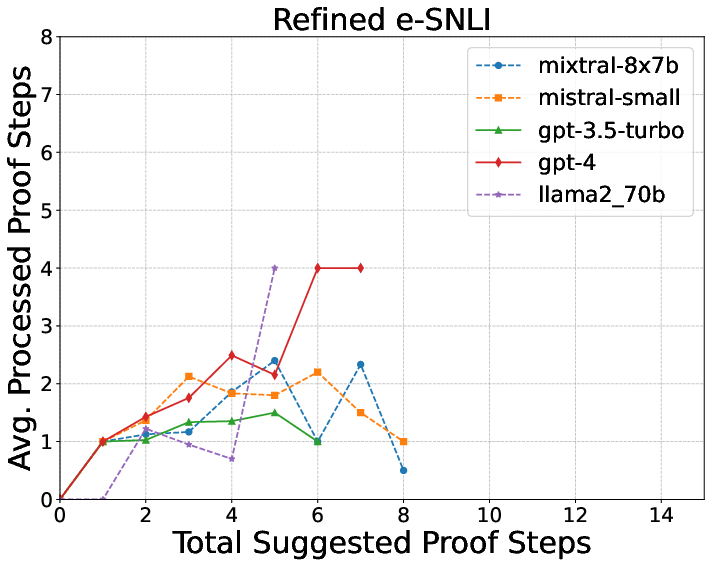
- e-SNLI: Short, simple examples with one explanation sentence.
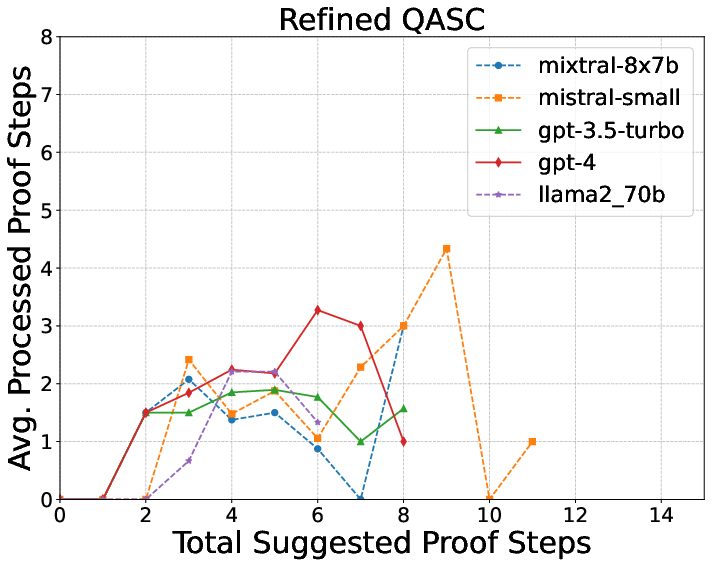
- QASC: Science questions with a couple of explanation sentences.
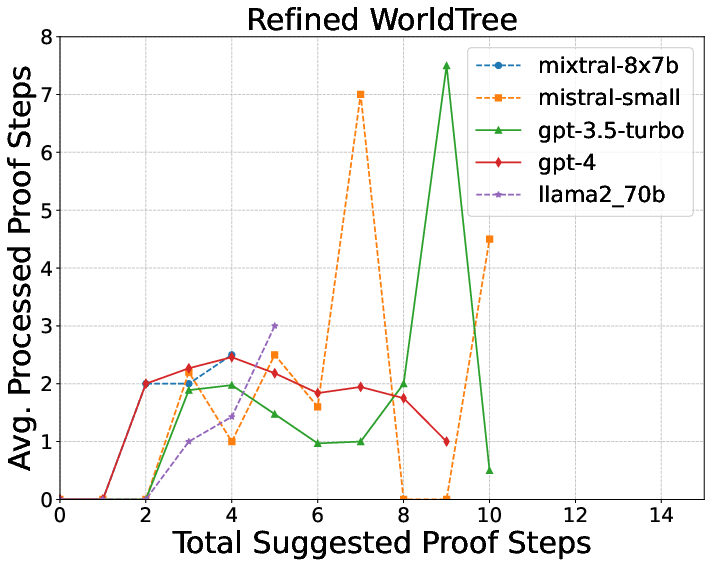
- WorldTree: Harder science questions that may need many (up to 16) explanation sentences combined together.
What did they find?
Here are the key results and why they matter:
- The logic checker’s feedback makes explanations much better.
- Using GPT-4, the percentage of logically valid explanations jumped:
- e-SNLI: from 36% to 84%
- QASC: from 12% to 55%
- WorldTree: from 2% to 37%
- Why this matters: It shows that careful checking and fixing can make AI explanations far more trustworthy.
- The system reduced “syntax errors” in the logical code a lot (think of it like fewer typos and formatting mistakes):
- Average reductions were about 69%, 62%, and 55% across the three datasets.
- Why this matters: Cleaner logic code means the theorem prover can do its job and verify reasoning.
- More complex explanations are harder.
- Short, simple cases (e-SNLI) worked best.
- Longer, multi-step science explanations (WorldTree) were toughest.
- Some LLMs are better at this than others.
- GPT-4 and GPT-3.5 did better than open-source models like Llama and Mistral, both at writing explanations and turning them into logic.
- Swapping in GPT-4 just for the “logic translation” step helped weaker models a lot.
- Human check: Are the refined explanations true and non-trivial?
- Most refined explanations were factually correct (very high rates).
- Only a small number in the science datasets had over-generalizations (e.g., treating all tetrapods as having four limbs, which wrongly includes snakes).
- Explanations usually weren’t trivial (i.e., not just repeating the premise or hypothesis).
Why is this important?
When AIs explain their answers, we want those explanations to be:
- Correct: They actually support the answer.
- Clear: Each step follows logically.
- Checkable: A separate system can verify them.
This paper shows a practical way to achieve that by combining natural language generation (LLMs) with strict logical checking (theorem provers). It also helps clean up human-written explanations in datasets, which are sometimes incomplete or slightly wrong. That means better training data and fairer evaluations of AI reasoning.
What could this change in the future?
This approach can:
- Make AI explanations more reliable in areas like education, science, law, or medicine where correctness matters.
- Help build better benchmarks by automatically fixing noisy human-written explanations.
- Encourage new systems that mix flexible language understanding (neural nets) with precise logic (symbolic tools).
The authors note limitations too:
- The hardest, multi-step explanations still challenge today’s models.
- Better logical consistency doesn’t automatically guarantee overall safety or full correctness in all real-world uses.
- Future work aims to handle more complex explanations with fewer refinement steps, making the process faster and more robust.
In short, Explanation-Refiner is like giving AIs both a good “writer” and a strict “proof-checking teacher,” and letting them work together until the explanation is both easy to read and logically solid.
Collections
Sign up for free to add this paper to one or more collections.