General Purpose Verification for Chain of Thought Prompting
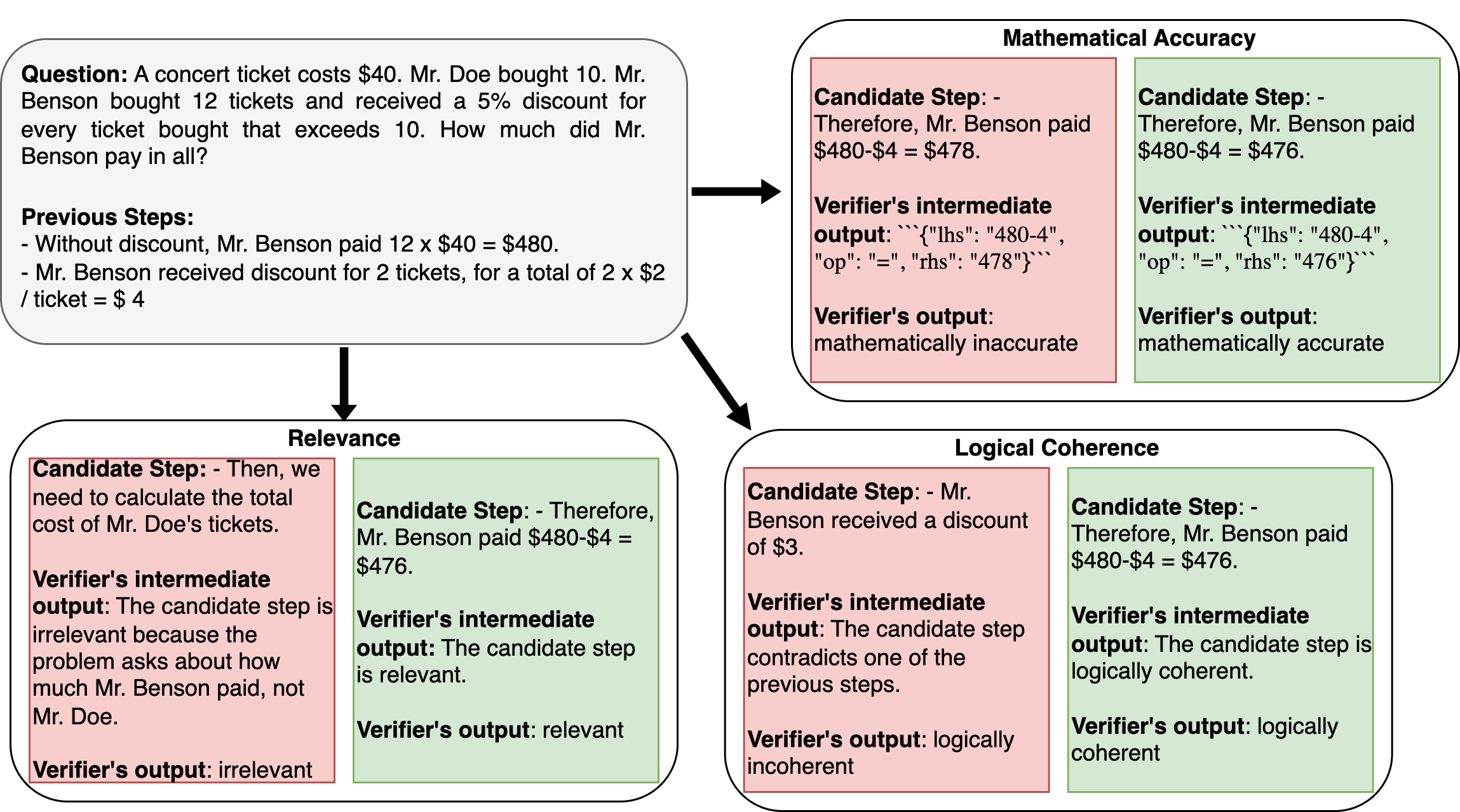
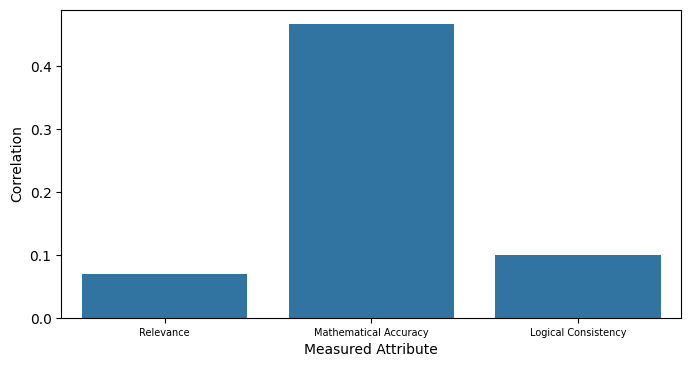
Abstract: Many of the recent capabilities demonstrated by LLMs arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
- Towards a human-like open-domain chatbot.
- The falcon series of open language models. ArXiv, abs/2311.16867.
- Constitutional ai: Harmlessness from ai feedback.
- BIG bench authors. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research.
- Graph of thoughts: Solving elaborate problems with large language models.
- Language models are few-shot learners. ArXiv, abs/2005.14165.
- Sparks of artificial general intelligence: Early experiments with gpt-4. ArXiv, abs/2303.12712.
- Teaching large language models to self-debug. ArXiv, abs/2304.05128.
- Palm: Scaling language modeling with pathways. J. Mach. Learn. Res., 24:240:1–240:113.
- Training verifiers to solve math word problems. ArXiv, abs/2110.14168.
- Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346–361.
- Demystifying prompts in language models via perplexity estimation. ArXiv, abs/2212.04037.
- Is your toxicity my toxicity? exploring the impact of rater identity on toxicity annotation. Proceedings of the ACM on Human-Computer Interaction, 6:1 – 28.
- Think before you speak: Training language models with pause tokens. ArXiv, abs/2310.02226.
- Reasoning with language model is planning with world model. ArXiv, abs/2305.14992.
- Large language models cannot self-correct reasoning yet. ArXiv, abs/2310.01798.
- Large language models are zero-shot reasoners. ArXiv, abs/2205.11916.
- Making language models better reasoners with step-aware verifier. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5315–5333, Toronto, Canada. Association for Computational Linguistics.
- Jieyi Long. 2023. Large language model guided tree-of-thought. ArXiv, abs/2305.08291.
- E. A. M. and Richard Mckeon. 1941. The basic works of aristotle.
- Self-refine: Iterative refinement with self-feedback. ArXiv, abs/2303.17651.
- Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. ArXiv, abs/2305.15852.
- Show your work: Scratchpads for intermediate computation with language models. ArXiv, abs/2112.00114.
- OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
- Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies. ArXiv, abs/2308.03188.
- Are NLP models really able to solve simple math word problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094, Online. Association for Computational Linguistics.
- Self-critiquing models for assisting human evaluators. ArXiv, abs/2206.05802.
- Toolformer: Language models can teach themselves to use tools. ArXiv, abs/2302.04761.
- Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning.
- Reflexion: Language agents with verbal reinforcement learning.
- CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
- Commonsenseqa 2.0: Exposing the limits of ai through gamification. ArXiv, abs/2201.05320.
- Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971.
- Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. ArXiv, abs/2305.04388.
- Solving math word problems with process- and outcome-based feedback. ArXiv, abs/2211.14275.
- Self-consistency improves chain of thought reasoning in language models. ArXiv, abs/2203.11171.
- Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. ArXiv, abs/2302.01560.
- Chain of thought prompting elicits reasoning in large language models. ArXiv, abs/2201.11903.
- Self-evaluation guided beam search for reasoning.
- Tree of thoughts: Deliberate problem solving with large language models. ArXiv, abs/2305.10601.
- React: Synergizing reasoning and acting in language models. ArXiv, abs/2210.03629.
- Do large language models know what they don’t know? In Annual Meeting of the Association for Computational Linguistics.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.