KAN: Kolmogorov-Arnold Networks
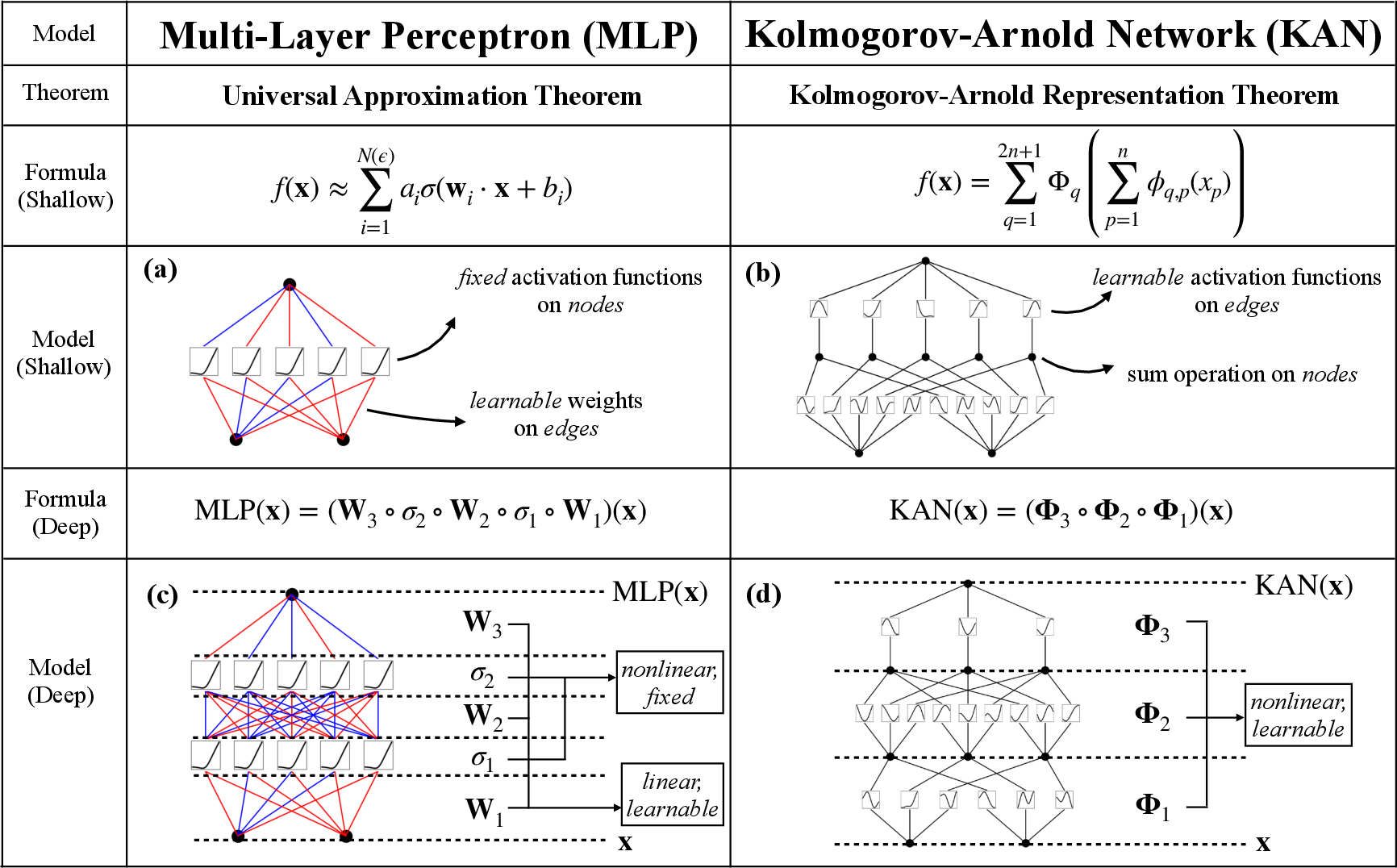
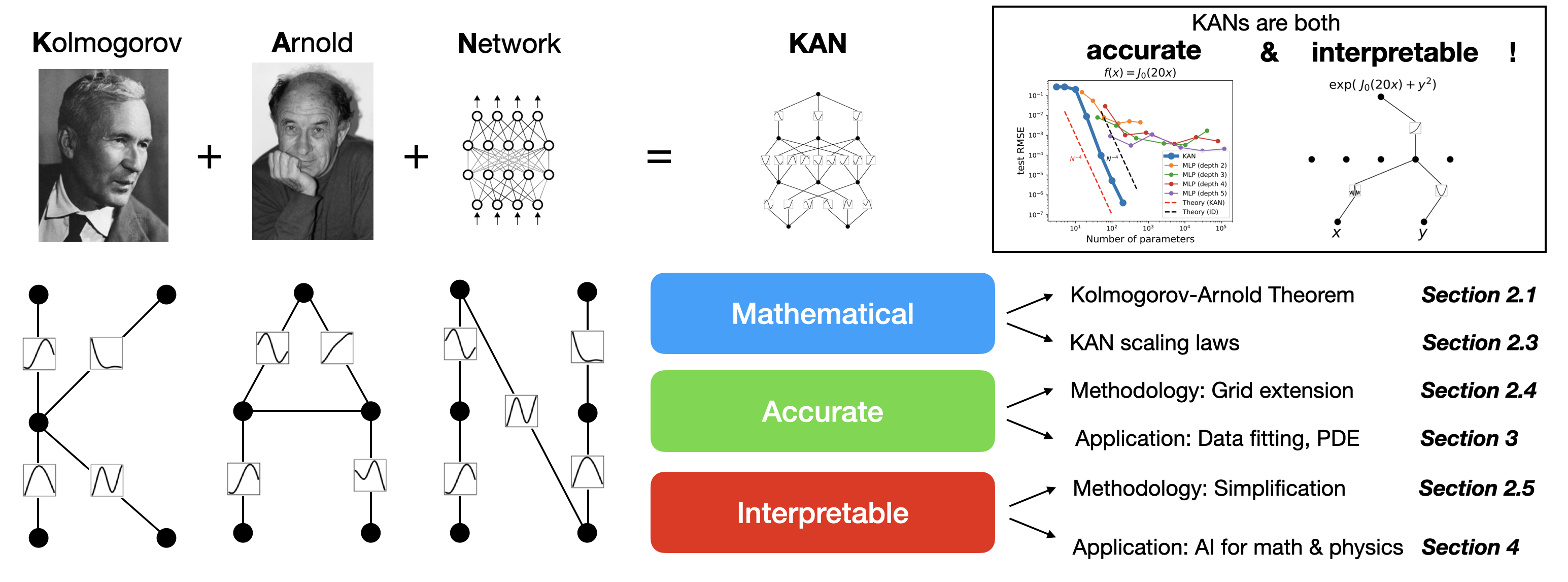
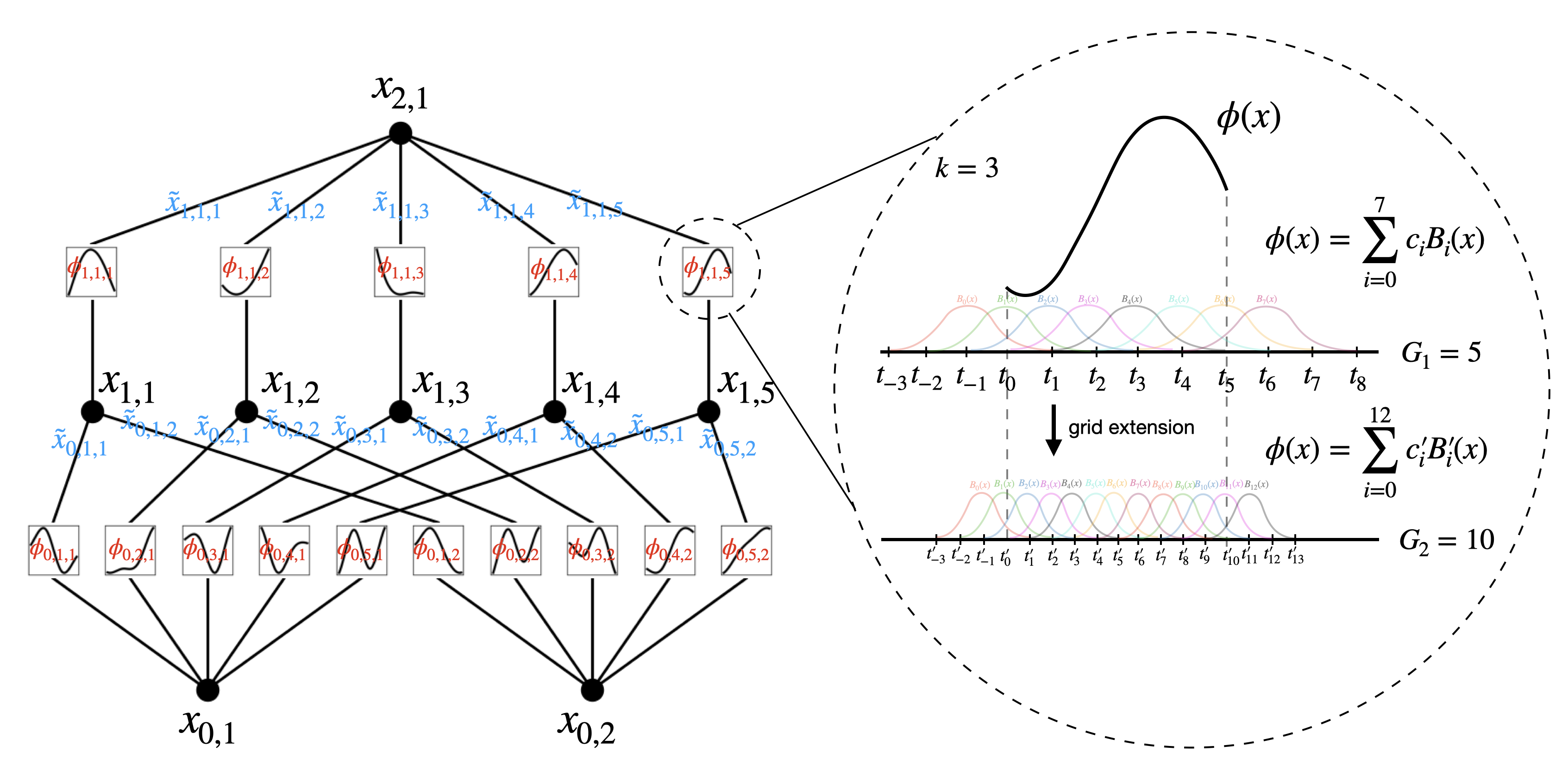
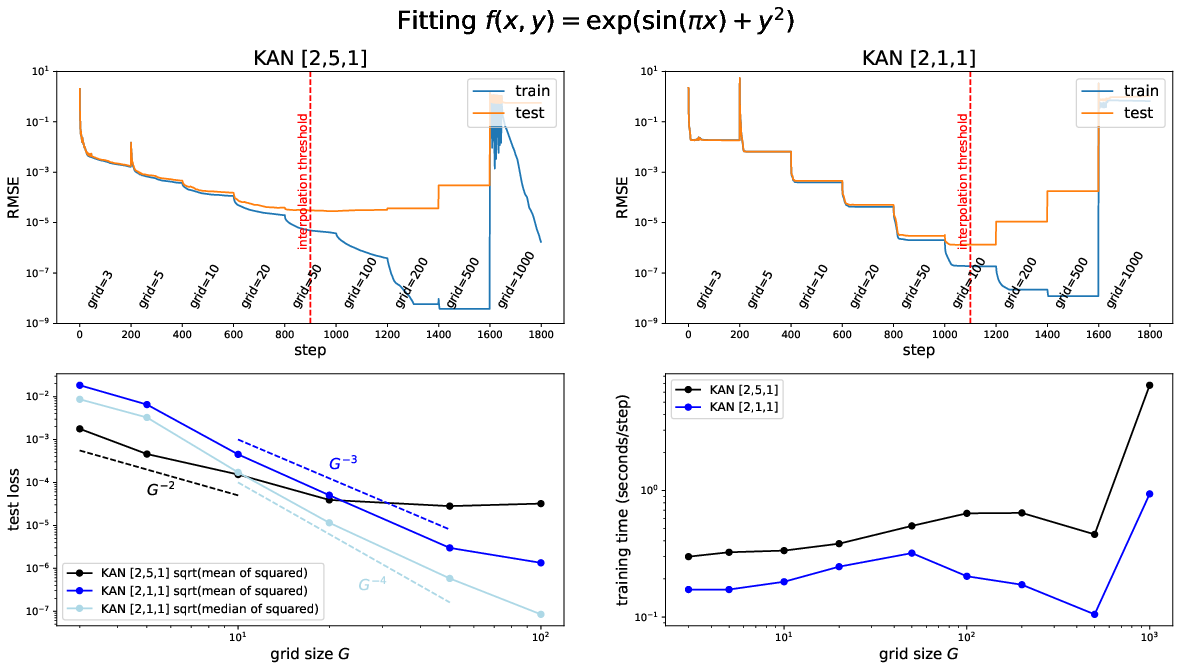
Abstract: Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
- Simon Haykin. Neural networks: a comprehensive foundation. Prentice Hall PTR, 1994.
- George Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of control, signals and systems, 2(4):303–314, 1989.
- Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600, 2023.
- A.N. Kolmogorov. On the representation of continuous functions of several variables as superpositions of continuous functions of a smaller number of variables. Dokl. Akad. Nauk, 108(2), 1956.
- On a constructive proof of kolmogorov’s superposition theorem. Constructive approximation, 30:653–675, 2009.
- Space-filling curves and kolmogorov superposition-based neural networks. Neural Networks, 15(1):57–67, 2002.
- Mario Köppen. On the training of a kolmogorov network. In Artificial Neural Networks—ICANN 2002: International Conference Madrid, Spain, August 28–30, 2002 Proceedings 12, pages 474–479. Springer, 2002.
- On the realization of a kolmogorov network. Neural Computation, 5(1):18–20, 1993.
- The kolmogorov superposition theorem can break the curse of dimensionality when approximating high dimensional functions. arXiv preprint arXiv:2112.09963, 2021.
- The kolmogorov spline network for image processing. In Image Processing: Concepts, Methodologies, Tools, and Applications, pages 54–78. IGI Global, 2013.
- Exsplinet: An interpretable and expressive spline-based neural network. Neural Networks, 152:332–346, 2022.
- Theoretical issues in deep networks. Proceedings of the National Academy of Sciences, 117(48):30039–30045, 2020.
- Why does deep and cheap learning work so well? Journal of Statistical Physics, 168:1223–1247, 2017.
- Nonlinear material design using principal stretches. ACM Transactions on Graphics (TOG), 34(4):1–11, 2015.
- A neural scaling law from the dimension of the data manifold. arXiv preprint arXiv:2004.10802, 2020.
- Precision machine learning. Entropy, 25(1):175, 2023.
- A practical guide to splines, volume 27. springer-verlag New York, 1978.
- Ai feynman: A physics-inspired method for symbolic regression. Science Advances, 6(16):eaay2631, 2020.
- Ai feynman 2.0: Pareto-optimal symbolic regression exploiting graph modularity. Advances in Neural Information Processing Systems, 33:4860–4871, 2020.
- Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378:686–707, 2019.
- Physics-informed machine learning. Nature Reviews Physics, 3(6):422–440, 2021.
- Measuring catastrophic forgetting in neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- Brain plasticity and behavior. Annual review of psychology, 49(1):43–64, 1998.
- Modular and hierarchically modular organization of brain networks. Frontiers in neuroscience, 4:7572, 2010.
- Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- Revisiting neural networks for continual learning: An architectural perspective, 2024.
- Advancing mathematics by guiding human intuition with ai. Nature, 600(7887):70–74, 2021.
- Searching for ribbons with machine learning, 2023.
- P. Petersen. Riemannian Geometry. Graduate Texts in Mathematics. Springer New York, 2006.
- Philip W Anderson. Absence of diffusion in certain random lattices. Physical review, 109(5):1492, 1958.
- David J Thouless. A relation between the density of states and range of localization for one dimensional random systems. Journal of Physics C: Solid State Physics, 5(1):77, 1972.
- Scaling theory of localization: Absence of quantum diffusion in two dimensions. Physical Review Letters, 42(10):673, 1979.
- Fifty years of anderson localization. Physics today, 62(8):24–29, 2009.
- Anderson localization of light. Nature Photonics, 7(3):197–204, 2013.
- Optics of photonic quasicrystals. Nature photonics, 7(3):177–187, 2013.
- Sajeev John. Strong localization of photons in certain disordered dielectric superlattices. Physical review letters, 58(23):2486, 1987.
- Observation of a localization transition in quasiperiodic photonic lattices. Physical review letters, 103(1):013901, 2009.
- Reentrant delocalization transition in one-dimensional photonic quasicrystals. Physical Review Research, 5(3):033170, 2023.
- Absence of many-body mobility edges. Physical Review B, 93(1):014203, 2016.
- Many-body localization and quantum nonergodicity in a model with a single-particle mobility edge. Physical review letters, 115(18):186601, 2015.
- Interactions and mobility edges: Observing the generalized aubry-andré model. Physical review letters, 126(4):040603, 2021.
- J Biddle and S Das Sarma. Predicted mobility edges in one-dimensional incommensurate optical lattices: An exactly solvable model of anderson localization. Physical review letters, 104(7):070601, 2010.
- Self-consistent theory of mobility edges in quasiperiodic chains. Physical Review B, 103(6):L060201, 2021.
- Nearest neighbor tight binding models with an exact mobility edge in one dimension. Physical review letters, 114(14):146601, 2015.
- One-dimensional quasiperiodic mosaic lattice with exact mobility edges. Physical Review Letters, 125(19):196604, 2020.
- Duality between two generalized aubry-andré models with exact mobility edges. Physical Review B, 103(17):174205, 2021.
- Exact new mobility edges between critical and localized states. Physical Review Letters, 131(17):176401, 2023.
- Tomaso Poggio. How deep sparse networks avoid the curse of dimensionality: Efficiently computable functions are compositionally sparse. CBMM Memo, 10:2022, 2022.
- Johannes Schmidt-Hieber. The kolmogorov–arnold representation theorem revisited. Neural networks, 137:119–126, 2021.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701, 2020.
- Data and parameter scaling laws for neural machine translation. In ACL Rolling Review - May 2021, 2021.
- Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
- Explaining neural scaling laws. arXiv preprint arXiv:2102.06701, 2021.
- The quantization model of neural scaling. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- A resource model for neural scaling law. arXiv preprint arXiv:2402.05164, 2024.
- In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022.
- Locating and editing factual associations in gpt. Advances in Neural Information Processing Systems, 35:17359–17372, 2022.
- Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations, 2023.
- Toy models of superposition. arXiv preprint arXiv:2209.10652, 2022.
- Progress measures for grokking via mechanistic interpretability. In The Eleventh International Conference on Learning Representations, 2023.
- The clock and the pizza: Two stories in mechanistic explanation of neural networks. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Seeing is believing: Brain-inspired modular training for mechanistic interpretability. Entropy, 26(1):41, 2023.
- Softmax linear units. Transformer Circuits Thread, 2022. https://transformer-circuits.pub/2022/solu/index.html.
- Learning activation functions: A new paradigm for understanding neural networks. arXiv preprint arXiv:1906.09529, 2019.
- Searching for activation functions. arXiv preprint arXiv:1710.05941, 2017.
- Neural network architecture beyond width and depth. Advances in Neural Information Processing Systems, 35:5669–5681, 2022.
- Discovering parametric activation functions. Neural Networks, 148:48–65, 2022.
- Learning activation functions in deep (spline) neural networks. IEEE Open Journal of Signal Processing, 1:295–309, 2020.
- Deep spline networks with control of lipschitz regularity. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3242–3246. IEEE, 2019.
- Renáta Dubcáková. Eureqa: software review. Genetic Programming and Evolvable Machines, 12:173–178, 2011.
- Gplearn. https://github.com/trevorstephens/gplearn. Accessed: 2024-04-19.
- Miles Cranmer. Interpretable machine learning for science with pysr and symbolicregression. jl. arXiv preprint arXiv:2305.01582, 2023.
- Extrapolation and learning equations. arXiv preprint arXiv:1610.02995, 2016.
- Occamnet: A fast neural model for symbolic regression at scale. arXiv preprint arXiv:2007.10784, 2020.
- Symbolic regression via deep reinforcement learning enhanced genetic programming seeding. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021.
- Bing Yu et al. The deep ritz method: a deep learning-based numerical algorithm for solving variational problems. Communications in Mathematics and Statistics, 6(1):1–12, 2018.
- Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895, 2020.
- Physics-informed neural operator for learning partial differential equations. ACM/JMS Journal of Data Science, 2021.
- Neural operator: Learning maps between function spaces with applications to pdes. Journal of Machine Learning Research, 24(89):1–97, 2023.
- Fourier continuation for exact derivative computation in physics-informed neural operators. arXiv preprint arXiv:2211.15960, 2022.
- Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021.
- Learning to Unknot. Mach. Learn. Sci. Tech., 2(2):025035, 2021.
- Rectangular knot diagrams classification with deep learning, 2020.
- Mark C Hughes. A neural network approach to predicting and computing knot invariants. Journal of Knot Theory and Its Ramifications, 29(03):2050005, 2020.
- Disentangling a deep learned volume formula. JHEP, 06:040, 2021.
- Illuminating new and known relations between knot invariants. 11 2022.
- Fabian Ruehle. Data science applications to string theory. Phys. Rept., 839:1–117, 2020.
- Y.H. He. Machine Learning in Pure Mathematics and Theoretical Physics. G - Reference,Information and Interdisciplinary Subjects Series. World Scientific, 2023.
- Rigor with machine learning from field theory to the poincaréconjecture. Nature Reviews Physics, 2024.
- Multiscale invertible generative networks for high-dimensional bayesian inference. In International Conference on Machine Learning, pages 12632–12641. PMLR, 2021.
- Algebraic multigrid methods. Acta Numerica, 26:591–721, 2017.
- Exponentially convergent multiscale finite element method. Communications on Applied Mathematics and Computation, pages 1–17, 2023.
- Implicit neural representations with periodic activation functions. Advances in neural information processing systems, 33:7462–7473, 2020.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.