- The paper presents TSER, a novel oversampling approach that reshapes time series forecasting as an imbalanced learning task.
- It employs techniques like SMOTE to generate synthetic samples, enhancing the accuracy of global models on underrepresented series.
- Experimental validation on 5502 series from seven databases demonstrates a strong trade-off between local and global model benefits.
Evaluation of "Time Series Data Augmentation as an Imbalanced Learning Problem" (2404.18537)
This essay provides an authoritative analysis of the paper titled "Time Series Data Augmentation as an Imbalanced Learning Problem" authored by Cerqueira et al. The research addresses a challenging aspect of time series forecasting by leveraging data augmentation techniques within the framework of imbalanced learning. The main contribution lies in the development of the Time Series Entity Resampler (TSER) method, which extends the applicability of global models to accurately capture nuances in data-limited forecasting settings.
Introduction and Motivation
Forecasting univariate time series using global models leverages patterns across various series to enhance predictive performance. Despite their advantages, global models may require significant data volumes, and sometimes fail to encapsulate series-specific trends. The study from Cerqueira et al. contends with these limitations by framing the training of forecasting models as an imbalanced learning task. The proposition is to use oversampling techniques to generate synthetic samples that compensate for data shortfall, thereby aligning with imbalanced learning's emphasis on skewed data distribution.
Methodology
The core innovation, TSER, hinges on employing an oversampling mechanism to generate synthetic data samples for specific, underrepresented series within a collection. By framing the problem through an imbalanced-domain learning lens, as typically handled with techniques like SMOTE, the authors propose to adjust the sample distribution favorably towards a time series of interest. This mitigation seeks a balance between local model advantages—sensitivity to individual series—and the data efficiency of global models.
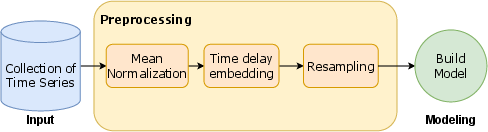
Figure 1: Workflow behind TSER. The collection of time series is transformed for supervised learning using mean normalization and time delay embedding. New synthetic samples are created using oversampling. The resulting dataset is used to build a model.
Experimental Validation
Experiments encompassed 5502 univariate time series from seven distinct databases, examining TSER's efficacy against established global and local forecasting baseline models. When TSER applied oversampling techniques like SMOTE or ADASYN, it consistently outperformed the baseline models, displaying superior trade-off between local and global model characteristics.
The experiments underscored that while TSER generated significant improvements for the target series, the potential downside is diminished performance on non-target series. The resampling strategy was pivotal, with oversampling exhibiting the most substantial gains, contrasting with less favorable results from undersampling approaches.
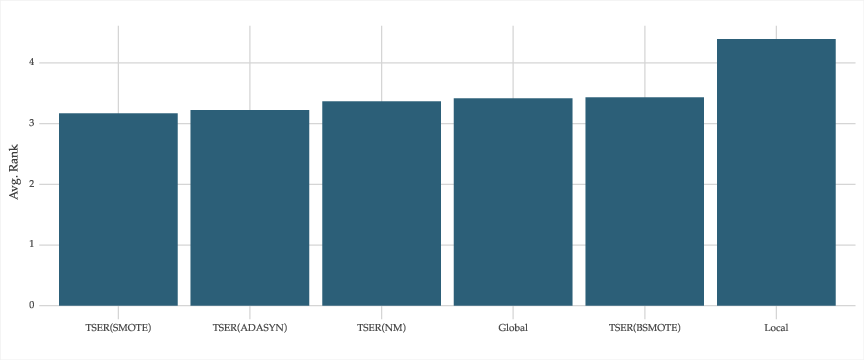
Figure 2: Average rank of each method across all time series.
Implications and Future Work
TSER's approach opens new vistas for forecasting applications wherein data imbalances are prevalent. It offers a pragmatic solution by equipping researchers and practitioners with methods to enhance forecasting accuracy without forgoing the utility of global models. However, the model's tailored nature implies a need for individual series training, which could introduce computational complexities. Future research could aim to adapt TSER for broader applicability, reducing computational demands, and enhancing model generalization across series.
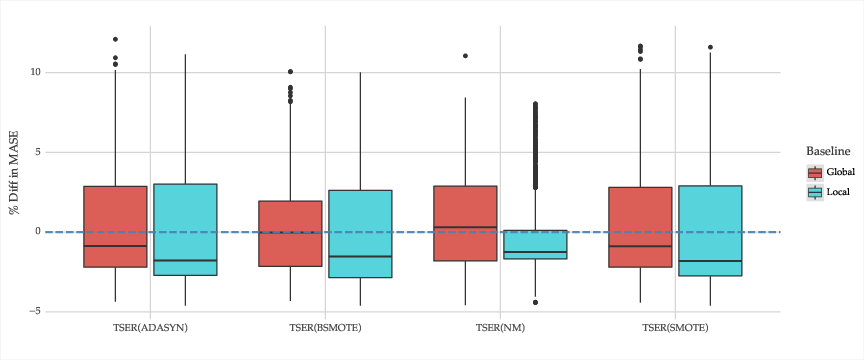
Figure 3: Percentage difference in MASE between the respective method and each reference approach across all time series. Negative values denote better performance by the respective method.
Conclusion
The research by Cerqueira et al. represents a thoughtful integration of imbalanced learning principles with time series forecasting, resolving key data limitations inherent in global model applications. TSER not only elevates individual series forecasting accuracy but also prompts future exploration into efficient data augmentation techniques within imbalanced datasets, thus bolstering AI's capability to handle diverse real-world forecasting challenges.

