"In-Context Learning" or: How I learned to stop worrying and love "Applied Information Retrieval"
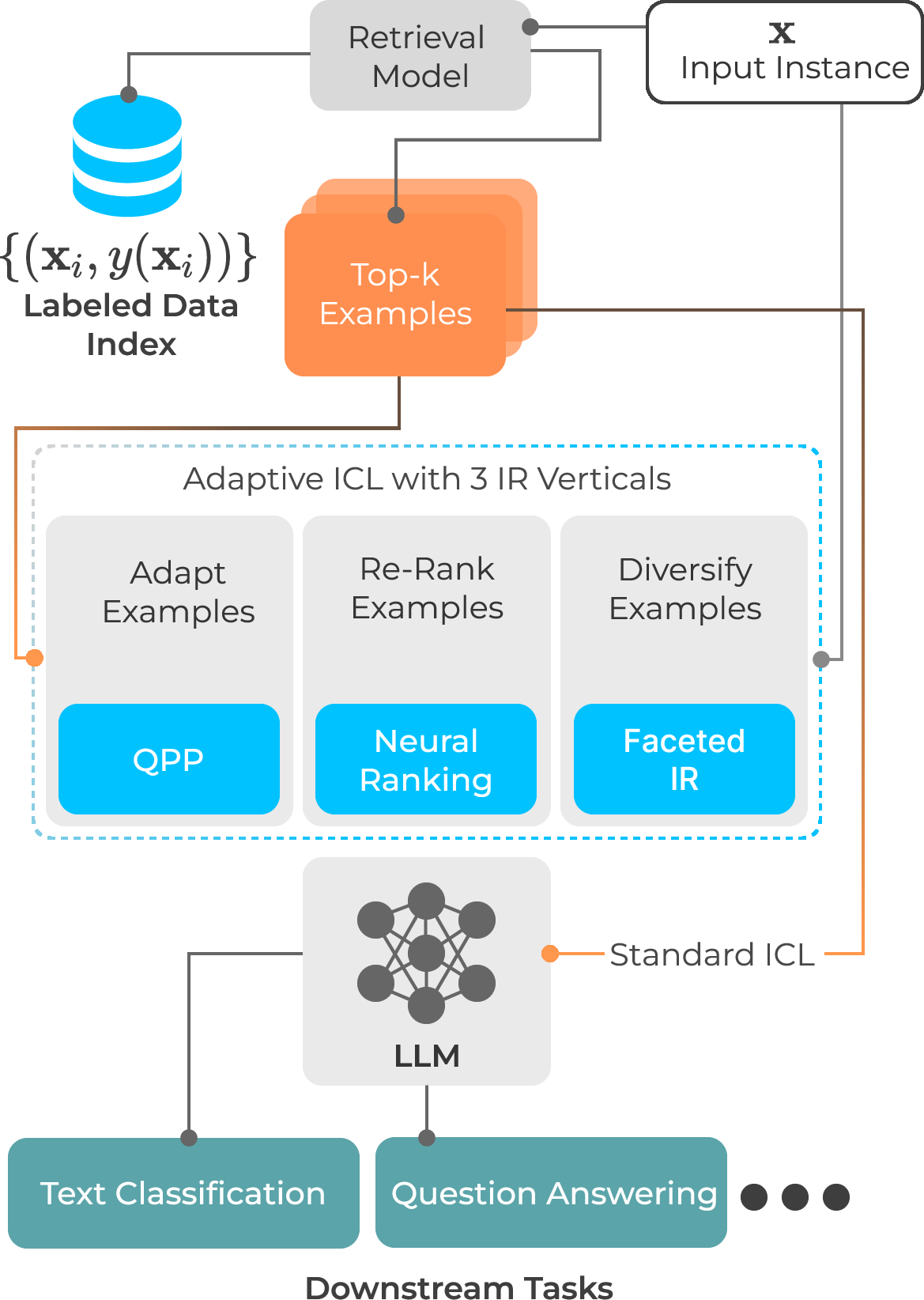
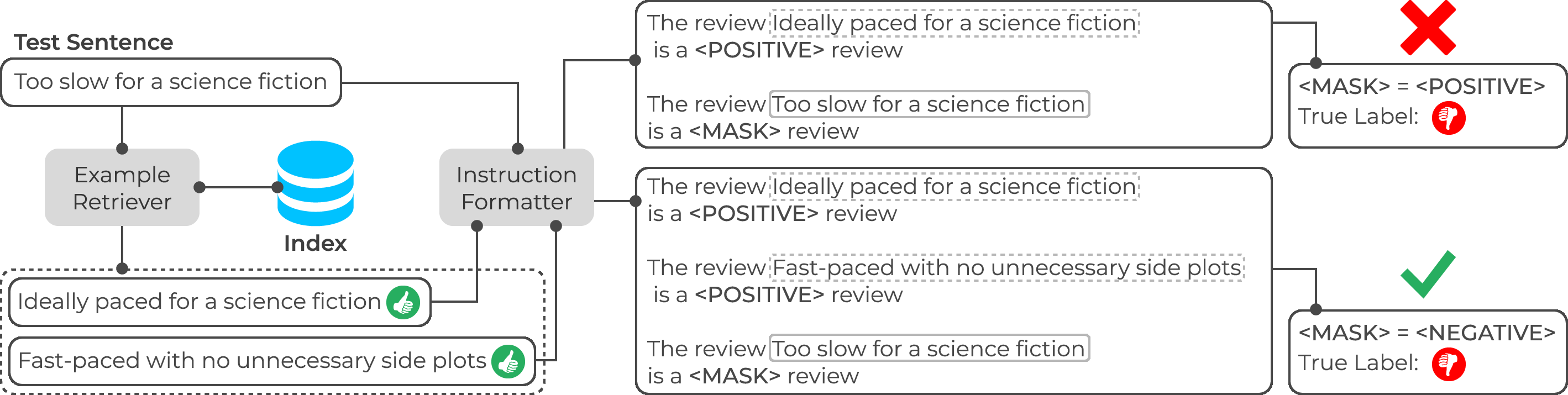
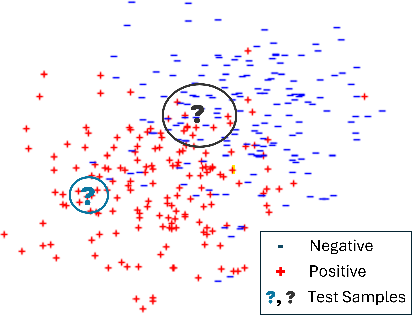
Abstract: With the increasing ability of LLMs, in-context learning (ICL) has evolved as a new paradigm for NLP, where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
- Can Generative LLMs Create Query Variants for Test Collections? An Exploratory Study. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (Taipei, Taiwan) (SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 1869–1873. https://doi.org/10.1145/3539618.3591960
- Where to Stop Reading a Ranked List? Threshold Optimization Using Truncated Score Distributions. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval (Boston, MA, USA) (SIGIR ’09). Association for Computing Machinery, New York, NY, USA, 524–531. https://doi.org/10.1145/1571941.1572031
- Ask Me Anything: A simple strategy for prompting language models. arXiv:2210.02441 [cs.CL]
- Choppy: Cut Transformer for Ranked List Truncation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 1513–1516. https://doi.org/10.1145/3397271.3401188
- Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Overview of the TREC 2014 Session Track. In Proc. of TREC 2014.
- Retrievability based Document Selection for Relevance Feedback with Automatically Generated Query Variants. In CIKM. ACM, 125–134.
- Novelty and diversity in information retrieval evaluation. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (Singapore, Singapore) (SIGIR ’08). Association for Computing Machinery, New York, NY, USA, 659–666. https://doi.org/10.1145/1390334.1390446
- Overview of the TREC 2009 Web Track. In Proceedings of The Eighteenth Text REtrieval Conference, TREC 2009, Gaithersburg, Maryland, USA, November 17-20, 2009 (NIST Special Publication, Vol. 500-278), Ellen M. Voorhees and Lori P. Buckland (Eds.). National Institute of Standards and Technology (NIST). http://trec.nist.gov/pubs/trec18/papers/WEB09.OVERVIEW.pdf
- Predicting Query Performance. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’02). Association for Computing Machinery, New York, NY, USA, 299–306.
- The Power of Noise: Redefining Retrieval for RAG Systems. arXiv:2401.14887 [cs.IR]
- Ronan Cummins. 2014. Document Score Distribution Models for Query Performance Inference and Prediction. ACM Trans. Inf. Syst. 32, 1, Article 2 (2014), 28 pages.
- Zhuyun Dai and Jamie Callan. 2019. Deeper Text Understanding for IR with Contextual Neural Language Modeling. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (Paris, France) (SIGIR’19). Association for Computing Machinery, New York, NY, USA, 985–988. https://doi.org/10.1145/3331184.3331303
- Deep-QPP: A Pairwise Interaction-based Deep Learning Model for Supervised Query Performance Prediction. In WSDM ’22: The Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event / Tempe, AZ, USA, February 21 - 25, 2022, K. Selcuk Candan, Huan Liu, Leman Akoglu, Xin Luna Dong, and Jiliang Tang (Eds.). ACM, 201–209. https://doi.org/10.1145/3488560.3498491
- A Relative Information Gain-based Query Performance Prediction Framework with Generated Query Variants. ACM Trans. Inf. Syst. 41, 2 (2023), 38:1–38:31.
- Ranking a Stream of News. In Proceedings of the 14th International Conference on World Wide Web (Chiba, Japan) (WWW ’05). Association for Computing Machinery, New York, NY, USA, 97–106. https://doi.org/10.1145/1060745.1060764
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. https://doi.org/10.18653/v1/N19-1423
- Fernando Diaz. 2007. Performance Prediction Using Spatial Autocorrelation. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’07). Association for Computing Machinery, New York, NY, USA, 583–590.
- A Survey on In-context Learning. arXiv:2301.00234 [cs.CL]
- A Geometric Framework for Query Performance Prediction in Conversational Search. In Proceedings of 46th international ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2023 July 23–27, 2023, Taipei, Taiwan. ACM. https://doi.org/10.1145/3539618.3591625
- TopicVis: a GUI for topic-based feedback and navigation. In SIGIR. ACM, 1103–1104.
- Debasis Ganguly and Gareth J. F. Jones. 2018. A non-parametric topical relevance model. Inf. Retr. J. 21, 5 (2018), 449–479.
- An LDA-smoothed relevance model for document expansion: a case study for spoken document retrieval. In SIGIR. ACM, 1057–1060.
- Debasis Ganguly and Emine Yilmaz. 2023. Query-specific Variable Depth Pooling via Query Performance Prediction. In SIGIR. ACM, 2303–2307.
- The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv preprint arXiv:2101.00027 (2020).
- Rethink Training of BERT Rerankers in Multi-Stage Retrieval Pipeline. CoRR abs/2101.08751 (2021). arXiv:2101.08751 https://arxiv.org/abs/2101.08751
- Precise Zero-Shot Dense Retrieval without Relevance Labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, 1762–1777. https://doi.org/10.18653/V1/2023.ACL-LONG.99
- SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association for Computational Linguistics, 6894–6910. https://doi.org/10.18653/V1/2021.EMNLP-MAIN.552
- Michael Gutmann and Aapo Hyvärinen. 2010. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 9), Yee Whye Teh and Mike Titterington (Eds.). PMLR, Chia Laguna Resort, Sardinia, Italy, 297–304. https://proceedings.mlr.press/v9/gutmann10a.html
- Improving Efficient Neural Ranking Models with Cross-Architecture Knowledge Distillation. CoRR abs/2010.02666 (2020). arXiv:2010.02666 https://arxiv.org/abs/2010.02666
- Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv preprint arXiv:2108.02035 (2021).
- Gautier Izacard and Edouard Grave. 2021. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, Paola Merlo, Jörg Tiedemann, and Reut Tsarfaty (Eds.). Association for Computational Linguistics, 874–880. https://doi.org/10.18653/V1/2021.EACL-MAIN.74
- Atlas: Few-shot Learning with Retrieval Augmented Language Models. J. Mach. Learn. Res. 24 (2023), 251:1–251:43. http://jmlr.org/papers/v24/23-0037.html
- Mistral 7B. arXiv:2310.06825 [cs.CL]
- Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, 6769–6781. https://doi.org/10.18653/V1/2020.EMNLP-MAIN.550
- Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, Ji-Rong Wen, and Yiqun Liu (Eds.). ACM, 39–48. https://doi.org/10.1145/3397271.3401075
- Diverse Demonstrations Improve In-context Compositional Generalization. arXiv:2212.06800 [cs.CL]
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 7871–7880. https://doi.org/10.18653/v1/2020.acl-main.703
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (Eds.). https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
- An Encoder Attribution Analysis for Dense Passage Retriever in Open-Domain Question Answering. In Proceedings of the 2nd Workshop on Trustworthy Natural Language Processing (TrustNLP 2022). Association for Computational Linguistics, Seattle, U.S.A., 1–11. https://doi.org/10.18653/v1/2022.trustnlp-1.1
- Few-shot In-context Learning on Knowledge Base Question Answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 6966–6980. https://doi.org/10.18653/v1/2023.acl-long.385
- In-Batch Negatives for Knowledge Distillation with Tightly-Coupled Teachers for Dense Retrieval. In Proceedings of the 6th Workshop on Representation Learning for NLP, RepL4NLP@ACL-IJCNLP 2021, Online, August 6, 2021, Anna Rogers, Iacer Calixto, Ivan Vulic, Naomi Saphra, Nora Kassner, Oana-Maria Camburu, Trapit Bansal, and Vered Shwartz (Eds.). Association for Computational Linguistics, 163–173. https://doi.org/10.18653/V1/2021.REPL4NLP-1.17
- What Makes Good In-Context Examples for GPT-3?. In Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, Eneko Agirre, Marianna Apidianaki, and Ivan Vulić (Eds.). Association for Computational Linguistics, Dublin, Ireland and Online, 100–114. https://doi.org/10.18653/v1/2022.deelio-1.10
- RoBERTa: A Robustly Optimized BERT Pretraining Approach. http://arxiv.org/abs/1907.11692
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, Dublin, Ireland, 8086–8098. https://doi.org/10.18653/v1/2022.acl-long.556
- In-context Learning with Retrieved Demonstrations for Language Models: A Survey. arXiv:2401.11624 [cs.CL]
- CEDR: Contextualized Embeddings for Document Ranking. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, July 21-25, 2019, Benjamin Piwowarski, Max Chevalier, Éric Gaussier, Yoelle Maarek, Jian-Yun Nie, and Falk Scholer (Eds.). ACM, 1101–1104. https://doi.org/10.1145/3331184.3331317
- Solution for Information Overload Using Faceted Search–A Review. IEEE Access 8 (2020), 119554–119585. https://doi.org/10.1109/ACCESS.2020.3005536
- Yury A. Malkov and Dmitry A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 42, 4 (2020), 824–836. https://doi.org/10.1109/TPAMI.2018.2889473
- The impact of result diversification on search behaviour and performance. Inf. Retr. J. 22, 5 (2019), 422–446.
- In-Context Learning for Text Classification with Many Labels. In Proceedings of the 1st GenBench Workshop on (Benchmarking) Generalisation in NLP, Dieuwke Hupkes, Verna Dankers, Khuyagbaatar Batsuren, Koustuv Sinha, Amirhossein Kazemnejad, Christos Christodoulopoulos, Ryan Cotterell, and Elia Bruni (Eds.). Association for Computational Linguistics, Singapore, 173–184. https://doi.org/10.18653/v1/2023.genbench-1.14
- Large Language Model Augmented Narrative Driven Recommendations. arXiv:2306.02250 [cs.IR]
- Large Dual Encoders Are Generalizable Retrievers. arXiv:2112.07899 [cs.IR]
- Rodrigo Frassetto Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. CoRR abs/1901.04085 (2019). arXiv:1901.04085 http://arxiv.org/abs/1901.04085
- Document Ranking with a Pretrained Sequence-to-Sequence Model. In Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020 (Findings of ACL, Vol. EMNLP 2020), Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, 708–718. https://doi.org/10.18653/V1/2020.FINDINGS-EMNLP.63
- Harrie Oosterhuis. 2021. Computationally Efficient Optimization of Plackett-Luce Ranking Models for Relevance and Fairness. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (, Virtual Event, Canada,) (SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 1023–1032. https://doi.org/10.1145/3404835.3462830
- OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
- Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 27730–27744. https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf
- Vern I. Paulsen and Mrinal Raghupathi. 2016. An Introduction to the Theory of Reproducing Kernel Hilbert Spaces. Cambridge University Press.
- How Does Generative Retrieval Scale to Millions of Passages? arXiv:2305.11841 [cs.IR]
- RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze! CoRR abs/2312.02724 (2023). https://doi.org/10.48550/ARXIV.2312.02724 arXiv:2312.02724
- Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084 [cs.CL]
- Query Performance Prediction for Multifield Document Retrieval. In Proceedings of the 2020 ACM SIGIR on International Conference on Theory of Information Retrieval (Virtual Event, Norway) (ICTIR ’20). Association for Computing Machinery, New York, NY, USA, 49–52. https://doi.org/10.1145/3409256.3409821
- Estimating Gaussian mixture models in the local neighbourhood of embedded word vectors for query performance prediction. Information Processing and Management 56, 3 (2019), 1026 – 1045.
- Learning To Retrieve Prompts for In-Context Learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz (Eds.). Association for Computational Linguistics, Seattle, United States, 2655–2671. https://doi.org/10.18653/v1/2022.naacl-main.191
- Exploiting query reformulations for web search result diversification. In Proceedings of the 19th International Conference on World Wide Web (Raleigh, North Carolina, USA) (WWW ’10). Association for Computing Machinery, New York, NY, USA, 881–890. https://doi.org/10.1145/1772690.1772780
- Timo Schick and Hinrich Schütze. 2021. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty (Eds.). Association for Computational Linguistics, Online, 255–269. https://doi.org/10.18653/v1/2021.eacl-main.20
- Measuring and Comparing the Consistency of IR Models for Query Pairs with Similar and Different Information Needs. In CIKM. ACM, 4449–4453.
- LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/pdf?id=PfpEtB3-csK
- Predicting Query Performance by Query-Drift Estimation. ACM Trans. Inf. Syst. 30, 2, Article 11 (2012), 35 pages.
- Unsupervised Query Performance Prediction for Neural Models with Pairwise Rank Preferences. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 23-27, 2023, Hsin-Hsi Chen, Wei-Jou (Edward) Duh, Hen-Hsen Huang, Makoto P. Kato, Josiane Mothe, and Barbara Poblete (Eds.). ACM, 2486–2490. https://doi.org/10.1145/3539618.3592082
- Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Seattle, Washington, USA, 1631–1642. https://aclanthology.org/D13-1170
- An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, Dublin, Ireland, 819–862. https://doi.org/10.18653/v1/2022.acl-long.60
- RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864 [cs.CL]
- Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, 14918–14937. https://aclanthology.org/2023.emnlp-main.923
- In-context Learning of Large Language Models for Controlled Dialogue Summarization: A Holistic Benchmark and Empirical Analysis. In Proceedings of the 4th New Frontiers in Summarization Workshop, Yue Dong, Wen Xiao, Lu Wang, Fei Liu, and Giuseppe Carenini (Eds.). Association for Computational Linguistics, Singapore, 56–67. https://doi.org/10.18653/v1/2023.newsum-1.6
- Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288 [cs.CL]
- Aspect-based academic search using domain-specific KB. In Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, April 14–17, 2020, Proceedings, Part II 42. Springer, 418–424.
- Ben Wang. 2021. Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX. https://github.com/kingoflolz/mesh-transformer-jax.
- Ben Wang and Aran Komatsuzaki. 2022. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model, 2021.
- Query2doc: Query Expansion with Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 9414–9423. https://doi.org/10.18653/v1/2023.emnlp-main.585
- RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, 538–548. https://doi.org/10.18653/V1/2022.EMNLP-MAIN.35
- Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=zeFrfgyZln
- Information Needs, Queries, and Query Performance Prediction. In Proc. of SIGIR ’19. Association for Computing Machinery, New York, NY, USA, 395–404.
- Learning k for KNN Classification. 8, 3, Article 43 (jan 2017), 19 pages. https://doi.org/10.1145/2990508
- Yun Zhou and W. Bruce Croft. 2007. Query Performance Prediction in Web Search Environments. In Proc. 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’07). Association for Computing Machinery, New York, NY, USA, 543–550.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.